Thiết kế hệ thống đa tác nhân hỗ trợ kỹ thuật ở quy mô lớn: Nghiên cứu điển hình từ Grab
Đội ngũ Dữ liệu Trung tâm của Grab đã xây dựng một hệ thống AI đa tác nhân nhằm tự động hóa các tác vụ hỗ trợ kỹ thuật lặp đi lặp lại trên nền tảng kho dữ liệu của mình. Hệ thống này tách biệt quy trình điều tra và cải tiến bằng cách sử dụng các tác nhân chuyên biệt được điều phối thông qua một lớp điều phối. Điều này giúp giảm tải vận hành, cải thiện tốc độ giải quyết vấn đề và chuyển hướng nỗ lực kỹ thuật từ việc xử lý sự cố sang công việc kỹ thuật nền tảng. Theo Leela Kumili
Trang chủ InfoQ
Tin tức
Thiết kế hệ thống đa tác nhân để hỗ trợ kỹ thuật ở quy mô lớn: Nghiên cứu điển hình từ Grab
Kiến trúc & Thiết kế
Thiết kế hệ thống đa tác nhân để hỗ trợ kỹ thuật ở quy mô lớn: Nghiên cứu điển hình từ Grab
Ngày 20/5/2026
2 phút đọc
Bởi
Leela Kumili
Viết cho InfoQ
Thỏa mãn sự tò mò của bạn.
Giúp hơn 550.000 nhà phát triển cấp cao trên toàn cầu
mỗi tháng luôn dẫn đầu. Liên hệ
Nghe bài viết này - 0:00
Âm thanh sẵn sàng phát
Trình duyệt của bạn không hỗ trợ phần tử âm thanh.
0:00
0:00
Bình thường 1.25x 1.5x
Thích
Danh sách đọc
Đội ngũ Kho dữ liệu phân tích (ADW) của Grab đã giới thiệu một hệ thống AI đa tác nhân để tự động hóa quy trình hỗ trợ kỹ thuật trên nền tảng dữ liệu quy mô lớn của mình, nhằm giảm thiểu công việc vận hành lặp đi lặp lại và nâng cao hiệu quả giải quyết vấn đề. Hệ thống này được thiết kế để xử lý các yêu cầu kỹ thuật nội bộ bao gồm khắc phục sự cố kho dữ liệu, gỡ lỗi SQL và hỗ trợ nền tảng, đồng thời chuyển hướng các kỹ sư sang các công việc phát triển có giá trị cao hơn.
Nền tảng ADW hỗ trợ hơn 1.000 người dùng nội bộ và quản lý hơn 15.000 bảng, đóng vai trò là thành phần cơ sở hạ tầng phân tích cốt lõi trong Grab. Khi mức độ sử dụng tăng lên, đội ngũ kỹ thuật nhận thấy rằng một phần đáng kể nỗ lực vận hành bị tiêu tốn vào các tác vụ hỗ trợ lặp đi lặp lại và các cuộc điều tra đặc biệt, hạn chế thời gian dành cho việc cải thiện nền tảng và công việc thiết kế hệ thống.
Ông Sneh Agrawal, Trưởng bộ phận Phân tích tại Grab, đã nhấn mạnh trong một bài đăng trên LinkedIn:
Đội ngũ Dữ liệu Trung tâm của Grab đang tận dụng một hệ thống đa tác nhân để tự động hóa công việc vận hành lặp đi lặp lại, giúp tiết kiệm hàng trăm giờ kỹ thuật mỗi tháng. Sự thay đổi này đang giải phóng băng thông kỹ thuật quan trọng và cho phép chuyển đổi từ việc ứng phó sự cố sang xây dựng hệ thống có giá trị cao hơn.
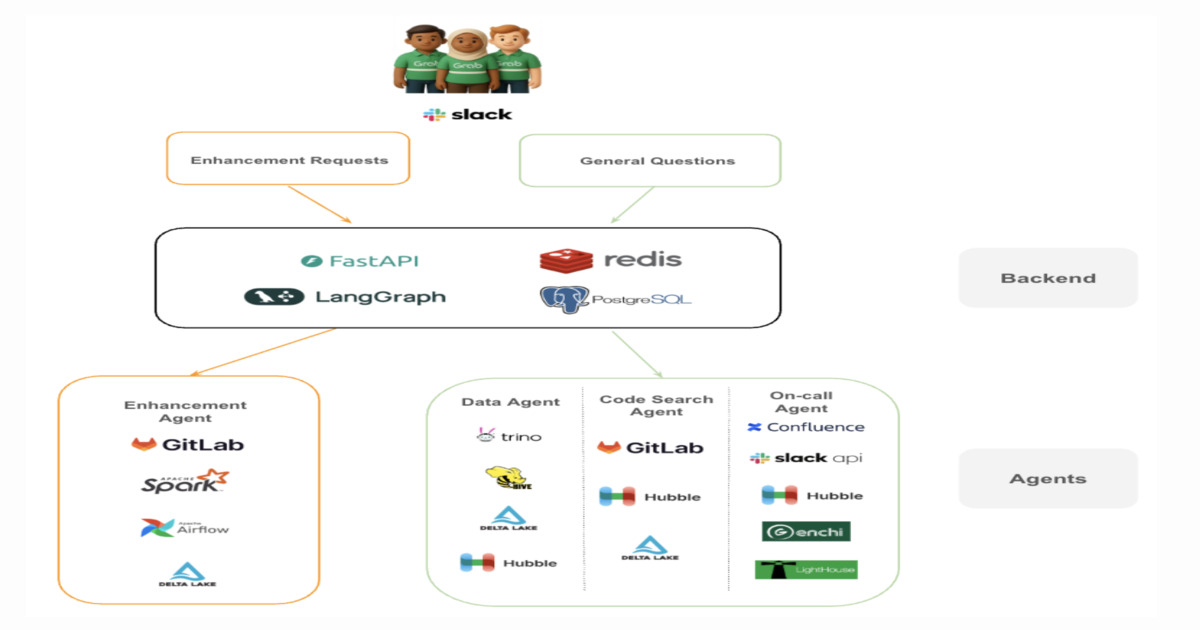
Để giải quyết vấn đề này, đội ngũ đã triển khai kiến trúc đa tác nhân phân tách các yêu cầu kỹ thuật đến thành hai quy trình chính: điều tra và cải tiến. Quy trình điều tra được thiết kế cho các tác vụ chẩn đoán như phân tích truy vấn, truy xuất nhật ký, tra cứu lược đồ và tóm tắt vấn đề. Quy trình cải tiến tập trung vào việc tạo ra các kết quả có thể hành động, bao gồm thay đổi mã, sửa lỗi SQL và yêu cầu hợp nhất tự động để xem xét.
