Ngày 10 – Chào mừng đến với embeddings. Nơi ý nghĩa chỉ là toán học.
Trong Ngày 9, tôi đã xây dựng một ứng dụng RAG. Mỗi đoạn văn bản được chuyển đổi thành 768 con số trước khi được lưu trữ. Tôi gọi chúng là embeddings (nhúng), giải thích rằng chúng "ghi lại ý nghĩa", và tiếp tục.
Nhưng tôi cứ nghĩ – điều đó thực sự có nghĩa là gì? 768 con số. Làm thế nào các con số ghi lại ý nghĩa? Làm thế nào mô hình biết rằng "happy" (hạnh phúc) và "joyful" (vui vẻ) là tương tự? Không ai nói cho nó biết điều đó.
Vì vậy, tôi đã xây dựng một ứng dụng khác. Ứng dụng này chỉ làm một việc: lấy hai đoạn văn bản và cho bạn biết chúng tương tự nhau đến mức nào. Một điểm số từ 0 đến 1.
Sau đó, tôi đã thử nghiệm nó với một số ví dụ thực sự
Ngày thứ 10 – Giới thiệu về Embeddings. Nơi ý nghĩa chỉ là toán học.
Vào Ngày thứ 9, tôi đã xây dựng một ứng dụng RAG. Mỗi đoạn văn bản được chuyển đổi thành 768 con số trước khi lưu trữ. Tôi gọi chúng là embeddings, giải thích rằng chúng "ghi lại ý nghĩa", rồi tiếp tục.
Nhưng tôi vẫn băn khoăn – điều đó thực sự có nghĩa là gì? 768 con số. Làm thế nào mà các con số lại ghi lại ý nghĩa? Làm thế nào mà mô hình biết rằng "happy" (hạnh phúc) và "joyful" (vui vẻ) là tương tự nhau? Không ai nói cho nó biết điều đó.
Vì vậy, tôi đã xây dựng một ứng dụng khác. Ứng dụng này chỉ làm một việc: lấy hai đoạn văn bản và cho bạn biết chúng tương tự nhau đến mức nào. Một điểm số từ 0 đến 1.
Sau đó, tôi đã thử nghiệm nó với một số ví dụ thực sự làm tôi ngạc nhiên.
Tiết lộ – tình yêu và sự căm ghét đạt điểm 0,80. Đến cuối bài viết này, bạn sẽ hiểu chính xác lý do tại sao.
Embeddings là gì?
Từ ngữ đi vào. Các con số đi ra. Đó là những gì embeddings làm. | Hình ảnh: AI tạo ra
Một embedding là kết quả bạn nhận được khi chuyển đổi văn bản thành một danh sách các con số.
Không phải các con số ngẫu nhiên. Mà là các con số mang ý nghĩa.
Hãy nhìn vào hình ảnh trên. Các từ như "concept" (khái niệm), "language" (ngôn ngữ), "perception" (nhận thức) đi vào bộ não bên trái. Các con số – 42, 3.14159, chuỗi nhị phân – đi ra bên phải.
Đó chính xác là những gì một mô hình embedding làm. Nó lấy các từ của bạn và chuyển đổi chúng thành một danh sách các con số. Trong ứng dụng của chúng tôi, mỗi đoạn văn bản trở thành chính xác 768 con số. Không hơn, không kém. Luôn luôn là 768.
Nhưng đây là điều làm cho nó mạnh mẽ – đây không phải là các con số ngẫu nhiên. Chúng là những con số được định vị cẩn thận để ghi lại ý nghĩa của văn bản.
Các từ tương tự sẽ có các con số tương tự. "Happy" và "joyful" sẽ có danh sách các con số rất giống nhau. "Happy" và "pizza" sẽ có danh sách rất khác nhau.
Mô hình đã học các vị trí số này bằng cách đọc hàng tỷ câu trong quá trình đào tạo. Nó không bao giờ học một cách rõ ràng rằng happy = joyful. Nó chỉ thấy chúng được sử dụng trong các ngữ cảnh tương tự rất nhiều lần đến nỗi chúng có các con số tương tự nhau.
