Hệ thống học tập tăng cường sâu A* + kết hợp trong Unity, SR-71, 5 triệu bước đào tạo và hiểu biết sâu sắc về kiến trúc đã giúp hệ thống này hoạt động.
Khi một phi công chiến đấu thực hiện một chuyến xuất kích thường lệ, họ không ứng biến — họ làm theo kế hoạch. Khi chuông báo động khóa tên lửa vang lên, chúng không làm theo kế hoạch — mà ứng biến. AI cổ điển rất tuyệt ngay từ đầu. Học tăng cường là tuyệt vời ở lần thứ hai. Vậy tại sao hầu hết mọi người lại cố gắng sử dụng một trong số chúng cho cả hai? Câu hỏi đó đã bắt đầu dự án này.
Vào năm 2020, các thử nghiệm AlphaDogfight của DARPA đã kết thúc bằng tác nhân học tăng cường sâu một cách dứt khoát b
Hệ thống học tập tăng cường sâu A* + kết hợp trong Unity, SR-71, 5 triệu bước đào tạo và hiểu biết sâu sắc về kiến trúc đã giúp hệ thống này hoạt động.
Khi một phi công chiến đấu thực hiện một chuyến xuất kích thường lệ, họ không ứng biến — họ làm theo kế hoạch. Khi chuông báo động khóa tên lửa vang lên, chúng không làm theo kế hoạch — mà ứng biến. AI cổ điển rất tuyệt ngay từ đầu. Học tăng cường là tuyệt vời ở lần thứ hai. Vậy tại sao hầu hết mọi người lại cố gắng sử dụng một trong số chúng cho cả hai? Câu hỏi đó đã bắt đầu dự án này.
Vào năm 2020, các thử nghiệm AlphaDogfight của DARPA đã kết thúc với việc tác nhân học tăng cường sâu đánh bại một phi công F-16 có kinh nghiệm của con người trong các trận không chiến mô phỏng. Tiêu đề là tương lai của không chiến là AI. Chú thích cuối trang ít được chú ý hơn là tác nhân chiến thắng không phải là một hệ thống RL đầu cuối thuần túy. Đó là một sự kết hợp — các bộ điều khiển khác nhau trao đổi với nhau tùy theo tình huống.
Tôi muốn hiểu mô hình đó nên tôi đã xây dựng một phiên bản nhỏ của nó ngay từ đầu. Một đặc vụ SR-71 trong Unity. Một mê cung của những trở ngại để di chuyển. Một bệ phóng tên lửa dẫn đường bằng radar sẽ hoạt động ngay khi đặc vụ đi vào phạm vi phát hiện của nó. Và hai bộ não khác nhau: người lập kế hoạch đường đi cổ điển cho những phần nhàm chán và chính sách RL sâu sắc cho phần hỗn loạn.
Đây là những gì tôi đã xây dựng, cách nó hoạt động và lý do tại sao tôi cho rằng kiến trúc kết hợp là ý tưởng bị đánh giá thấp nhất trong AI ứng dụng hiện nay.
Kho lưu trữ: github.com/Alpsource/Mastering-Fighter-Jet-Survival-Tactics
Được đào tạo về Unity. 5 triệu bước. Hai bộ não. Cái nhìn sâu sắc: Hai loại vấn đề, hai loại bộ não
Hầu hết các vấn đề về điều hướng trên không thực chất là hai vấn đề khi mặc cùng một bộ trang phục.
Đầu tiên là lập kế hoạch lộ trình — đi từ điểm A đến điểm B xung quanh các chướng ngại vật đã biết. Đây là một vấn đề xác định, được xác định rõ ràng với một câu trả lời tối ưu rõ ràng. Nó đã được giải quyết tốt đẹp từ những năm 1960. A*, RRT, Dijkstra. Các thuật toán tìm kiếm cổ điển chạy trong mili giây, cung cấp cho bạn các đường dẫn tối ưu có thể chứng minh được và hoàn toàn có thể dự đoán được. Họ không làm bạn ngạc nhiên. Họ không bị ảo giác. Họ không cần dữ liệu đào tạo.
Thứ hai là trốn tránh mối đe dọa — khi có thứ gì đó đang cố gắng giết bạn, thế giới trở nên không cố định, động lực có thể quan sát được một phần và không có câu trả lời tối ưu rõ ràng nào để tính toán. Đây chính xác là loại vấn đề mà học tăng cường sâu đã được phát minh ra. Huấn luyện chính sách dựa trên hàng triệu tình huống ngẫu nhiên, cho phép chính sách phát hiện các kiểu trốn tránh mà không con người nào nghĩ tới để chỉ định và triển khai.
