Xây dựng tìm kiếm ngữ nghĩa với Transformers.js và nhúng câu
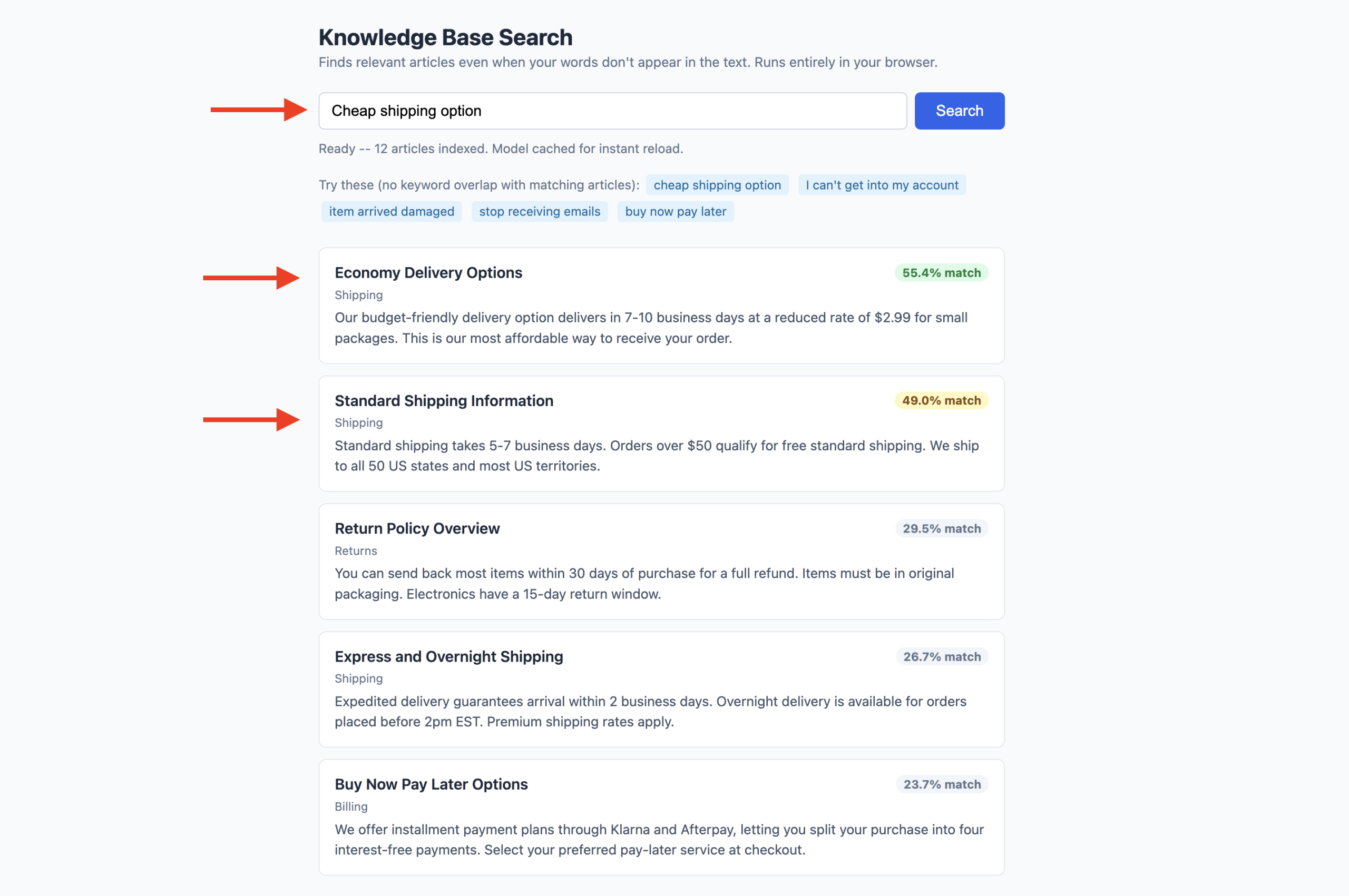
Bạn có thể đã từng gặp lỗi này, khi người dùng nhập " affordable laptop " (máy tính xách tay giá cả phải chăng) vào thanh tìm kiếm và nhận được kết quả bằng không.