Đó là toàn bộ ý tưởng. Các từ trở thành các con số. Các ý nghĩa tương tự trở thành các con số tương tự. So sánh các con số. Tìm ý nghĩa.
Ứng dụng tôi đã xây dựng
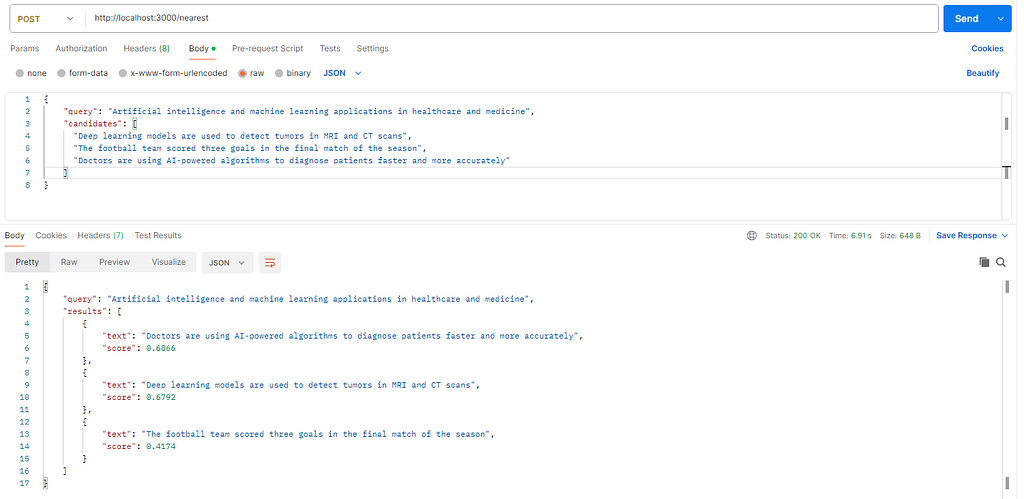
POST /nearest đang hoạt động – ứng dụng xếp hạng các câu theo ý nghĩa, không phải từ khóa. | Ảnh chụp màn hình: Của tác giả
Tiền đề đơn giản. Hai tuyến (route):
POST /similarity – so sánh hai văn bản, nhận điểm số
POST /nearest – cung cấp một truy vấn và một danh sách, nhận chúng được xếp hạng theo mức độ tương tự
Không có API trả phí. Không có đám mây. Chạy trên Ollama với mô hình nomic-embed-text cục bộ.
Cấu trúc dự án:
similarity-app/
├── server.js ← Các tuyến API
├── src/
│ ├── embedder.js ← chuyển đổi văn bản thành vector thông qua Ollama
│ └── similarity.js ← toán học tương tự cosine
Ba tệp. Đó là một công cụ tìm kiếm ngữ nghĩa hoàn chỉnh.
Mã nguồn – Ba phần chính
embedder.js – embedMany sử dụng Promise.all
async function embedMany(texts) {
return Promise.all(texts.map(embed));
}
Dòng này thông minh hơn vẻ ngoài của nó. Thay vì nhúng các văn bản từng cái một – chờ mỗi cái hoàn thành trước khi bắt đầu cái tiếp theo – nó gửi tất cả các yêu cầu đồng thời. Nếu bạn có 10 văn bản để nhúng, tất cả chúng sẽ đến Ollama cùng một lúc. Nhanh hơn nhiều.
similarity.js – tương tự cosine trong ba bước
function dotProduct(a, b) {
return a.reduce((sum, val, i) => sum + val * b[i], 0);
}
function magnitude(v) {
return Math.sqrt(v.reduce((sum, val) => sum + val * val, 0));
}
function cosineSimilarity(a, b) {
return dotProduct(a, b) / (magnitude(a) * magnitude(b));
}
Tôi chia nó thành ba hàm có tên có chủ đích. Hầu hết các triển khai viết nó thành một công thức dày đặc. Việc chia nó thành dotProduct, magnitude và cosineSimilarity làm cho mỗi bước dễ đọc.
Bước 1 – nhân từng cặp số và cộng chúng lại.
Bước 2 – tìm độ lớn (magnitude) của mỗi vector.
và “độ dài” của mỗi vectơ.
