Trong bài viết này, chúng ta sẽ giải quyết một câu hỏi mà hầu hết các hướng dẫn về RAG thường bỏ qua – điều gì thực sự xảy ra với tài liệu của bạn trước khi nó được đưa vào cơ sở dữ liệu vector như Qdrant? Chúng tôi đã đánh giá hai trình phân tích cú pháp mã nguồn mở, LitParse từ LlamaIndex và Docling từ IBM Research, trên một cuốn sách giáo khoa kỹ thuật thực tế dày 340 trang, chứa nhiều bảng và khối mã trải dài nhiều trang. Cùng một tài liệu, số liệu trung thực, không có các tiêu chí đánh giá được chọn lọc. Hãy bắt đầu mà không lãng phí thời gian.
do tác giả M K Pavan Kumar thực hiện
Giới thiệu – Vấn đề không mấy hấp dẫn mà không ai nói đến
Mọi người đều nói về embeddings. Mọi người
Trong bài viết này, chúng tôi sẽ giải quyết một vấn đề mà hầu hết các hướng dẫn về RAG (Retrieval-Augmented Generation) thường bỏ qua: điều gì thực sự xảy ra với tài liệu của bạn trước khi nó đến một cơ sở dữ liệu vector như Qdrant? Chúng tôi đã đánh giá hai trình phân tích cú pháp mã nguồn mở, LitParse từ LlamaIndex và Docling từ IBM Research, trên một cuốn sách giáo khoa kỹ thuật thực tế dài 340 trang, chứa đầy các bảng và khối mã trải dài nhiều trang. Cùng một tài liệu, số liệu trung thực, không có các tiêu chí đánh giá được chọn lọc. Hãy bắt đầu mà không lãng phí nhiều thời gian.
do tác giả M K Pavan Kumar thực hiện
Giới thiệu – Vấn đề không mấy hấp dẫn mà không ai nói đến
Mọi người đều nói về các embedding. Mọi người đều bị ám ảnh bởi cơ sở dữ liệu vector nào nhanh nhất, LLM nào đạt điểm cao nhất trong các tiêu chí đánh giá, chiến lược truy xuất nào – dày đặc, thưa thớt, lai – mang lại khả năng thu hồi tốt nhất. Các bài báo về RAG được trích dẫn, bảng xếp hạng được cập nhật, các cuộc thảo luận trên Linkedin được viết.
Không ai nói về trình phân tích cú pháp.
Tuy nhiên, trước khi bất kỳ bộ máy tinh vi nào đó hoạt động, một thứ gì đó phải đọc tệp PDF của bạn. Một thứ gì đó phải xem xét một cuốn sách giáo khoa kỹ thuật dài 340 trang – đầy đủ các bảng bắt đầu từ trang 47 và kết thúc ở trang 49, các khối mã bị cắt một cách thô bạo ở ranh giới trang, các tiêu đề mà một công cụ trích xuất ngây thơ nhầm lẫn với văn bản chính – và biến nó thành thứ mà một mô hình embedding thực sự có thể làm việc được.
Nếu bước đó sai, thì bộ truy xuất của bạn có tốt đến mấy cũng không thành vấn đề. Bạn đang embedding nhiễu. Bạn đang truy xuất các đoạn văn bản. LLM của bạn đang tạo ra thông tin sai lệch từ ngữ cảnh không đầy đủ và bạn đang gỡ lỗi các lời nhắc (prompt) trong khi vấn đề thực sự nằm ở ba bước trước đó, trong quá trình tiền xử lý.
Bài viết này nói về bước đó.
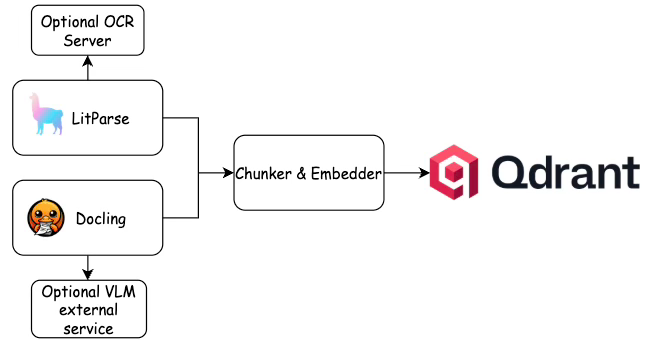
Chúng tôi đã đánh giá hai trình phân tích cú pháp tài liệu mã nguồn mở – LitParse từ LlamaIndex và Docling từ IBM Research – đặc biệt là một lớp tiền xử lý trước khi đưa vào công cụ tìm kiếm Qdrant. Cùng một tài liệu, cùng một máy, số liệu trung thực. Không có tiếp thị, không có các tiêu chí đánh giá được chọn lọc từ các tệp README.
Hãy cùng tìm hiểu.
Thiết lập bối cảnh – Tài liệu thử nghiệm của chúng tôi
Không phải tất cả các tệp PDF đều được tạo ra như nhau. Một bài đăng trên blog hai trang được xuất sang PDF là một loại tài liệu hoàn toàn khác so với những gì chúng tôi đã đưa vào các trình phân tích cú pháp này.
Tài liệu thử nghiệm của chúng tôi: một cuốn sách giáo khoa kỹ thuật dài 340 trang. Loại tài liệu khiến các trình phân tích cú pháp phải "đổ mồ hôi".
Điều gì khiến nó khó khăn? Các bảng không vừa một trang – chúng bắt đầu giữa trang, tiếp tục qua ranh giới trang và tiếp tục mà không có tiêu đề lặp lại để báo hiệu sự liên tục. Các khối mã bị chia cắt giữa các trang, làm mất ngữ cảnh thụt lề trong quá trình. Các bố cục hỗn hợp nơi một trang có thể có văn xuôi, một bảng và một đoạn mã cùng tồn tại. Các tiêu đề phần trông khác biệt về mặt hình ảnh nhưng lại mơ hồ về mặt cấu trúc đối với một công cụ trích xuất chỉ nhìn thấy các luồng văn bản thô.
