Thống kê lựa chọn Token: Hướng dẫn về Logits, Nhiệt độ và Top-P
Khi các mô hình ngôn ngữ lớn (LLM) tạo ra kết quả đầu ra, một số tiêu chí được đặt ra, bao gồm không chỉ mức độ liên quan tổng thể của phản hồi mà còn cả tính mạch lạc và sáng tạo.
Thống kê lựa chọn Token: Hướng dẫn chi tiết về Logits, Temperature và Top-P
Bởi Iván Palomares Carrascosa vào ngày 27/5/2026 trong mục Mô hình ngôn ngữ 0
Chia sẻ
Đăng bài
Chia sẻ
Trong bài viết này, bạn sẽ tìm hiểu cách logits, temperature và lấy mẫu top-p hoạt động cùng nhau để kiểm soát dự đoán token tiếp theo trong các mô hình ngôn ngữ lớn.
Các chủ đề chúng ta sẽ đề cập bao gồm:
Logits là gì và cách chúng được tạo ra bởi lớp tuyến tính cuối cùng của transformer.
Cách temperature và top-p (lấy mẫu hạt nhân) định hình phân phối xác suất được sử dụng để lựa chọn token.
Cách ba thành phần này phù hợp với một quy trình tuần tự điều chỉnh việc tạo ra đầu ra của LLM.
Thống kê lựa chọn Token: Hướng dẫn chi tiết về Logits, Temperature và Top-P
Giới thiệu
Khi các mô hình ngôn ngữ lớn, hay gọi tắt là LLM, tạo ra đầu ra, một số tiêu chí được đặt ra, không chỉ bao gồm sự phù hợp tổng thể của phản hồi mà còn cả tính mạch lạc và sáng tạo. Vì các mô hình hoạt động sâu bên trong bằng cách xây dựng phản hồi từng từ – hay chính xác hơn là từng token – việc nắm bắt các thuộc tính mong muốn này là vấn đề điều chỉnh toán học các phân phối xác suất đầu ra điều chỉnh quá trình dự đoán token tiếp theo.
Bài viết này giới thiệu cơ chế đằng sau các chiến lược giải mã của LLM từ góc độ thống kê. Đặc biệt, chúng ta sẽ khám phá cách các điểm số thô của mô hình, được gọi là logits, tương tác với hai cài đặt mô hình khác – temperature và top-p – là ba tham số chính được sử dụng để kiểm soát quá trình lựa chọn token.
Mặc dù chúng ta sẽ tập trung vào việc khám phá những gì xảy ra trong các giai đoạn cuối cùng của kiến trúc cơ bản của LLM, hay còn gọi là transformer, bạn có thể xem bài viết này nếu cần một cái nhìn tổng quan ngắn gọn về toàn bộ quá trình và hành trình của các token từ đầu đến cuối.
Quá trình lựa chọn token trong LLM
Logits là gì?
