Together AI đã công bố mã nguồn mở OSCAR: một hệ thống lượng tử hóa bộ nhớ đệm KV (Key-Value) 2-bit có nhận biết sự chú ý, được thiết kế để phục vụ các mô hình ngôn ngữ lớn (LLM) với ngữ cảnh dài.
Suy luận ngữ cảnh dài khiến bộ nhớ đệm KV trở thành một trong những chi phí chính khi vận hành các mô hình ngôn ngữ lớn (LLM). Trong quá trình giải mã tự hồi quy, bộ nhớ đệm này tăng lên theo độ dài ngữ cảnh, kích thước lô (batch size) và độ sâu của mô hình. Với kích thước lô lớn và ngữ cảnh dài lên tới 100.000 token trên hàng chục yêu cầu đồng thời, bộ nhớ đệm KV tiêu thụ một phần lớn bộ nhớ GPU. Nén bộ nhớ đệm này là một cách trực tiếp để tăng kích thước lô và giảm lưu lượng truy cập bộ nhớ.
Cách tiếp cận rõ ràng là lượng tử hóa. Tuy nhiên, việc đẩy bộ nhớ đệm KV xuống độ chính xác INT2 (2-bit) phần lớn là không thực tế. Các phương pháp trước đây hoặc làm giảm đáng kể độ chính xác hoặc yêu cầu bố cục phục vụ tùy chỉnh.
Suy luận ngữ cảnh dài khiến bộ nhớ đệm KV trở thành một trong những chi phí chính khi vận hành các mô hình ngôn ngữ lớn (LLM). Trong quá trình giải mã tự hồi quy, bộ nhớ đệm tăng theo độ dài ngữ cảnh, kích thước lô và độ sâu của mô hình. Với kích thước lô lớn và ngữ cảnh dài gồm 100.000 token trên hàng chục yêu cầu đồng thời, bộ nhớ đệm KV tiêu thụ một phần lớn bộ nhớ GPU. Nén bộ nhớ đệm là một cách trực tiếp để tăng kích thước lô và giảm lưu lượng bộ nhớ.
Cách tiếp cận rõ ràng là lượng tử hóa. Tuy nhiên, việc đẩy bộ nhớ đệm KV xuống độ chính xác INT2 (2-bit) phần lớn là không thực tế. Các phương pháp trước đây hoặc làm giảm độ chính xác hoặc yêu cầu bố cục phục vụ tùy chỉnh không tương thích với các hệ thống bộ nhớ đệm KV phân trang. OSCAR (Offline Spectral Covariance-Aware Rotation) của Together AI giải quyết cả hai vấn đề này.
Tại sao lượng tử hóa bộ nhớ đệm KV INT2 lại khó
Các kích hoạt KV chứa các giá trị ngoại lai theo kênh. Một tập hợp nhỏ các kênh chứa các giá trị cực lớn. Hầu hết các kênh đều hoạt động tốt. Khi áp dụng lượng tử hóa INT2 chỉ có bốn mức biểu diễn và các giá trị ngoại lai đó chi phối hệ số tỷ lệ. Bộ lượng tử hóa lãng phí hầu hết phạm vi của nó vào các đỉnh hiếm. Các giá trị bình thường bị nén thành chỉ một hoặc hai mức hiệu quả. Điều này làm giảm đáng kể chất lượng chú ý.
Lượng tử hóa dựa trên phép quay giải quyết vấn đề này bằng cách áp dụng một phép biến đổi trực giao cố định, thường là phép biến đổi Hadamard, để phân phối lại năng lượng ngoại lai trên tất cả các kênh. Cách tiếp cận này hoạt động khá tốt ở INT4. Ở INT2, một vấn đề sâu sắc hơn vẫn còn: phép quay không phụ thuộc vào dữ liệu. Nó có thể làm mịn các dải kích hoạt, nhưng nó không biết cơ chế chú ý thực sự đọc theo hướng nào. Việc phân tán lỗi lượng tử hóa đồng đều không giống như việc đẩy nó vào các hướng ít quan trọng. Ở INT2, với chỉ bốn mức, sự khác biệt đó quyết định liệu mô hình có hoạt động hay không.
https://arxiv.org/pdf/2605.17757v1
OSCAR làm gì khác biệt
Quan sát chính của OSCAR là phép quay được áp dụng trước khi lượng tử hóa nên được suy ra từ chính các thống kê chú ý — không phải từ phân phối thô của các kích hoạt KV.
Đối với các khóa, lỗi hạ nguồn quan trọng không phải là lỗi tái tạo Euclidean của K. Đó là lỗi trong các logit chú ý. Nhóm nghiên cứu đã chỉ ra rằng lỗi này là: ‖QK⊤ − QK̂⊤‖²F = tr((K − K̂)Q⊤Q(K − K̂)⊤). Ma trận trọng số là hiệp phương sai truy vấn Q⊤Q, không phải K⊤K. Các hướng mà truy vấn có năng lượng lớn sẽ khuếch đại lỗi lượng tử hóa trong các logit. OSCAR ước tính hiệp phương sai truy vấn thực nghiệm CQ = (1/N) Σ qn⊤qn từ một tập hợp hiệu chuẩn, phân tích giá trị riêng của nó và sử dụng các vector riêng UQ làm cơ sở quay khóa.