Đây chính xác là loại tài liệu thường xuất hiện trong các quy trình RAG cho các lĩnh vực kỹ thuật – sách giáo khoa, bài báo nghiên cứu, tài liệu API, hướng dẫn kỹ thuật. Và đây chính xác là nơi khoảng cách giữa một trình phân tích cú pháp "đủ tốt" và một công cụ thông minh tài liệu phù hợp trở nên rõ ràng.
Nếu trình phân tích cú pháp của bạn có thể xử lý điều này, nó có thể xử lý hầu hết mọi thứ. Nếu nó gặp khó khăn ở đây, bạn sẽ phát hiện ra một cách khó khăn – sau khi nhập, sau khi lập chỉ mục, khi kết quả truy xuất của bạn bắt đầu trông có vẻ không mạch lạc một cách đáng ngờ.
Giới thiệu LitParse – Tốc độ mạnh mẽ được hỗ trợ bởi Rust
LitParse là một thư viện phân tích cú pháp tài liệu mã nguồn mở được viết bằng Rust. Nó chạy hoàn toàn trên máy của bạn – không có đám mây, không có khóa API, không có LLM liên quan. Phần cuối cùng đó quan trọng hơn những gì nó nghe có vẻ. Trong các quy trình sản xuất, càng ít phụ thuộc bên ngoài trong bước tiền xử lý của bạn thì càng tốt. llamaindex
Những gì nó thực sự làm: nó phân tích văn bản với thông tin bố cục không gian.
và các hộp giới hạn. Mỗi dòng văn bản được định vị tại vị trí xuất hiện trên trang. Điều này khác biệt đáng kể so với việc chỉ trích xuất văn bản thô – người dùng không chỉ biết nội dung văn bản mà còn biết vị trí của nó. Dữ liệu không gian này mở ra khả năng áp dụng các chiến lược phân đoạn (chunking) dựa trên bố cục cho các ứng dụng hạ nguồn, giúp trích dẫn văn bản được xác định chính xác.
Ngoài PDF, công cụ này còn xử lý các định dạng DOCX, XLSX, PPTX, PNG, JPG và nhiều định dạng khác thông qua chuyển đổi tự động. Tính năng nhận dạng ký tự quang học (OCR) được tích hợp sẵn thông qua Tesseract, hoặc người dùng có thể kết nối với máy chủ OCR riêng nếu cần một giải pháp mạnh mẽ hơn.
Về mặt vận hành, công cụ này cũng rất thực tế – người dùng có thể sử dụng từ Python, TypeScript/Node.js, Rust, hoặc thậm chí trên trình duyệt thông qua WASM. Công cụ được cung cấp kèm theo giao diện dòng lệnh (CLI) cho các tác vụ nhanh và API thư viện khi được tích hợp vào một quy trình.
Triết lý thiết kế rõ ràng: nhanh, cục bộ, không bất ngờ. LitParse không cố gắng hiểu tài liệu của người dùng. Nó cố gắng trích xuất tài liệu – một cách chính xác, nhanh chóng, mà không cần kết nối mạng.
Trên cuốn sách giáo khoa 340 trang của chúng tôi, quá trình này hoàn thành trong 0,31 giây. Chúng ta sẽ thảo luận về chi phí của tốc độ này trong giây lát.
Từ thư viện LiteParse
Thời gian bắt đầu = datetime.datetime.now()
Bộ phân tích cú pháp = LiteParse(ocr_enabled=False, target_pages="25-340")
Kết quả = bộ phân tích cú pháp.parse("./data/Everything_about_language_models_and_ai_agents.pdf")
Thời gian kết thúc = datetime.datetime.now()
In (f"Thời gian đã trôi qua: {thời gian kết thúc - thời gian bắt đầu}")
Giới thiệu Docling – Công cụ thông minh tài liệu của IBM Research
Docling được khởi xướng bởi nhóm AI for knowledge tại IBM Research Zurich và kể từ đó đã phát triển thành một dự án mã nguồn mở chính thức dưới sự bảo trợ của LF AI & Data Foundation. Nguồn gốc này thể hiện rõ tham vọng của dự án – đây không phải là một công cụ trích xuất văn bản, mà là một hệ thống hiểu tài liệu. github
Trong khi LitParse hỏi "văn bản ở đâu?", Docling hỏi "đây là gì?". Nó phân biệt được giữa một ô bảng và một đoạn văn. Nó tái tạo thứ tự đọc. Nó phát hiện các khối mã, công thức và vùng hình ảnh dưới dạng các loại phần tử riêng biệt, thay vì gộp tất cả thành một chuỗi phẳng.
Cốt lõi của hệ thống này là DoclingDocument – một định dạng biểu diễn thống nhất, biểu cảm, nắm bắt cấu trúc tài liệu, không chỉ nội dung. Từ đó, người dùng có thể tuần tự hóa sang bất kỳ định dạng nào mà quy trình của họ yêu cầu: Markdown, HTML, JSON, DocTags hoặc WebVTT. Sự linh hoạt này rất quan trọng – Markdown bảo toàn cấu trúc bảng để phân đoạn, JSON cung cấp quyền truy cập lập trình vào mọi phần tử, HTML giữ nguyên ngữ nghĩa bố cục. github
Phiên bản mới nhất đi kèm với một mô hình bố cục mới có tên Heron.
Nguồn tin: Medium Towards AI — Tác giả: M K Pavan Kumar. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.