Tối ưu hóa PySpark: 12 kỹ thuật đã được chứng minh để tăng tốc các tác vụ Spark của bạn
Các đường ống dữ liệu hiện đại xử lý khối lượng lớn dữ liệu có cấu trúc và phi cấu trúc mỗi ngày. Khi tập dữ liệu tăng lên, các tác vụ Spark được tối ưu hóa kém sẽ trở nên chậm hơn, tốn kém hơn và khó mở rộng hơn. Các vấn đề thường gặp bao gồm thời gian thực thi dài, xáo trộn quá mức, tắc nghẽn bộ nhớ và các phép nối không hiệu quả. Tối ưu hóa PySpark hiệu quả có thể cải thiện đáng kể hiệu suất, giảm chi phí cơ sở hạ tầng và nâng cao hiệu quả của cụm. Bài viết PySpark Optimization: 12 Proven Techniques to Speed Up Your Spark Jobs xuất hiện lần đầu trên Analytics Vidhya.
Tối ưu hóa PySpark: 12 kỹ thuật đã được chứng minh để tăng tốc các tác vụ
Hội nghị AI tương lai nhất của Ấn Độ đã trở lại – Lớn hơn, sắc nét hơn, táo bạo hơn
Nhận thông tin chi tiết
Các khóa học miễn phí
Chương trình tăng tốc
Chương trình GenAI Pinnacle
GenAI Pinnacle Plus
Agentic AI Pioneer
DeepSeek
DataHack Summit 2025
DHS 2026
Đăng nhập
Chuyển chế độ
Đăng xuất
Chuẩn bị phỏng vấn
Sự nghiệp
GenAI
Kỹ thuật nhắc lệnh (Prompt Engg)
ChatGPT
LLM
Langchain
RAG
AI Agents
Học máy (Machine Learning)
Học sâu (Deep Learning)
Công cụ GenAI
LLMOps
Python
NLP
SQL
Dự án AIML
Danh sách đọc
Lộ trình học phân tích dữ liệu
Cách trở thành nhà phân tích dữ liệu vào năm 2025: Lộ trình hoàn chỉnh
Lộ trình học Tableau
Lộ trình học Tableau toàn diện vào năm 2025
Lộ trình học NLP
Lộ trình học NLP toàn diện 2025
Lộ trình học khoa học dữ liệu
Lộ trình học để trở thành nhà khoa học dữ liệu vào năm 2025
Lộ trình học kỹ sư dữ liệu
Lộ trình từng bước để trở thành kỹ sư dữ liệu vào năm 2025
Lộ trình học MLOps
Lộ trình học MLOps toàn diện: Phiên bản 2025
Lộ trình học kỹ sư AI
Lộ trình để trở thành kỹ sư AI vào năm 2025
Lộ trình học thị giác máy tính (Computer Vision)
Lộ trình học toàn diện để thành thạo thị giác máy tính vào năm 2025
Lộ trình học AI tạo sinh (Generative AI)
Lộ trình tốt nhất để học AI tạo sinh vào năm 2025
Lộ trình GenAI cho doanh nghiệp
Lộ trình GenAI cho doanh nghiệp
Lộ trình LLM
Các mô hình ngôn ngữ lớn được giải mã: Lộ trình cho người mới bắt đầu
Lộ trình kỹ sư nhắc lệnh (Prompt Engineer)
Lộ trình học để trở thành chuyên gia kỹ thuật nhắc lệnh
Trang chủ
Spark
Tối ưu hóa PySpark: 12 kỹ thuật đã được chứng minh để tăng tốc các tác vụ Spark của bạn
Tối ưu hóa PySpark: 12 kỹ thuật đã được chứng minh để tăng tốc các tác vụ Spark của bạn
Vipin Vashisth
Cập nhật lần cuối: 27/5/2026
23 phút đọc
Các đường ống dữ liệu hiện đại xử lý khối lượng lớn dữ liệu có cấu trúc và phi cấu trúc mỗi ngày. Khi tập dữ liệu tăng lên, các tác vụ Spark được tối ưu hóa kém sẽ trở nên chậm hơn, tốn kém hơn và khó mở rộng hơn. Các vấn đề thường gặp bao gồm thời gian thực thi dài, xáo trộn quá mức, tắc nghẽn bộ nhớ và các phép nối không hiệu quả.
Việc tối ưu hóa PySpark hiệu quả có thể cải thiện đáng kể hiệu suất, giảm chi phí cơ sở hạ tầng và nâng cao hiệu quả của cụm. Trong bài viết này, chúng ta sẽ khám phá 12 kỹ thuật tối ưu hóa PySpark đã được chứng minh với các ví dụ thực tế và chiến lược hiệu suất trong thế giới thực được các kỹ sư dữ liệu sử dụng.
