Xây dựng tìm kiếm nhận biết ngữ cảnh trong Python với LLM Embeddings + Metadata
Tìm kiếm theo từ khóa sẽ bị gián đoạn ngay khi người dùng nhập một nội dung không được đề cập chính xác trong tài liệu.
Xây dựng công cụ tìm kiếm theo ngữ cảnh trong Python với LLM Embeddings + Metadata
Bởi Bala Priya C vào ngày 22/5/2026 trong Language Models 0
Chia sẻ
Đăng
Chia sẻ
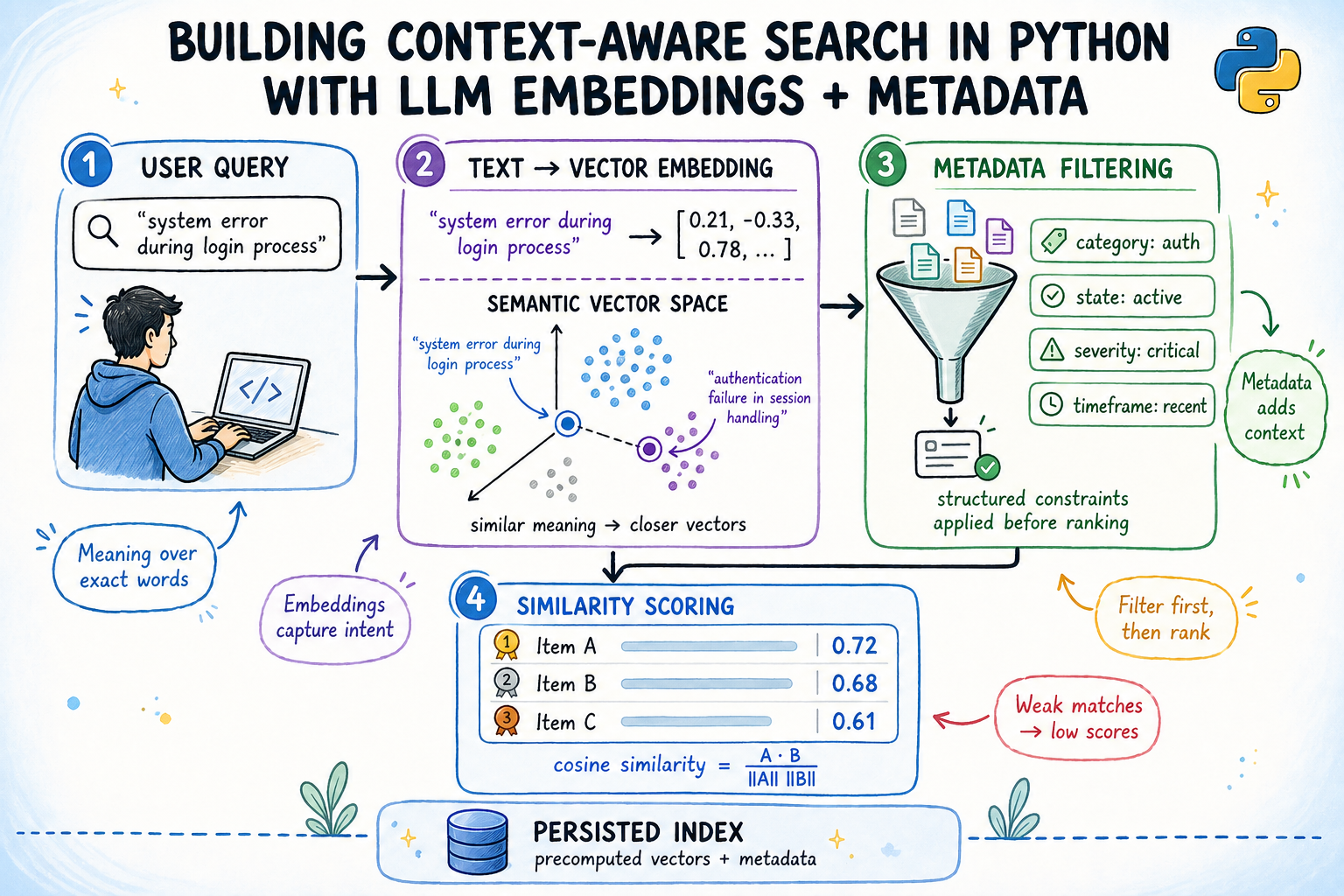
Trong bài viết này, độc giả sẽ tìm hiểu cách xây dựng một công cụ tìm kiếm ngữ nghĩa theo ngữ cảnh trong Python, kết hợp độ tương đồng dựa trên embedding với tính năng lọc siêu dữ liệu có cấu trúc.
Các chủ đề sẽ được đề cập bao gồm:
Cách thức hoạt động của sentence embeddings và cosine similarity để tìm các tài liệu có liên quan về mặt ngữ nghĩa.
Cách xây dựng một chỉ mục tìm kiếm nhận biết siêu dữ liệu, lọc theo nhóm, trạng thái, mức độ ưu tiên và ngày tháng trước khi chấm điểm các ứng viên.
Cách lưu trữ chỉ mục vào đĩa để các embedding chỉ được tính toán một lần và tải lại hiệu quả trong các lần chạy tiếp theo.
Xây dựng công cụ tìm kiếm theo ngữ cảnh trong Python với LLM Embeddings + Metadata
Giới thiệu
Tìm kiếm bằng từ khóa sẽ không hiệu quả khi người dùng nhập một cụm từ mà tài liệu không chứa chính xác. Một kỹ sư hỗ trợ tìm kiếm "login keeps failing" (đăng nhập liên tục thất bại) sẽ không tìm thấy một phiếu yêu cầu có tiêu đề "OAuth2 token refresh race condition" (điều kiện tranh chấp làm mới token OAuth2), mặc dù đó chính xác là điều họ cần. Đây là vấn đề cốt lõi mà tìm kiếm ngữ nghĩa theo ngữ cảnh hướng tới giải quyết.