Đối với các giá trị, lỗi liên quan nằm trong đầu ra chú ý SV. Điều này phụ thuộc vào cách ma trận điểm chú ý S trọng số mỗi hàng giá trị. Nhóm nghiên cứu định nghĩa hiệp phương sai giá trị trọng số điểm CS = (1/N) V⊤S⊤SV. Các hướng vẫn lớn sau khi tổng hợp bởi S là những hướng mà lỗi lượng tử hóa lan truyền qua. OSCAR sử dụng các vector riêng US của CS làm cơ sở quay giá trị.
Các phép quay tổng hợp cuối cùng là:
RK = UQ · HHad · Pbr
RV = US · HHad · Pbr
Mỗi trong ba yếu tố giải quyết một chế độ lỗi riêng biệt của lượng tử hóa bit thấp theo nhóm:
UQ / US căn chỉnh các kênh với các hướng quan trọng của chú ý. Điều này làm chéo hóa ma trận trọng số lỗi để các hướng quan trọng nhất có thể được xác định.
HHad (biến đổi Walsh-Hadamard) sau đó cân bằng chính xác tầm quan trọng của kênh. Bổ đề 1 trong bài báo nghiên cứu chứng minh rằng mỗi mục nhập đường chéo của HHad⊤ Λ HHad bằng tr(Λ)/d — phổ giá trị riêng nhọn được UQ phơi bày được nén thành một giá trị đồng nhất trên tất cả các kênh.
Pbr (đảo bit hoán vị) sắp xếp lại các kênh sao cho đối với bất kỳ kích thước nhóm lượng tử hóa là lũy thừa của hai, mỗi nhóm nhận một đại diện từ mỗi cấp độ của hệ thống phân cấp tầm quan trọng.
Nhóm nghiên cứu cung cấp Định lý 1 chứng minh UQ và US là tối ưu theo mục tiêu thay thế lỗi đóng băng với các giả định dư đường chéo.
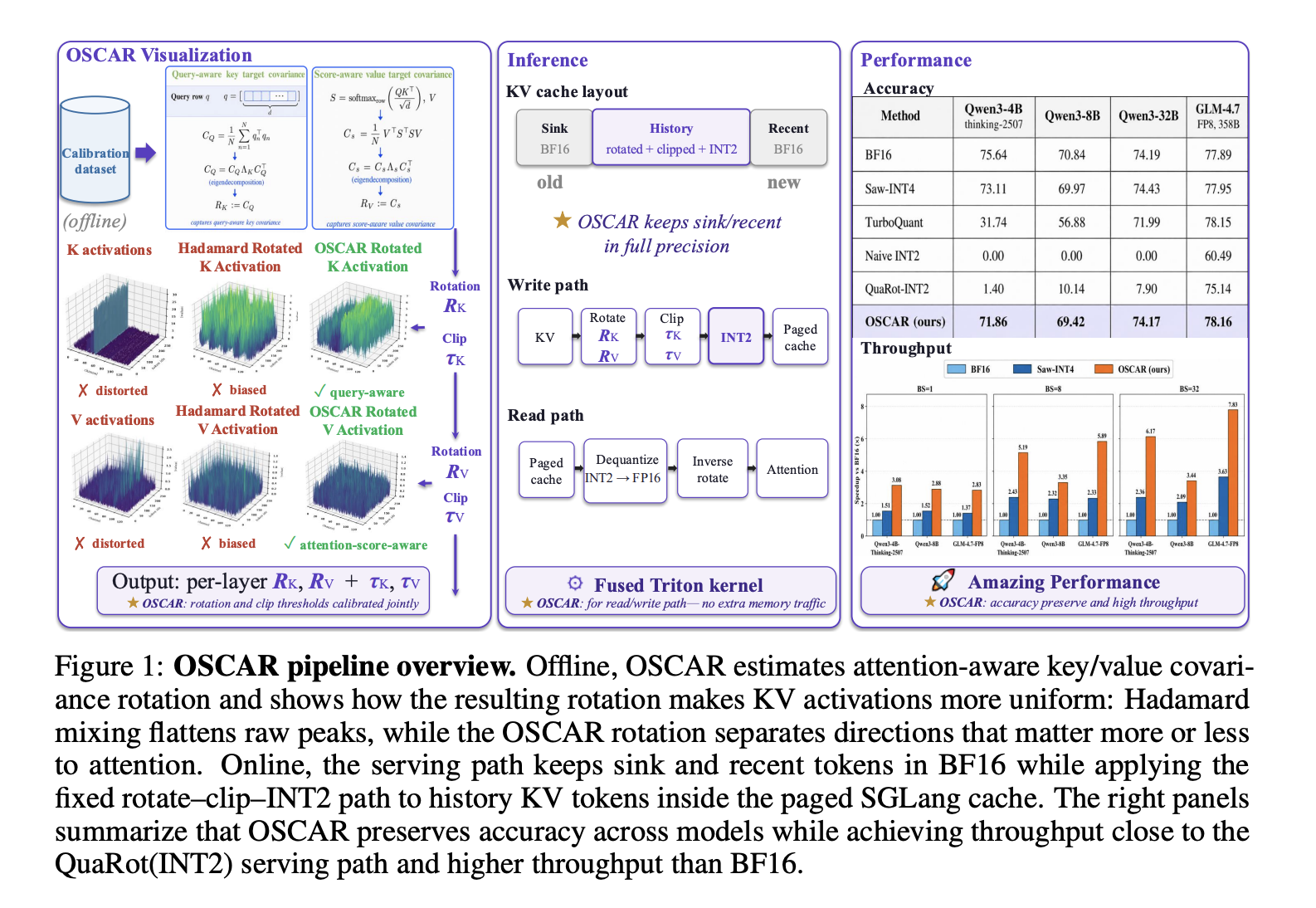
Hệ thống phục vụ: Bố cục bộ nhớ đệm hỗn hợp chính xác
OSCAR tích hợp vào ngăn xếp phục vụ sản xuất của SGLang dưới dạng chế độ bộ nhớ đệm KV INT2 với khả năng tương thích đầy đủ với paged attention.
Bố cục bộ nhớ đệm KV sử dụng ba vùng cho mỗi yêu cầu:
Các token chìm (S0 = 64 token đầu tiên): được lưu trữ ở định dạng BF16. Chúng hoạt động như các điểm chìm chú ý.
Các token gần đây (W = 256 token cuối cùng trước vị trí hiện tại): được lưu trữ ở định dạng BF16.