Nếu bạn xây dựng một hệ thống sử dụng RL cho cả hai vấn đề, bạn sẽ lãng phí rất nhiều năng lực để đào tạo nhân viên thực hiện một việc mà A* đã làm một cách hoàn hảo. Nếu bạn xây dựng một hệ thống sử dụng A* cho cả hai, máy bay phản lực của bạn sẽ bay thẳng vào tên lửa.
Một động thái thú vị là sử dụng cả hai và chuyển đổi.
Tác nhân chạy ở một trong hai chế độ tại bất kỳ thời điểm nào. Việc chuyển đổi diễn ra trong thời gian thực, được kích hoạt bởi một khối cầu xung quanh bệ phóng tên lửa.Thiết lập
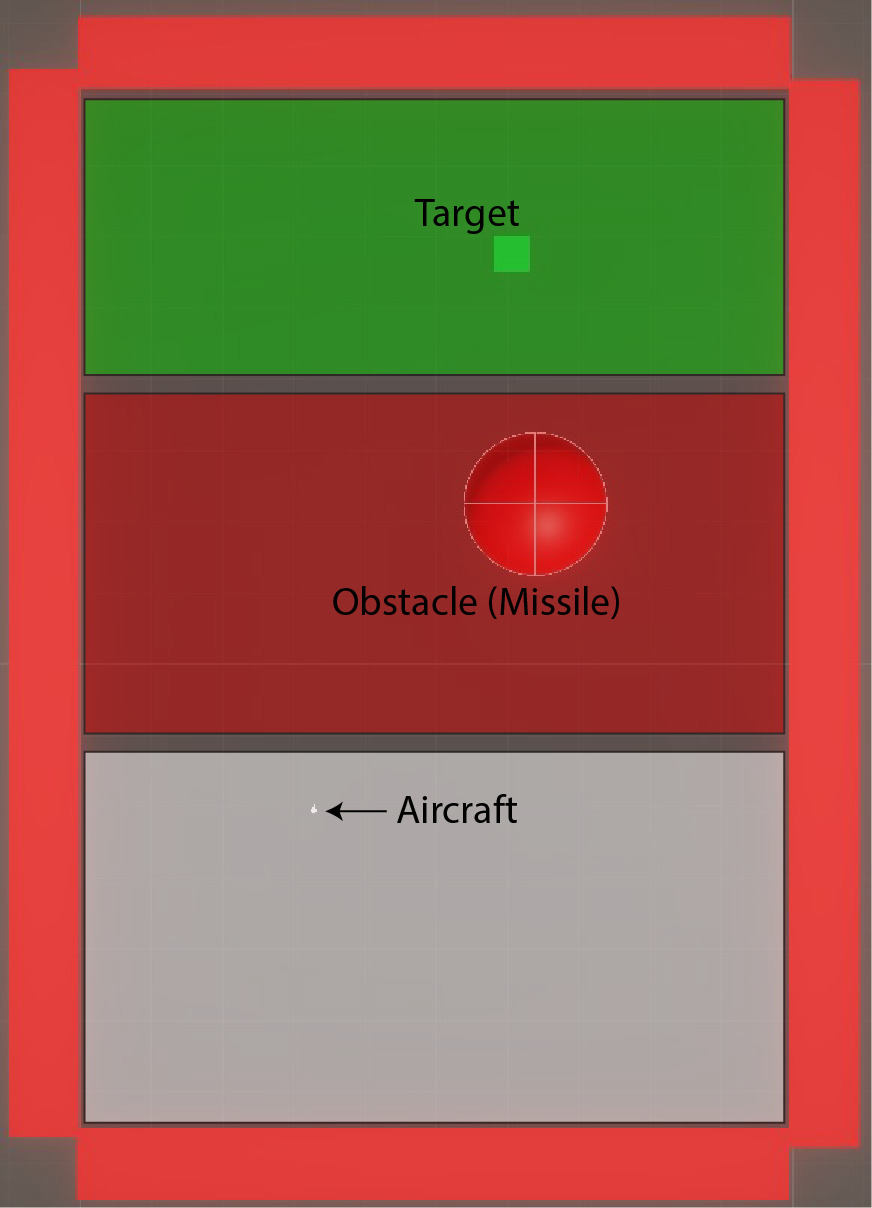
Môi trường là cảnh 3D từ trên xuống trong Unity 2022.3 với ML-Agents. Ba vùng:
Dưới cùng: khu vực sinh sản của máy bay (vị trí X ngẫu nhiên để đặc vụ không thể ghi nhớ một quỹ đạo)
Ở giữa: một bệ phóng tên lửa có bán kính phát hiện có thể định cấu hình, được hiển thị dưới dạng quả cầu khung dây màu trắng
Trên cùng: vùng mục tiêu — một nền tảng xanh mang lại cho đại lý phần thưởng +100 khi liên hệ
Những bức tường màu tím tạo thành một mê cung thủ tục mà máy bay phải điều hướng. Va chạm vào tường khiến tác nhân phải chịu một hình phạt tỷ lệ thuận với khoảng cách nó vẫn còn cách mục tiêu — nên bay vào một bức tường gần mục tiêu là vi phạm
Thật là thảm khốc hơn là bay vào một chiếc ngay từ đầu.