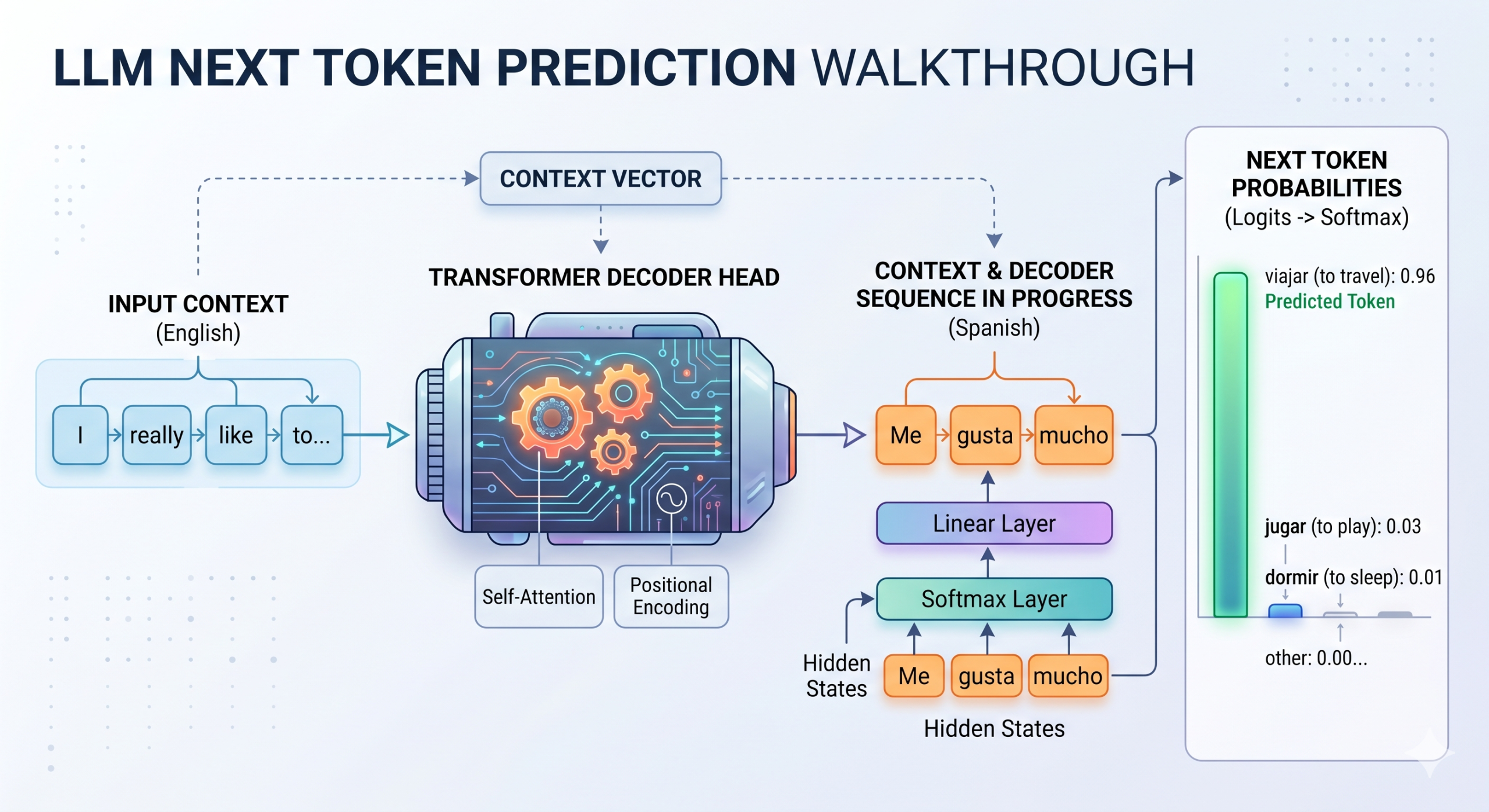
Trong mạng nơ-ron, các điểm số thô, chưa được chuẩn hóa được tạo ra (thường ở các lớp tuyến tính cuối cùng) trước khi chuyển đổi chúng thành xác suất của các kết quả có thể xảy ra (ví dụ: các lớp) được gọi là logits. Mặc dù logits đã được sử dụng từ thời các mô hình phân loại học máy cổ điển như hồi quy softmax, nguyên tắc tương tự vẫn áp dụng cho lớp tuyến tính cuối cùng của các mô hình transformer. Lớp cuối cùng này xử lý các trạng thái ẩn – chứa kiến thức ngôn ngữ được tích lũy dần dần về văn bản đầu vào được thu thập trong suốt transformer – và xuất ra một vector logits. Bao nhiêu? Bằng kích thước từ vựng của mô hình, tức là số lượng token có thể có mà mô hình có thể tạo ra.
