Together AI đã xây dựng hệ thống chuyển lời nói thành văn bản nhanh nhất thế giới như thế nào
Together AI đã xây dựng hệ thống chuyển đổi giọng nói thành văn bản (speech-to-text) nhanh nhất trên Artificial Analysis bằng cách coi ASR là một vấn đề hệ thống toàn diện, không chỉ là vấn đề suy luận GPU.
Nội dung bạn cung cấp trống rỗng. Vui lòng cung cấp văn bản để tôi có thể dịch.
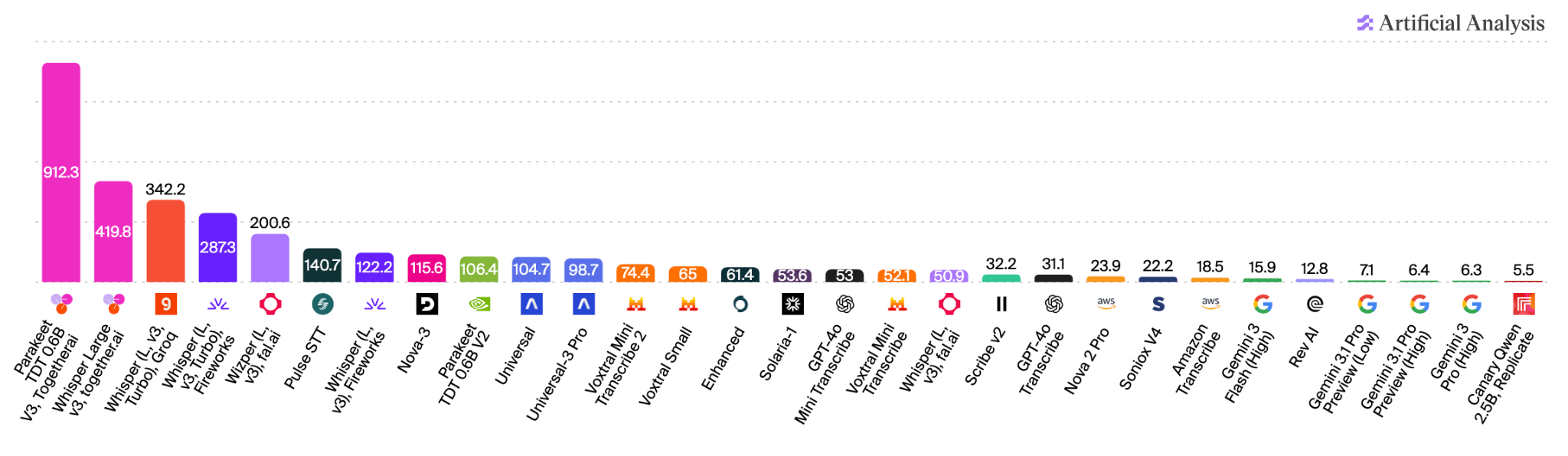
Artificial Analysis đã báo cáo yếu tố tốc độ (số giây âm thanh đầu vào được phiên âm trên mỗi giây) – chỉ số càng cao càng tốt.
**Phương thức truyền tải rất quan trọng**
Một lời nhắc văn bản 1M-token có thể chứa toàn bộ bộ truyện Harry Potter và chỉ nặng khoảng 5 MB. Quy mô đó nghe có vẻ khổng lồ, nhưng bản thân đầu vào lại nhỏ gọn. Văn bản cũng gần như sẵn sàng để suy luận: mã hóa, phân lô và chuyển qua mô hình.
Âm thanh làm thay đổi bản chất của vấn đề. Cùng một kho ngữ liệu Harry Potter dưới dạng sách nói có dung lượng từ 5 đến 10 GB, lớn hơn khoảng ba bậc độ lớn so với văn bản. Trước khi bất kỳ phần nào của nó đến GPU, máy chủ phải giải mã vùng chứa, lấy mẫu lại, lọc nhiễu, chạy VAD (phát hiện hoạt động giọng nói), phân đoạn lời nói và tính toán các đặc trưng âm thanh.