Ngăn xếp công nghệ kiến trúc đa tác nhân (Nguồn: Bài đăng trên Blog Công nghệ của Grab)
Hệ thống được điều phối bằng công cụ quy trình làm việc dựa trên LangGraph kết hợp với các dịch vụ FastAPI điều phối định tuyến, thực thi công cụ và quản lý trạng thái giữa các tác nhân. Các yêu cầu được phân loại trước, sau đó được định tuyến đến các tác nhân chuyên biệt chịu trách nhiệm cho các tác vụ như truy xuất ngữ cảnh, tìm kiếm mã hoặc tạo giải pháp. Mỗi tác nhân hoạt động với các trách nhiệm giới hạn để giảm sự mơ hồ và cải thiện khả năng dự đoán của các kết quả đầu ra.
Quy trình làm việc của tác nhân, sử dụng một Giám sát viên (Supervisor) kiểm soát luồng giao tiếp và phân công nhiệm vụ (Nguồn: Bài đăng trên Blog Công nghệ của Grab).
Theo các kỹ sư của Grab,
Việc tách biệt các lộ trình điều tra và cải tiến đã giúp chúng tôi giảm độ phức tạp trong lập luận của tác nhân và cải thiện độ tin cậy trong các quy trình làm việc sản xuất.
Một quyết định kiến trúc quan trọng là hợp nhất hệ sinh thái công cụ. Ban đầu, hệ thống cung cấp hơn 30 công cụ nội bộ trên các hệ thống truy cập dữ liệu, ghi nhật ký và mã. Sau đó, số lượng này được giảm xuống một bộ công cụ nhỏ hơn, được quản lý chặt chẽ để cải thiện khả năng bảo trì và giảm việc lựa chọn công cụ không thể đoán trước của các tác nhân. Lớp công cụ bao gồm thực thi SQL được kiểm soát, truy cập siêu dữ liệu, hệ thống truy xuất nhật ký và tích hợp với các quy trình làm việc dựa trên Git để quản lý thay đổi.
An toàn và quản trị đã được tích hợp vào thiết kế hệ thống. Việc thực thi SQL bị hạn chế thông qua các lớp xác thực, và việc xử lý dữ liệu nhạy cảm bao gồm các cơ chế phát hiện và giảm thiểu rủi ro phơi nhiễm. Ngoài ra, tất cả các quy trình làm việc cải tiến tạo ra thay đổi mã đều yêu cầu đánh giá bởi con người trước khi triển khai, đảm bảo rằng các kết quả tự động vẫn chịu sự giám sát của kỹ sư.
Quản lý ngữ cảnh nổi lên như một thách thức kỹ thuật đáng kể. Lập luận của tác nhân nhiều bước yêu cầu duy trì trạng thái liên quan qua các tương tác trong khi vẫn hoạt động trong giới hạn token. Hệ thống giải quyết vấn đề này thông qua nén ngữ cảnh có cấu trúc và các chiến lược truy xuất chọn lọc, cho phép các tác nhân giữ lại thông tin cần thiết mà không vượt quá giới hạn hoạt động.
Tác động của hệ thống đã được ghi nhận qua việc giảm thời gian dành cho các tác vụ hỗ trợ kỹ thuật thường xuyên và chu kỳ giải quyết nhanh hơn cho các vấn đề phổ biến. Mặc dù các số liệu hiệu suất chính xác không được tiết lộ, nhóm đã ghi nhận sự chuyển dịch trong nỗ lực kỹ thuật từ việc "chữa cháy" sang kỹ thuật nền tảng và cải thiện hệ thống.
/filters:no_upscale()/news/2026/05/grab-multi-agent-support-system/en/resources/1grabtechmultiagentarch-1778993206295.jpeg)
/filters:no_upscale()/news/2026/05/grab-multi-agent-support-system/en/resources/1grabagentworkflow-1778993206295.jpeg)
Nguồn tin: InfoQ AI — Tác giả: Leela Kumili. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.