Tìm kiếm ngữ nghĩa giải quyết vấn đề này bằng cách chuyển đổi văn bản thành các biểu diễn vector dày đặc được gọi là embeddings, trong đó ý nghĩa quyết định sự gần gũi thay vì sự trùng lặp từ chính xác. Thêm các bộ lọc siêu dữ liệu có cấu trúc – theo ngày, trạng thái, nhóm, mức độ ưu tiên – và độc giả sẽ có một hệ thống hiểu được điều người dùng đang hỏi, đồng thời tôn trọng các ràng buộc ngữ cảnh.
Bài viết này sẽ hướng dẫn xây dựng hệ thống đó từ đầu đến cuối: embeddings từ một mô hình được đào tạo trước cục bộ, một chỉ mục nhận biết siêu dữ liệu, xếp hạng cosine similarity và một chỉ mục duy trì qua các lần khởi động lại mà không yêu cầu mã hóa lại.
Độc giả có thể lấy mã nguồn trên GitHub.
Những gì độc giả sẽ xây dựng
Một công cụ tìm kiếm theo ngữ cảnh đơn giản trên một kho dữ liệu các phiếu hỗ trợ kỹ thuật. Đến cuối bài viết, độc giả sẽ có:
Các embedding 384 chiều được tạo cục bộ từ một mô hình được đào tạo trước, không yêu cầu khóa API.
Một chỉ mục tìm kiếm lọc theo nhóm, trạng thái, mức độ ưu tiên và ngày tháng trước khi chấm điểm.
Xếp hạng cosine similarity trên nhóm ứng viên đã lọc.
Một chỉ mục được lưu trữ và tải lại mà không cần mã hóa lại.
Điều kiện tiên quyết: Python 3.8+, kiến thức cơ bản về NumPy và làm việc với danh sách các từ điển.
Cài đặt các thư viện cần thiết:
```
pip install sentence-transformers numpy
```
Hiểu cách hoạt động của tìm kiếm ngữ nghĩa
Một mô hình sentence embedding nhận một chuỗi và trả về một vector số thực có độ dài cố định. Mô hình được huấn luyện sao cho các câu có ý nghĩa tương tự sẽ tạo ra các vector chỉ theo các hướng tương tự trong không gian đa chiều.
Cosine similarity đo góc giữa hai vector:
\[
\text{cosine similarity}(A, B) =
\frac{A \cdot B}{\|A\| \, \|B\|}
\]
Khi các vector được chuẩn hóa đơn vị – nghĩa là độ dài của chúng bằng 1.0 – điều này đơn giản hóa thành tích vô hướng: A · B. Điểm số dao động từ -1 (ngược chiều) đến 1 (giống hệt). Trong thực tế, các tài liệu không liên quan có điểm số khoảng 0.1–0.25, và các tài liệu khớp mạnh có điểm số trên 0.6.
Vậy tại sao việc lọc siêu dữ liệu lại quan trọng? Các mô hình embedding mã hóa nội dung ngữ nghĩa. Chúng không mã hóa người đã viết tài liệu, nhóm nào sở hữu tài liệu hoặc thời điểm tài liệu được tạo. Các thuộc tính này nằm ngoài văn bản và phải được xử lý riêng. Kết hợp cả hai tín hiệu – điểm ngữ nghĩa và các ràng buộc siêu dữ liệu – là điều làm cho tìm kiếm trở nên hữu ích trong các hệ thống thực tế.
Thiết lập tập dữ liệu
Chúng tôi sẽ làm việc với 20 phiếu hỗ trợ kỹ thuật từ ba nhóm – hạ tầng, backend và frontend – với bốn cấp độ ưu tiên, hai trạng thái và khung thời gian hai tháng.
Mỗi phiếu là một từ điển đơn giản. Trường "text" là nội dung được nhúng; mọi trường khác là siêu dữ liệu để lọc.
Để giữ cho nội dung ngắn gọn, một danh sách rút gọn được hiển thị ở đây thay vì toàn bộ khối mã. Toàn bộ tập hợp các phiếu có sẵn trong GitHub gist này.
```
from datetime import date
tickets = [
{"id": "T-101", "team": "infrastructure", "status": "open", "priority": "high",
"created": date(2025, 11, 3),
"text": "Kubernetes pod keeps crashing with OOMKilled — memory limits on the ML inference container are set too low for the model it loads at runtime."},
{"id": "T-102", "team": "infrastructure", "status": "open", "priority": "high",
"created": date(2025, 11, 8),
"text": "Nginx ingress returning 502 after rotating TLS certificate. Chain is valid per openssl verify but the backend handshake fails immediately."},
{"id": "T-103", "team": "infrastructure", "status": "resolved", "priority": "medium",
"created": date(2025, 10, 14),
"text": "Terraform state file locked in S3 — a team member force-applied a plan without releasing the DynamoDB lock first."},
...
{"id": "T-401", "team": "infrastructure", "status": "open", "priority": "medium",
"created": date(2025, 11, 11),
"text": "CI pipeline fails on ARM64 runners — base Docker image has no ARM variant, exec format error at build stage."},
{"id": "T-402", "team": "infrastructure", "status": "resolved", "priority": "high",
"created": date(2025, 10, 9),
"text": "VPN gateway latency spikes at peak hours — BGP route flapping between two peers causing intermittent packet loss across the private subnet."},
]
```

Nguồn tin: Machine Learning Mastery — Tác giả: Bala Priya C. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.