Phía mô hình cũng thay đổi. Các LLM (mô hình ngôn ngữ lớn) ngày nay có hàng trăm tỷ hoặc hàng nghìn tỷ tham số, vì vậy công việc phục vụ tự nhiên tập trung bên trong GPU: lượng tử hóa, bộ nhớ đệm KV, nhân chú ý, phân lô và song song hóa. Các mô hình chuyển lời nói thành văn bản nhỏ hơn nhiều, thường chỉ từ hàng trăm triệu đến vài tỷ tham số, vì vậy đường dẫn dữ liệu xung quanh quan trọng hơn nhiều.
Điều đó khiến việc phục vụ ASR (nhận dạng giọng nói tự động) trở thành một vấn đề hệ thống toàn diện, bao gồm thực thi GPU, tiền xử lý CPU, di chuyển bộ nhớ, truyền tải, lập lịch kết nối và hành vi thời gian chạy. Cùng một ngăn xếp cũng phải phục vụ hai chế độ khác nhau: phiên âm ngoại tuyến, nơi thông lượng quan trọng nhất, và phiên âm trực tuyến, nơi độ trễ và độ biến động chiếm ưu thế.
Ngăn xếp ASR của Together phục vụ hai mô hình chuyển lời nói thành văn bản có độ trễ thấp nhất được xếp hạng bởi Artificial Analysis: NVIDIA Parakeet-TDT 0.6B v3 và OpenAI Whisper Large v3. Mô hình nhanh hơn trong hai mô hình này, NVIDIA Parakeet-TDT 0.6B v3, có thể phiên âm khoảng 20 giờ lời nói, tương đương thời lượng của loạt phim Harry Potter, trong vòng chưa đầy 10 giây.
Phần còn lại của bài viết này sẽ phân tích các thay đổi trong sản xuất đằng sau kết quả đó: các cấu hình TensorRT cho các dạng âm thanh thực, luồng điều khiển bộ giải mã phía GPU, đường dẫn CPU ít sao chép hơn, I/O truyền trực tuyến theo sự kiện và điều khiển GC (thu gom rác) thời gian chạy.
**Biên dịch bộ mã hóa cho các dạng âm thanh thực**
Parakeet sử dụng kiến trúc bộ mã hóa-giải mã, và khoảng 95% trọng số của nó nằm trong bộ mã hóa. Bộ mã hóa nhận một phân đoạn lời nói có độ dài thay đổi và tạo ra các khung âm thanh cho bộ giải mã, điều này khiến nó trở thành nơi đầu tiên cần tối ưu hóa.
Đầu vào âm thanh có nhiều độ dài khác nhau, từ gói truyền trực tuyến 200 ms đến 30 giây lời nói không ngắt quãng. Một kế hoạch nhân được điều chỉnh cho một dạng đầu vào có thể chậm hơn đáng kể ở dạng khác, vì vậy công cụ cần biết phân phối dạng mà nó sẽ thấy tại thời điểm biên dịch.
Trước TensorRT, chúng tôi đã sử dụng đường dẫn PyTorch được tối ưu hóa với `torch.compile` và biểu đồ CUDA, được điều chỉnh trên cùng các cấu hình dạng. Điều đó mang lại cho chúng tôi một đường cơ sở mạnh mẽ: thực thi nhận biết cấu hình mà không cần rời khỏi ngăn xếp PyTorch.
TensorRT đã cung cấp cho chúng tôi một đường dẫn bộ mã hóa nhanh hơn cho sản xuất. Nó xây dựng một kế hoạch thực thi được tối ưu hóa trước, hợp nhất các nhân khi có thể, điều chỉnh bố cục bộ nhớ và đánh giá các biến thể nhân cho các phạm vi dạng mà chúng tôi dự kiến sẽ phục vụ.