Máy bay này là lưới Lockheed SR-71, vì nếu bạn đang chế tạo một mô phỏng sinh tồn máy bay chiến đấu, bạn cũng có thể chọn chiếc máy bay đẹp nhất từng bay.
Môi trường đào tạo. Máy bay sinh sản ở vùng dưới cùng. Bệ phóng tên lửa ở giữa. Mục tiêu ở trên cùng. Những bức tường màu tím (giữa máy bay và tên lửa) tạo thành mê cung.A* Lập kế hoạch cho Con đường
A* là một thuật toán đã 65 năm tuổi và nó vẫn có cảm giác như một phép thuật.
Tôi chiếu cảnh 3D lên lưới chiếm chỗ 2D — mỗi ô lưu trữ số 0 (không gian trống) hoặc 1 (chướng ngại vật). PathFinder chạy A* trên lưới này bằng cách sử dụng khoảng cách Euclide tiêu chuẩn làm phương pháp phỏng đoán và trả về điểm tham chiếu tiếp theo để hướng tới. Lưới được xây dựng lại bất cứ khi nào chướng ngại vật di chuyển, vì vậy đường đi vẫn hiện hành ngay cả khi môi trường thay đổi.
Máy bay không dịch chuyển tức thời giữa các điểm tham chiếu — nó bay đến từng điểm bằng cách sử dụng các lực vật lý, với bộ điều khiển PID trên trục ngáp sẽ sửa lỗi tiêu đề trong mỗi bản cập nhật FixedUpdate. PID rất đơn giản (Kp=0,05, Ki=0, Kd=0,002) và được điều chỉnh theo cách thủ công, vì khi đã có vòng lặp bên trong ổn định, bạn có thể lặp lại mọi thứ bên ngoài vòng lặp đó.
Lưới A. Mỗi ô là 0 hoặc 1. Màu tím = chướng ngại vật. Đây là chế độ “nhàm chán”. Máy bay bay một đường đi sạch sẽ, chạm vào các điểm định hướng và đến mục tiêu — miễn là không có gì cố gắng giết chết nó.
DQN học cách né tránh
Khi khối cầu của bệ phóng tên lửa phát hiện máy bay trong bán kính kích hoạt của nó, một dòng C# sẽ bắn:
SwitchBehavior(BehaviorType.DQN);ML-Agents BehaviorType chuyển sang InferenceOnlyChính sách ONNX đã đào tạo sẽ tiếp quản và A* tắt.
Đặc vụ nhìn thấy không gian quan sát 14 chiều. Công việc của đặc vụ RL hẹp hơn so với người lập kế hoạch A*: nó không quan tâm đến mục tiêu toàn cầu, chỉ là không chết trong vài giây tới. Không gian quan sát phản ánh điều này:
Vị trí địa phương của đại lý (3 điểm mờ)
Góc quay của tác nhân theo góc Euler (3 dims)
Vị trí cục bộ của mục tiêu (3 điểm mờ) — nên đặc vụ vẫn biết đại khái nơi cần đến
Vị trí cục bộ của tên lửa (3 điểm mờ) — thứ đang cố gắng tiêu diệt nó
Khoảng cách tới mục tiêu (1 mờ)
Khoảng cách đến mối đe dọa (1 mờ)
Tổng cộng 14 chiều. Nhỏ gọn, được thiết kế bằng tay, không có hình ảnh hoặc LIDAR — chỉ là sự thật hình học của tình huống. Không gian hành động có hai giá trị liên tục: một delta chuyển động ngang và một delta chuyển động tiến, với thành phần chuyển tiếp được kẹp hoàn toàn dương để tác nhân không thể học cách bay lùi để thoát khỏi sự cố.
Cấu trúc phần thưởng được cố ý tối thiểu hóa:
E
Nguồn tin: Medium Towards AI — Tác giả: Alp Demirel. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.