Ví dụ, hãy xem sơ đồ ở trên cùng. Nếu một LLM được huấn luyện để dịch tiếng Anh sang tiếng Tây Ban Nha đang dự đoán từ tiếp theo sau chuỗi đã tạo "me gusta mucho" (bản dịch của "I really like to"), nó có thể xuất ra điểm logit thô là 12,5 cho "viajar" (du lịch), 8,2 cho "jugar" (chơi) và -3,1 cho "dormir" (ngủ). Các giá trị thô này không bị giới hạn, khiến chúng khó diễn giải trực tiếp; do đó, một hàm softmax được áp dụng trên lớp tuyến tính cuối cùng để biến đổi các logits này thành một phân phối xác suất chuẩn, có thể diễn giải trên các token từ vựng, sao cho tất cả các giá trị tổng bằng 1.
Temperature và Top-p là gì?
Khi có phân bố xác suất trên từ vựng mục tiêu, liệu các mô hình ngôn ngữ lớn (LLM) có đơn thuần chọn mã thông báo (token) có xác suất cao nhất làm mã thông báo tiếp theo để tạo ra hay không? Thực tế không hoàn toàn như vậy, nhưng quy trình thực tế rất gần với kịch bản đó. Mã thông báo tiếp theo được lấy mẫu từ phân bố, và cách lấy mẫu này hoạt động phụ thuộc vào một số tham số giải mã, trong đó hai tham số quan trọng nhất là nhiệt độ (temperature) và top-p.
Nhiệt độ là một hệ số tỷ lệ được áp dụng cho các logit trước bước softmax. Nhiệt độ cao (ví dụ: trên 1) làm phẳng các xác suất thu được, khiến chúng đồng đều hơn. Kết quả là, sự không chắc chắn và không thể đoán trước tăng lên, và mô hình hoạt động sáng tạo hơn. Nhiệt độ thấp (ví dụ: thấp hơn nhiều so với 1) làm sắc nét sự khác biệt giữa các mã thông báo có xác suất cao và thấp, tăng cường sự chắc chắn và ưu tiên mạnh mẽ các mã thông báo có khả năng xảy ra cao nhất trong phân bố gốc. Thông tin thêm về nhiệt độ có thể được tìm thấy trong bài viết liên quan này.
Top-p, còn được gọi là lấy mẫu hạt nhân (nucleus sampling), là một phương pháp khác để kiểm soát tính ngẫu nhiên của việc lựa chọn mã thông báo tiếp theo. Thay vì điều chỉnh xác suất, nó giới hạn tập hợp các ứng cử viên để lấy mẫu. Trong khi các chiến lược tương tự như top-k chỉ xem xét k mã thông báo có xác suất cao nhất, top-p xác định tập hợp nhỏ nhất các mã thông báo có xác suất tích lũy đạt hoặc vượt quá ngưỡng p, làm cho nó thích ứng và linh hoạt hơn. Nói cách khác, nếu chúng ta đặt p=0,9, top-p sắp xếp các mã thông báo theo xác suất và tiếp tục thêm chúng vào một nhóm ứng cử viên cho đến khi xác suất tích lũy của chúng đạt 0,9.
Quy trình đầy đủ: Các khái niệm này liên quan đến nhau như thế nào?