Chi tiết quan trọng là điều chỉnh cấu hình. Một công cụ duy nhất chỉ được điều chỉnh cho dạng đầu vào lớn nhất sẽ buộc các phân đoạn âm thanh ngắn hơn vào một đường dẫn đệm, điều này đặc biệt tốn kém cho các đoạn truyền trực tuyến và các câu nói ngắn. Một công cụ TensorRT đa cấu hình cho phép chúng tôi giữ một bản sao trọng số bộ mã hóa trong bộ nhớ trong khi chọn cấu hình tối ưu hóa phù hợp cho mỗi yêu cầu.
Việc tiết kiệm bộ nhớ là khiêm tốn, khoảng 6 GB xuống còn 5 GB. Lợi ích lớn hơn là tránh các lỗi khớp dạng và chuyển từ PyTorch được tối ưu hóa sang TensorRT để có các cấu hình được điều chỉnh.
Trong chế độ đầu vào nhỏ, TensorRT nhận biết cấu hình có thể nhanh hơn nhiều lần so với việc gửi các yêu cầu đó thông qua một cấu hình đệm lớn.
Với bộ mã hóa được tối ưu hóa, vòng lặp bộ giải mã trở thành nút thắt cổ chai tiếp theo.
Loại bỏ CPU khỏi vòng lặp bộ giải mã
Bộ giải mã của Parakeet lặp lại các khung âm thanh của bộ mã hóa và phát ra một mã thông báo (token) hoặc một BLANK cho các khung không làm tăng bản ghi. Mã cơ bản như sau:
state = init()
for frame in encoder_output:
token = predict(frame, state)
if token != BLANK:
emit(token)
state = update(state, token)
Khi phân tích hiệu năng, chúng tôi nhận thấy rằng cả predict và update đều nhanh. Công việc của GPU trên mỗi lần lặp được đo bằng micro giây.