Mục lục
Cách Spark thực thi mã của bạn
Tìm hiểu kiến trúc Spark
Đánh giá lười biếng (Lazy Evaluation) trong Spark
Tìm hiểu các phép biến đổi (Transformations) và hành động (Actions) của Spark
Đọc kế hoạch thực thi Spark bằng explain()
Các phương pháp tối ưu hóa mô hình Spark
Phương pháp 1: Sử dụng định dạng tệp dạng cột như Parquet hoặc ORC
Phương pháp 2: Lọc dữ liệu càng sớm càng tốt
Phương pháp 3: Chỉ chọn các cột cần thiết
Phương pháp 4: Tối ưu hóa phân vùng
Phương pháp 5: Sử dụng Broadcast Join cho các bảng nhỏ
Phương pháp 6: Bật Adaptive Query Execution (AQE)
Phương pháp 7: Tránh sử dụng Python UDF (hàm do người dùng định nghĩa) bất cứ khi nào có thể
Phương pháp 8: Lưu trữ dữ liệu vào bộ nhớ đệm một cách chiến lược
Phương pháp 9: Xử lý độ lệch dữ liệu hiệu quả
Phương pháp 10: Giảm thiểu các thao tác xáo trộn (Shuffle Operations)
Phương pháp 11: Sử dụng Bucketing cho các thao tác Join lặp lại
Phương pháp 12: Tinh chỉnh cài đặt cấu hình Spark
Ví dụ tối ưu hóa PySpark từ đầu đến cuối
Kết luận
Cách Spark thực thi mã của bạn
Bạn cần tìm hiểu cách Spark thực thi mã của mình trước khi bắt đầu công việc tối ưu hóa. Các nhà phát triển viết mã PySpark mà không hiểu các quy trình cơ bản hỗ trợ mã của họ. Việc thiếu kiến thức dẫn đến các quyết định hiệu suất không tối ưu. Các cơ chế cốt lõi của phần này cho phép người đọc hiểu mọi kỹ thuật tối ưu hóa tiếp theo.
Tìm hiểu kiến trúc Spark
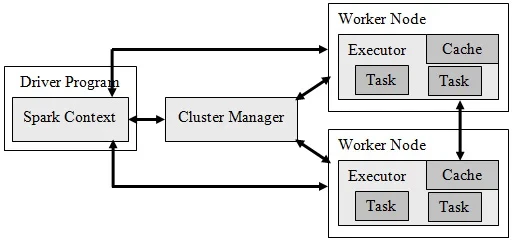
Spark vận hành hệ thống phân tán của mình, cho phép xử lý dữ liệu đồng thời trên nhiều máy tính khác nhau. Mỗi ứng dụng Spark bao gồm hai thành phần chính hoạt động đồng bộ.
Driver và Executor
Driver đóng vai trò là hệ thống điều khiển trung tâm cho ứng dụng Spark của bạn. Nó thực thi chương trình chính của bạn trong khi phát triển chiến lược thực thi và giám sát tất cả các hoạt động. Các Executor hoạt động như đội ngũ vận hành. Cụm phân phối các worker này đến các máy khác nhau, nơi lưu trữ dữ liệu trong bộ nhớ trong khi thực hiện các tác vụ tính toán thực tế.
Driver chia công việc thành các tác vụ nhỏ hơn mà nó gửi đến các Executor khi bạn gửi một Spark job. Mỗi Executor hoạt động trên phân đoạn dữ liệu được chỉ định của nó mà không có bất kỳ sự phụ thuộc nào vào các hệ thống khác. Sự kết hợp của các phương pháp xử lý song song cho phép Spark mang lại hiệu suất cao.
Job, Stage và Task
Spark tổ chức công việc tính toán của bạn thành ba lớp phân cấp.
Job: Một phép tính hoàn chỉnh được kích hoạt bởi một hành động (như count() hoặc write()).
Stage: Một tập hợp các tác vụ có thể chạy mà không cần xáo trộn dữ liệu qua mạng.
Task: Đơn vị công việc nhỏ nhất. Mỗi tác vụ xử lý một phân vùng dữ liệu.
Bạn có thể tìm thấy các vấn đề về hiệu suất trong Spark UI bằng cách sử dụng cấu trúc phân cấp này để định vị các thành phần hệ thống khác nhau.
Nguồn: Hình ảnh
Đánh giá lười biếng (Lazy Evaluation) trong Spark
Khung Spark sẽ không thực thi các phép biến đổi của bạn ngay khi bạn tạo chúng. Hệ thống ghi lại các hành động dự định của bạn khi bạn sử dụng các hàm filter(), select() và groupBy(). Hệ thống tạo ra một cấu trúc logic để biểu thị các hành động dự định của bạn. Hệ thống yêu cầu bạn thực hiện một hành động bao gồm show(), count() và write() để bắt đầu quá trình thực thi.
Đánh giá lười biếng mô tả mô hình hoạt động này. Hệ thống

Nguồn tin: Analytics Vidhya — Tác giả: Vipin Vashisth. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.