Các token lịch sử (tất cả các token ở giữa): được lưu trữ dưới dạng INT2 sau khi xoay và cắt bởi OSCAR.
Ở độ dài ngữ cảnh 128K, các cửa sổ chìm và gần đây BF16 chỉ chiếm 0,24% tổng số token. Phân tích loại bỏ (Bảng 5 trong bài báo nghiên cứu) cho thấy (S=64, R=256) là điểm cân bằng giữa độ chính xác và hiệu quả: các cửa sổ nhỏ hơn làm giảm đáng kể độ chính xác; các cửa sổ lớn hơn mang lại lợi ích bổ sung không đáng kể với chi phí bộ nhớ BF16 cao hơn.
https://arxiv.org/pdf/2605.17757
Các đường dẫn ghi và đọc sử dụng các nhân Triton hợp nhất. Trên đường dẫn ghi, mỗi token được xoay, cắt theo ngưỡng phần trăm được hiệu chuẩn (giá trị điển hình: cK = 0,96, cV = 0,92), sau đó được lượng tử hóa bằng INT2 bất đối xứng trên mỗi token với kích thước nhóm mặc định là GK = 64 kênh trên mỗi nhóm. Trên đường dẫn đọc, nhân INT2 giải nén byte, giải lượng tử hóa, xoay ngược và chuyển kết quả đến nhân chú ý — tất cả trong một lần truyền hợp nhất mà không có lưu lượng bộ nhớ bổ sung. Phép xoay giá trị RV được hấp thụ vào trọng số chiếu của mô hình ngoại tuyến, loại bỏ chi phí tính toán trực tuyến của nó.
Kết quả
Nhóm nghiên cứu đã đánh giá OSCAR trên bốn cấu hình mô hình: Qwen3-4B-Thinking-2507, Qwen3-8B, Qwen3-32B và GLM-4.7-FP8 (358 tỷ tham số). Các tiêu chuẩn bao gồm AIME25, GPQA-Diamond, HumanEval, LiveCodeBench v6 và MATH500, tất cả ở độ dài tạo tối đa 32K.
Độ chính xác (ở 2,28 bit trên mỗi phần tử KV):
Mô hình BF16 Trung bình OSCAR Trung bình Khoảng cách so với BF16
Qwen3-4B-Thinking-2507 75,64 71,86 -3,78
Qwen3-8B 70,84 69,42 -1,42
Qwen3-32B 74,19 74,17 -0,02
GLM-4.7-FP8 (358B) 77,89 78,16 +0,27
Để so sánh với các phương pháp cạnh tranh: INT2 thô (không xoay) đạt 0,00 trên cả Qwen3-4B và Qwen3-8B. QuaRot-INT2 (chỉ xoay Hadamard) đạt 1,40 trên Qwen3-4B và 10,14 trên Qwen3-8B. TurboQuant ở 3,25 bit giảm 43,90.
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.