Xây dựng tìm kiếm ngữ nghĩa với Transformers.js và nhúng câu
Bởi Shittu Olumide vào ngày 5/6/2026 trong Mô hình ngôn ngữ 0
Chia sẻ
Đăng
Chia sẻ
Trong bài viết này, bạn sẽ tìm hiểu cách hoạt động của nhúng câu và cách xây dựng công cụ tìm kiếm ngữ nghĩa hoàn toàn phía máy khách bằng Transformers.js, không yêu cầu máy chủ, khóa API và cơ sở hạ tầng phụ trợ.
Các chủ đề chúng ta sẽ đề cập bao gồm:
Cách nhúng câu và độ tương đồng cosine tạo thành nền tảng của tìm kiếm ngữ nghĩa.
Cách tạo và lưu trữ nhúng bằng cách sử dụng quy trình trích xuất tính năng của Transformers.js, bao gồm phân lô và chuyển tải Web Worker.
Cách xây dựng một lớp SemanticSearch hoàn chỉnh, có thể tái sử dụng và duy trì chỉ mục của nó qua các lần tải trang.
Xây dựng tìm kiếm ngữ nghĩa với Transformers.js và nhúng câu
Giới thiệu
Bạn có thể đã gặp lỗi này trước đây, khi người dùng nhập "máy tính xách tay giá cả phải chăng" vào thanh tìm kiếm của bạn và không nhận được kết quả nào. Nhưng bạn biết cơ sở dữ liệu có hàng chục bài viết về máy tính xách tay. Chúng chỉ có tiêu đề là "máy tính xách tay giá rẻ". Các từ khác nhau. Ý nghĩa giống hệt nhau. Tìm kiếm từ khóa coi cả hai là các chuỗi không liên quan.
Đây không phải là một trường hợp ngoại lệ. Đó là giới hạn cốt lõi của việc khớp từ khóa: nó so sánh các ký tự, không phải khái niệm. Nó không biết rằng "hủy" và "trả lại" mô tả các hành động liên quan, rằng "hỏng" và "lỗi" có nghĩa giống nhau, hoặc rằng "Tôi không thể đăng nhập" và "vấn đề truy cập tài khoản" là cùng một vấn đề được diễn đạt theo hai cách khác nhau.
Nhúng câu thực sự là gì
Tìm kiếm ngữ nghĩa khắc phục điều này bằng cách so sánh ý nghĩa. Và với Transformers.js, bạn có thể xây dựng nó hoàn toàn trong trình duyệt mà không cần máy chủ, khóa API và cơ sở hạ tầng phụ trợ. Hướng dẫn này sẽ đi qua toàn bộ quy trình: cách hoạt động của nhúng câu, cách tạo chúng, cách độ tương đồng cosine tính điểm mức độ liên quan và cách kết nối tất cả vào một ứng dụng tìm kiếm cơ sở tri thức đang hoạt động.
Một mô hình transformer không thể xử lý văn bản thô. Trước khi bất kỳ tính toán nào xảy ra, một câu cần phải trở thành các con số. Nhúng là kết quả của quá trình chuyển đổi đó: một câu được biểu diễn dưới dạng một danh sách các giá trị dấu phẩy động được gọi là một vector.
Thuộc tính chính không chỉ là các câu trở thành các con số. Đó là các câu có ý nghĩa tương tự trở thành các vector gần nhau về mặt hình học trong cùng một không gian vector.
Mô hình được sử dụng trong suốt hướng dẫn này, sentence-transformers/all-MiniLM-L6-v2, ánh xạ mỗi câu đến một điểm trong không gian vector 384 chiều. Mô hình đã được tinh chỉnh trên hơn 1 tỷ cặp câu đặc biệt để học thuộc tính hình học này. "Tôi cần hủy đơn hàng của mình" và "Làm cách nào để trả lại sản phẩm?" kết thúc gần nhau. "Thời tiết hôm nay đẹp" kết thúc xa cả hai.