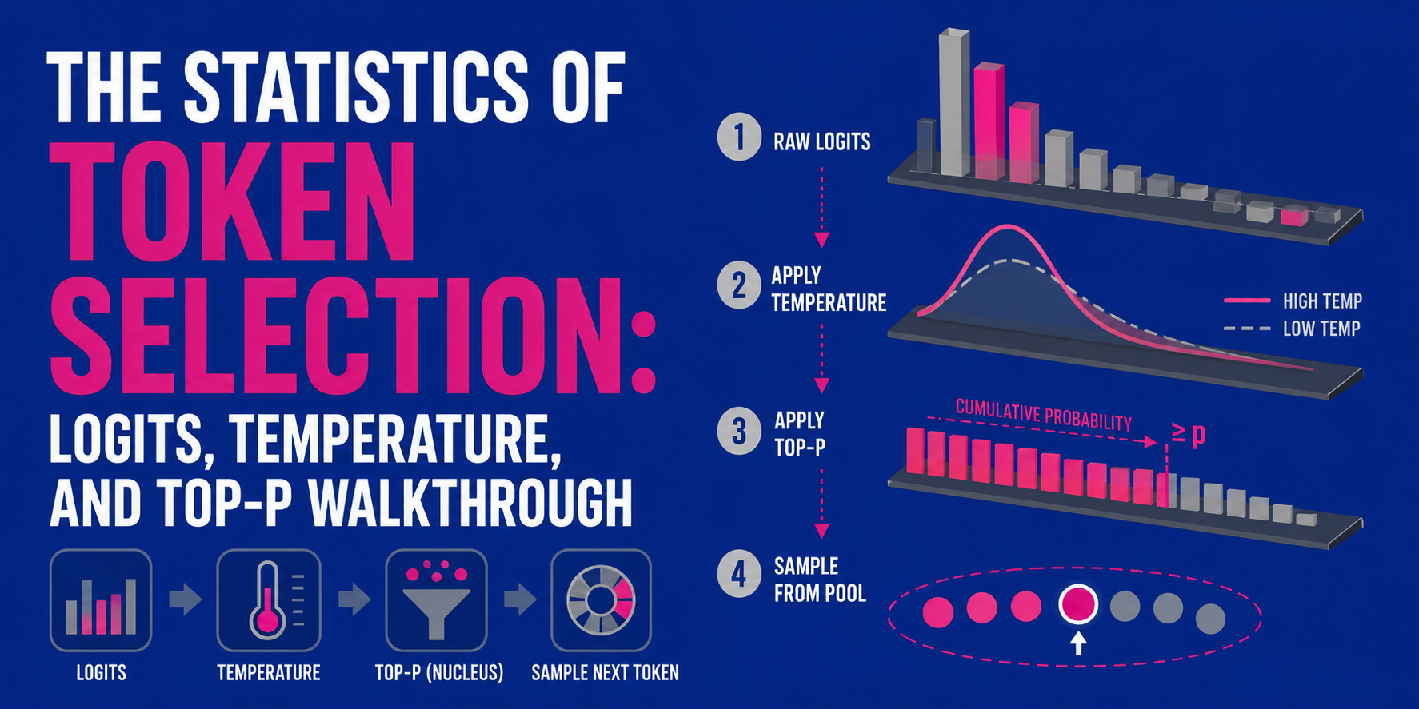
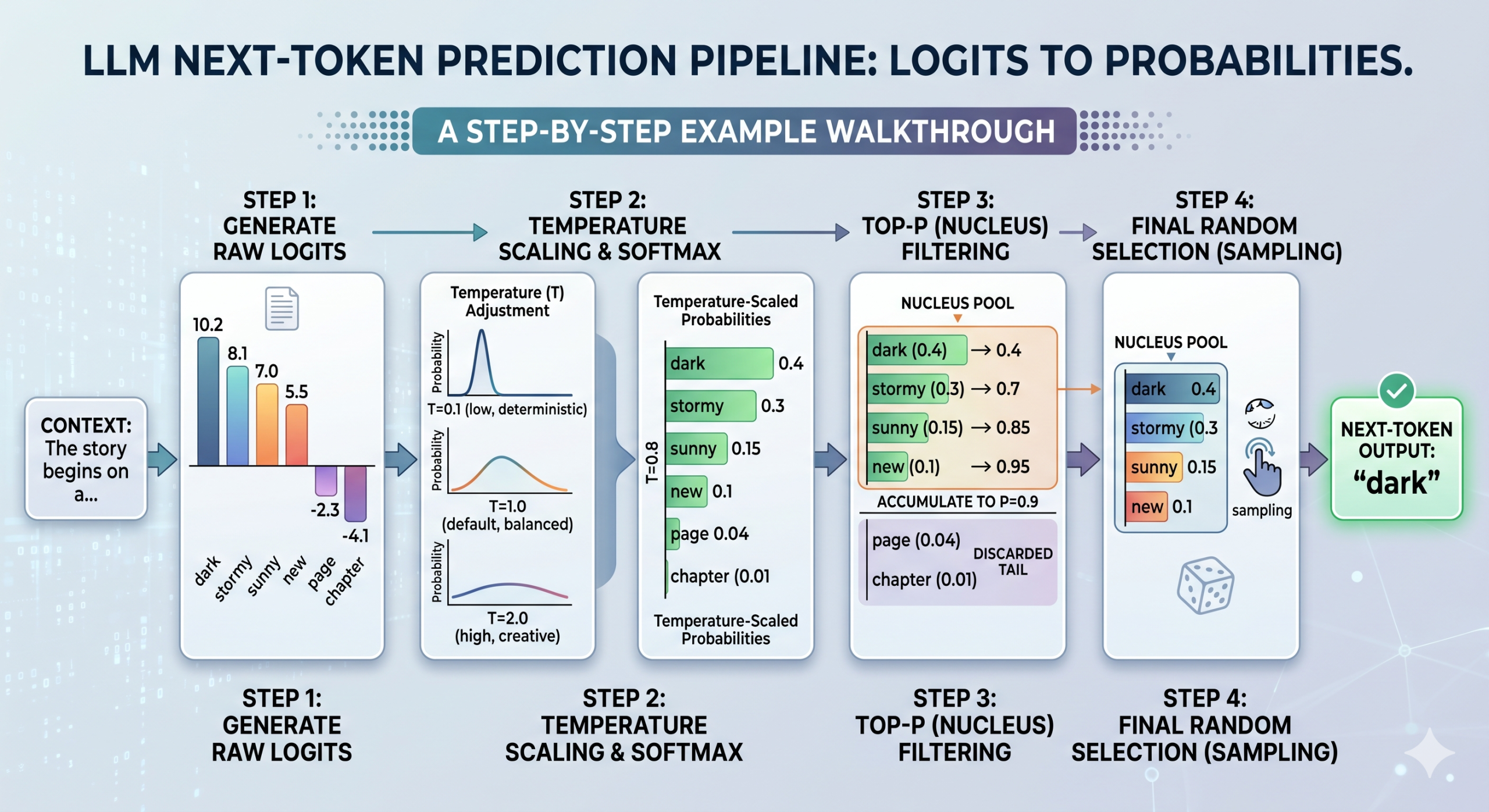
Tính toán logit thành xác suất, nhiệt độ và top-p có thể được kết hợp thành một quy trình nhiều bước tuần tự để tạo ra đầu ra của LLM, tức là dự đoán mã thông báo tiếp theo.
Đầu tiên, mô hình tạo ra các logit thô cho tất cả các mã thông báo có thể, như đã mô tả ở trên. Nhiệt độ sau đó xuất hiện bằng cách điều chỉnh các logit thô này — lưu ý rằng điều này xảy ra trước khi hàm softmax chuyển đổi chúng thành xác suất. Tùy thuộc vào giá trị nhiệt độ, phân bố kết quả sẽ trông đồng đều hơn (nhiệt độ cao, không chắc chắn hơn) hoặc sắc nét hơn (nhiệt độ thấp, chắc chắn hơn).
Quy trình lựa chọn mã thông báo dựa trên logit, nhiệt độ và top-p
Khi các logit đã được điều chỉnh được chuyển đổi thành xác suất, top-p được áp dụng để lọc phân bố kết quả, tính toán xác suất tích lũy để chỉ giữ lại một "nhóm hạt nhân" cốt lõi gồm các mã thông báo có khả năng xảy ra cao nhất (xem bước 3 trong hình trên). Cuối cùng, mô hình lấy mẫu ngẫu nhiên từ trong nhóm đó để chọn mã thông báo tiếp theo.
Lời kết
Bây giờ chúng ta đã làm rõ quy trình thống kê đằng sau việc lựa chọn mã thông báo trong LLM, việc xem xét cách thức là hữu ích.


Nguồn tin: Machine Learning Mastery — Tác giả: Iván Palomares Carrascosa. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.