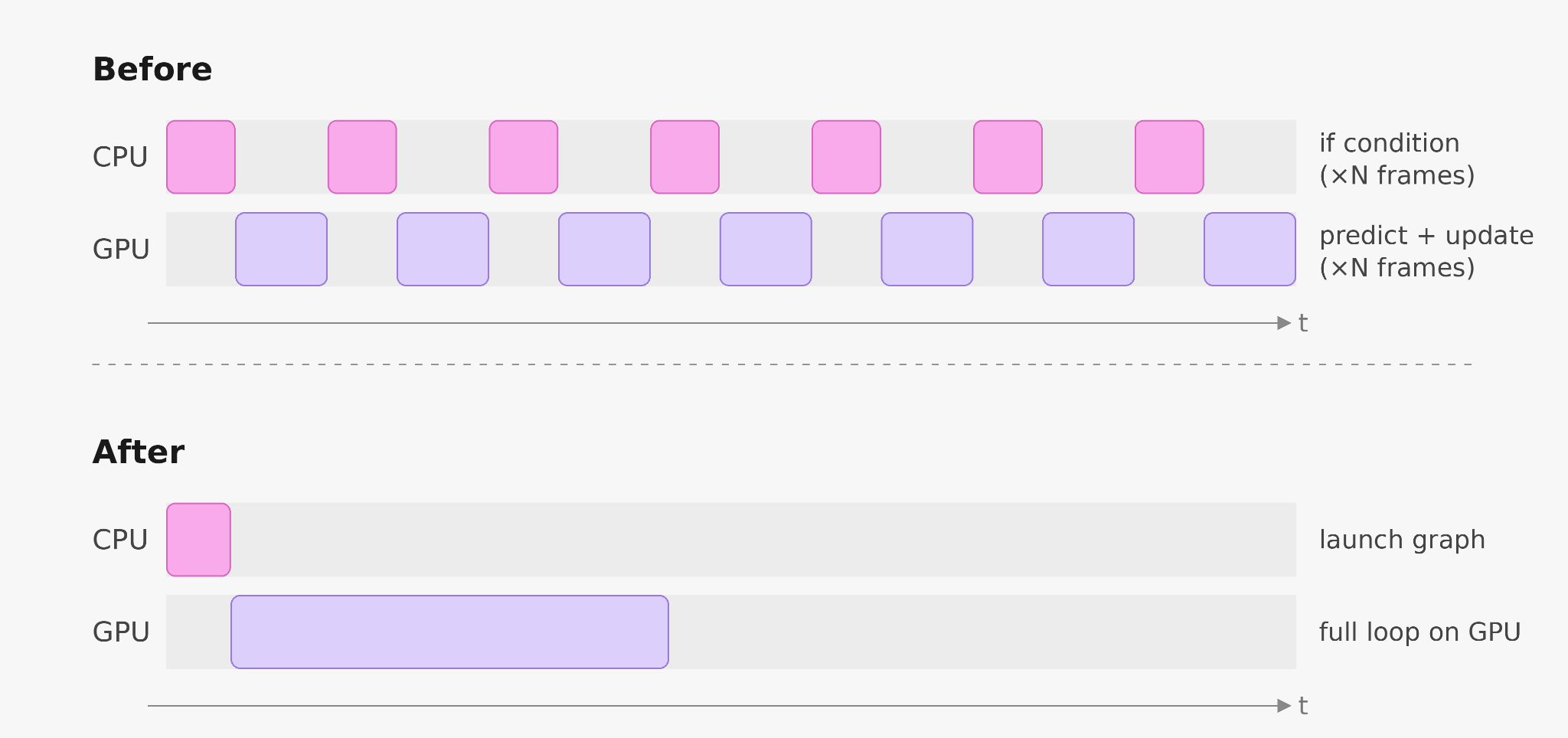
Dòng lệnh tốn kém là nhánh:
if token != BLANK:
Nhánh này yêu cầu CPU đọc lại mã thông báo từ bộ nhớ GPU để quyết định đường dẫn nào sẽ thực hiện. Đồng bộ hóa máy chủ này ngăn vòng lặp giải mã được ghi lại dưới dạng một biểu đồ CUDA duy nhất và buộc mỗi lần lặp phải đi qua Python. GPU thực hiện vài micro giây công việc, chờ CPU, khởi chạy nhân tiếp theo và lặp lại mẫu đó hàng nghìn lần cho mỗi yêu cầu.
Các nút biểu đồ CUDA có điều kiện đã chuyển nhánh đó lên GPU. Một nhân nhỏ phía thiết bị đánh giá điều kiện và cho thời gian chạy CUDA biết liệu có nên vào biểu đồ con phát mã thông báo và cập nhật trạng thái hay không. Nhánh được giải quyết mà không rời khỏi GPU, do đó toàn bộ vòng lặp bộ giải mã, bộ đếm, điều kiện, phát và cập nhật trạng thái, có thể được ghi lại và khởi chạy dưới dạng một biểu đồ CUDA.
CPU rời khỏi vòng lặp bên trong của bộ giải mã và kết quả là bộ giải mã nhanh hơn từ 2 đến 3 lần.
Ngừng sao chép các byte âm thanh
Khi bộ mã hóa và bộ giải mã hoạt động tốt, độ trễ còn lại đến từ đường dẫn CPU xung quanh mô hình. Đây là nơi hầu hết mã ASR mà chúng tôi đã kiểm tra tiêu tốn ngân sách độ trễ: các bản sao thừa, các bước nhảy quy trình không cần thiết trên đường dẫn nóng và các hàm đơn luồng sẽ được hưởng lợi từ song song hóa cao hơn.