Bước 3 – chia để nhận được điểm số từ 0 đến 1.
Điểm càng gần 1, ý nghĩa càng tương đồng. Chỉ vậy thôi.
server.js – điểm cuối gần nhất
const [queryVec, ...candidateVecs] = await embedMany([query, ...candidates]);
const results = rankBySimilarity(queryVec, candidateVecs, candidates);
Nhúng truy vấn và tất cả các ứng viên trong một lệnh gọi. Xếp hạng chúng. Trả về kết quả đã sắp xếp. Cấu trúc phân tách [queryVec, ...candidateVecs] là một cách rõ ràng để tách mục đầu tiên khỏi phần còn lại – truy vấn khỏi các ứng viên.
Những gì tôi thực sự đã thử nghiệm – và điều làm tôi ngạc nhiên
Đây là phần tôi thấy thú vị nhất. Tôi đã chạy sáu thử nghiệm và một số kết quả thực sự khiến tôi phải dừng lại.
Thử nghiệm 1 – Cùng ý nghĩa, từ ngữ khác nhau
{ "text1": "Tôi vui", "text2": "Tôi hân hoan" }
→ Điểm: 0.8743
Có lý. Các từ đồng nghĩa đạt điểm cao. Mô hình biết rằng "vui" và "hân hoan" được sử dụng trong các ngữ cảnh tương tự. Không có gì ngạc nhiên ở đây.
Thử nghiệm 2 – Ý nghĩa đối lập 🤯
{ "text1": "Tôi yêu mèo", "text2": "Tôi ghét mèo" }
→ Điểm: 0.8064
"Yêu" và "ghét" đạt 0.80. Ứng dụng không nói dối. | Ảnh chụp màn hình: Tác giả tự chụp. Điều này khiến tôi phải dừng lại.
"Yêu" và "ghét" là những từ đối lập. Bạn sẽ mong đợi một điểm thấp. Thay vào đó – 0.80. Gần như tương tự như "vui" và "hân hoan".
Tại sao? Bởi vì các embedding quan tâm đến chủ đề và ngữ cảnh, không phải sắc thái cảm xúc. Cả hai câu đều nói về mèo và cảm xúc. Mô hình xem chúng có liên quan chặt chẽ – bởi vì cả hai đều nói về cùng một thứ, ngay cả khi cảm xúc đối lập.
Đây là một hạn chế thực sự của các embedding cơ bản. Chúng không giỏi trong việc hiểu sắc thái cảm xúc. Nếu bạn cần phát hiện xem một thứ gì đó là tích cực hay tiêu cực, bạn cần một phương pháp khác – phân tích sắc thái cảm xúc, không phải độ tương đồng cosine.
Thử nghiệm 3 – Hoàn toàn không liên quan
{
"text1": "Học máy đang thay đổi ngành chăm sóc sức khỏe",
"text2": "Chiếc pizza rất ngon và giòn"
}
→ Điểm: 0.4053
Điểm thấp như mong đợi. AI và pizza không có điểm chung nào trong không gian embedding. Đây là điểm số mà nó phải có đối với các chủ đề không liên quan.
Thử nghiệm 4 – Thuật ngữ kỹ thuật so với tiếng Anh thông thường
{
"text1": "RAG truy xuất các đoạn liên quan bằng cách sử dụng độ tương đồng cosine",
"text2": "RAG tìm phần liên quan nhất trong tài liệu của bạn trước khi trả lời"
}
→ Điểm: 0.5905
Điều này cũng làm tôi ngạc nhiên. Cả hai câu đều mô tả cùng một thứ – RAG. Nhưng một câu sử dụng thuật ngữ kỹ thuật và một câu sử dụng tiếng Anh thông thường.
Điểm: chỉ 0.59. Có liên quan vừa phải, không quá tương đồng.
Các thuật ngữ chuyên ngành – “chunks” (đoạn), “cosine similarity” (độ tương đồng cosine), “retrieves” (truy xuất) – tạo ra đủ khoảng cách trong không gian embedding khiến mô hình coi chúng là...
Nguồn tin: Medium Towards AI — Tác giả: Priyanka Mali. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.