384 chiều không thể đọc được bằng con người. Bạn không thể nhìn vào chiều 47 và nói nó mã hóa cái gì. Điều quan trọng đối với tìm kiếm không phải là bất kỳ chiều riêng lẻ nào mà là khoảng cách giữa hai vector. Khoảng cách ngắn có nghĩa là ý nghĩa tương tự. Khoảng cách lớn có nghĩa là không liên quan.
Sơ đồ biểu đồ phân tán 3D minh họa cách các câu tương tự về mặt ngữ nghĩa nhóm lại với nhau trong không gian vector (nhấp để phóng to)
Gộp và chuẩn hóa
Mô hình transformer thô xuất ra một vector cho mỗi token; mỗi từ và từ phụ trong một câu đều có vector riêng. Đối với tìm kiếm ngữ nghĩa, bạn cần một vector cho mỗi câu.
Mean pooling xử lý vấn đề này bằng cách tính trung bình tất cả các vector token, có trọng số theo mặt nạ chú ý (attention mask), do đó các token đệm (padding tokens) không đóng góp. Chuẩn hóa sau đó điều chỉnh kết quả về độ dài đơn vị (độ lớn = 1), giúp đơn giản hóa việc tính toán độ tương đồng được đề cập trong phần tiếp theo.
Trong Transformers.js, cả hai thao tác này đều tự động diễn ra khi người dùng truyền { pooling: 'mean', normalize: true } vào lệnh gọi pipeline. Nếu không có các tùy chọn này, người dùng sẽ nhận được các nhúng (embeddings) cấp độ token, hữu ích cho các tác vụ như nhận dạng thực thể có tên (named entity recognition), nhưng không phù hợp cho tìm kiếm cấp độ câu.
**Pipeline trích xuất đặc trưng**
Tác vụ trích xuất đặc trưng (feature-extraction) khác biệt so với mọi pipeline Transformers.js khác. Các tác vụ như phân loại văn bản (text-classification) hoặc trả lời câu hỏi (question-answering) trả về kết quả dễ đọc đối với con người: nhãn, điểm số, chuỗi ký tự. feature-extraction trả về các biểu diễn vector thô mà mô hình đã tính toán nội bộ. Người dùng đang làm việc ở một cấp độ thấp hơn, nhận được các con số mà tất cả các tác vụ cấp cao hơn được xây dựng dựa trên đó.
```javascript
import { pipeline } from 'https://cdn.jsdelivr.net/npm/@huggingface/transformers@3.0.2';
// Tải pipeline trích xuất đặc trưng
// Xenova/all-MiniLM-L6-v2 là phiên bản ONNX của
// sentence-transformers/all-MiniLM-L6-v2 -- cùng trọng số mô hình, định dạng tương thích với trình duyệt
const extractor = await pipeline(
'feature-extraction',
'Xenova/all-MiniLM-L6-v2',
{ dtype: 'q8' } // Lượng tử hóa 8-bit: tải xuống nhỏ hơn (~23 MB), độ chính xác tốt
);
// Nhúng một câu đơn
// pooling: 'mean' -- tính trung bình tất cả các vector token thành một vector câu
// normalize: true -- điều chỉnh kết quả về độ dài đơn vị (cần thiết cho độ tương đồng cosine)
const output = await extractor('I need help with my order', {
pooling: 'mean',
normalize: true
});
console.log(output);
// Tensor {
// dims: [1, 384], // 1 câu, 384 chiều
// type: 'float32',
// data: Float32Array(384) // các con số thực tế
// }
// Chuyển đổi sang một mảng JavaScript thuần túy để sử dụng trong mã của người dùng
const vector = output.tolist()[0]; // [0.045, 0.073, -0.012, ...] -- 384 con số
console.log(`Vector length: ${vector.length}`); // 384
```


Nguồn tin: Machine Learning Mastery — Tác giả: Shittu Olumide. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.