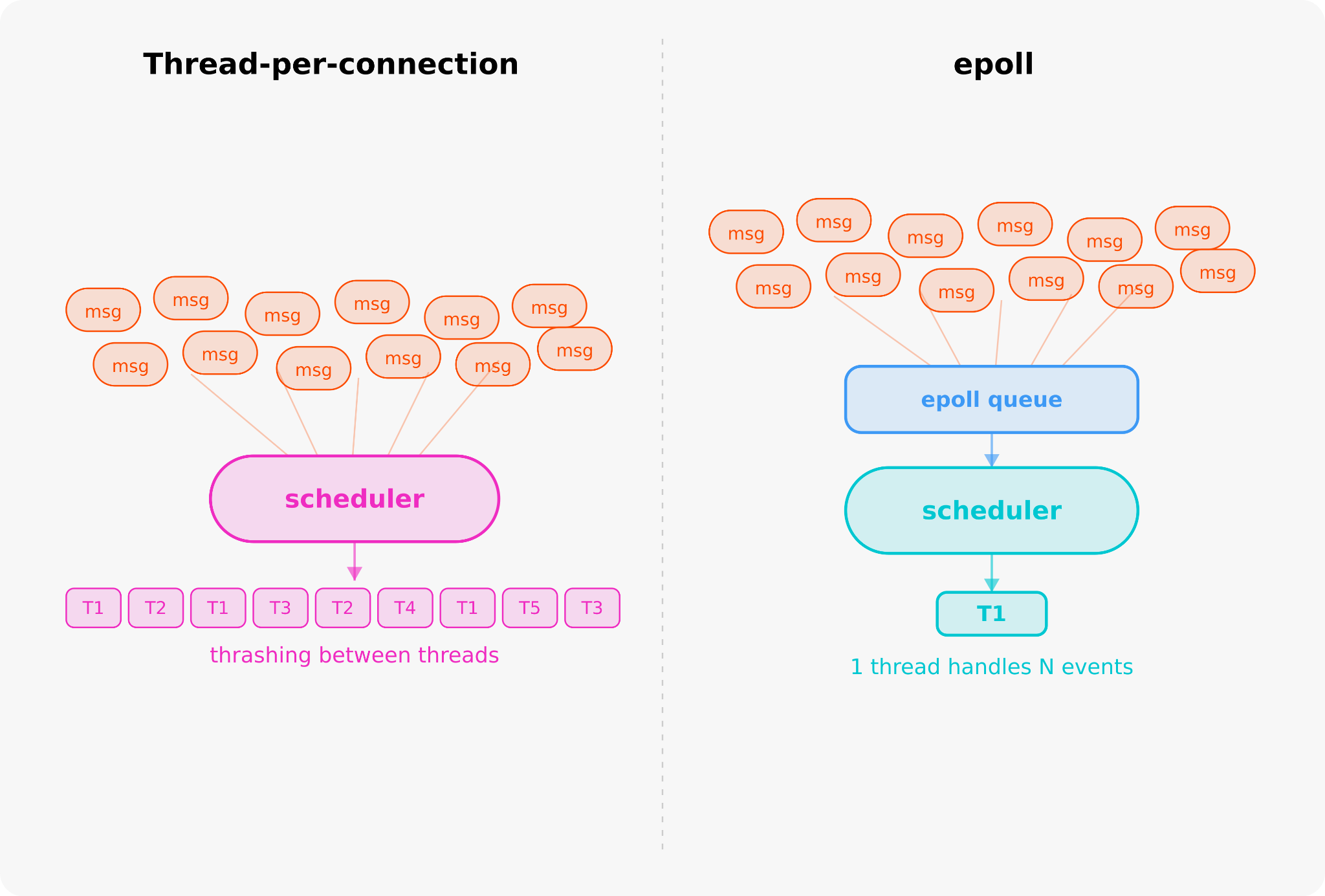
Đòn bẩy đầu tiên là loại bỏ các ranh giới quy trình không cần thiết.
Tiền xử lý âm thanh, dù là giải mã tệp, lấy mẫu lại, phát hiện hoạt động giọng nói (VAD), trích xuất đặc trưng hay xử lý khối, chủ yếu là công việc I/O hoặc C/C++ gốc giải phóng Khóa trình thông dịch toàn cục Python (GIL). Một kiến trúc microservice điển hình chia tiền xử lý thành ba hoặc bốn quy trình riêng biệt, phải trả giá cho sự cô lập mà khối lượng công việc không cần. Việc gộp hầu hết công việc đó vào ít quy trình hơn sẽ loại bỏ các bản sao kernel và các lượt tuần tự hóa/giải tuần tự hóa có thể tốn hàng trăm mili giây.
Nguồn tin: Together AI Blog. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.