StepFun, phòng thí nghiệm AI có trụ sở tại Thượng Hải, đã phát hành StepAudio 2.5 Realtime. Đây là mô hình ngôn ngữ lớn (LLM) giọng nói thời gian thực đầu cuối với khả năng cá nhân hóa hoàn toàn.
StepAudio 2.5 Realtime là một mô hình giọng nói hoạt động trong thời gian thực. Không giống như các hệ thống dựa trên đường ống (pipeline-based systems) tách biệt nhận dạng giọng nói, suy luận và tổng hợp thành các bước tuần tự, đây là một mô hình đầu cuối. Âm thanh đầu vào và âm thanh đầu ra được xử lý thông qua một hệ thống thống nhất duy nhất. Mô hình này hỗ trợ tiếng Trung và tiếng Anh.
Mô hình kết nối thông qua một API WebSocket. Điểm cuối (endpoint) là wss://api.stepfun.com/v1/realtime sử dụng chuỗi mô hình "st".
StepFun, phòng thí nghiệm AI có trụ sở tại Thượng Hải, đã phát hành StepAudio 2.5 Realtime. Đây là một mô hình ngôn ngữ lớn (LLM) giọng nói thời gian thực đầu cuối với khả năng cá nhân hóa hoàn toàn tùy chỉnh.
StepAudio 2.5 Realtime là một mô hình giọng nói hoạt động theo thời gian thực. Không giống như các hệ thống dựa trên đường ống (pipeline-based systems) tách biệt nhận dạng giọng nói, suy luận và tổng hợp thành các bước tuần tự, đây là một mô hình đầu cuối. Âm thanh đầu vào và âm thanh đầu ra được xử lý thông qua một hệ thống thống nhất duy nhất. Mô hình hỗ trợ tiếng Trung và tiếng Anh.
Mô hình kết nối thông qua API WebSocket. Điểm cuối là wss://api.stepfun.com/v1/realtime sử dụng chuỗi mô hình step-2.5-realtime.
Ba trụ cột kỹ thuật
Nhóm nghiên cứu StepFun mô tả ba đổi mới kiến trúc cốt lõi đằng sau mô hình:
1. Tăng cường dữ liệu cá nhân hóa quy mô triệu
Bắt đầu từ hơn 10.000 cá nhân hóa chất lượng cao được tạo ra nguyên bản, StepFun đã áp dụng thuật toán tăng cường để xây dựng ma trận tính năng cá nhân hóa quy mô triệu. Điều này được kết hợp với hàng triệu mẫu hội thoại thực tế để đào tạo. Mục đích là khái quát hóa – cụ thể là hiệu suất ổn định trên các chủ đề hội thoại khó, có đuôi dài (long-tail conversational topics).
Thay vì gắn nhãn thủ công hàng triệu mẫu cá nhân hóa, nhóm StepFun đã sử dụng mở rộng thuật toán từ một tập hợp hạt giống được tuyển chọn.
2. Căn chỉnh RLHF (Học tăng cường từ phản hồi của con người) dành riêng cho nhập vai
Một chế độ lỗi được biết đến trong AI đàm thoại là hành vi "lệch vai" (out-of-character - OOC) – khi một mô hình đi chệch khỏi cá tính đã xác định của nó giữa cuộc trò chuyện. Nhóm StepFun đã thực hiện tối ưu hóa RLHF (Học tăng cường từ phản hồi của con người) chuyên biệt cho tính nhất quán của cá tính trong các tình huống nhập vai. RLHF là một kỹ thuật đào tạo trong đó các tín hiệu ưu tiên của con người được sử dụng để đào tạo một mô hình phần thưởng, sau đó hướng dẫn hành vi của mô hình ngôn ngữ. Việc áp dụng nó cụ thể cho sự ổn định nhập vai là một lựa chọn thiết kế có mục tiêu.
3. Hiểu và tạo giọng nói thống nhất
StepAudio 2.5 Realtime kế thừa khả năng TTS (Text-to-Speech) của StepAudio 2.5 và tích hợp sâu sắc hiểu và tạo giọng nói thông qua học tăng cường. Điều này cho phép cái mà StepFun gọi là "thiết lập tông giọng cấp độ cảnh toàn cầu" và "điêu khắc chi tiết trong câu". Mô hình có thể thiết lập một đăng ký cảm xúc tổng thể cho một phản hồi trong khi điều chỉnh các chi tiết âm thanh tinh tế hơn trong từng câu riêng lẻ.
Hiểu biết về phi ngôn ngữ
Một lĩnh vực kỹ thuật khác biệt của mô hình này là nhận thức phi ngôn ngữ. Phi ngôn ngữ đề cập đến thông tin âm thanh phi lời nói trong giọng nói – những thứ như tông giọng, tốc độ nói, tạm dừng, thở dài và tiếng cười. Bằng cách phân tích các yếu tố này, mô hình có thể nhận biết tâm trạng và ý định tiềm ẩn của người dùng. Ví dụ, nó có thể xác định sự mệt mỏi từ tông giọng thấp hoặc sự thất vọng từ tốc độ nói nhanh. Việc nắm bắt các tín hiệu này đòi hỏi mô hình phải hoạt động trên các tính năng âm thanh chứ không chỉ văn bản được phiên âm.
StepAudio 2.5 Realtime đạt 82,18 điểm trên tiêu chuẩn hiểu biết phi ngôn ngữ, thể hiện khả năng nhận biết tốc độ giọng nói, cảm xúc, tuổi tác và các tính năng âm thanh khác.
https://stepaudiollm.github.io/step-audio-2.5-realtime/
Kết quả đánh giá
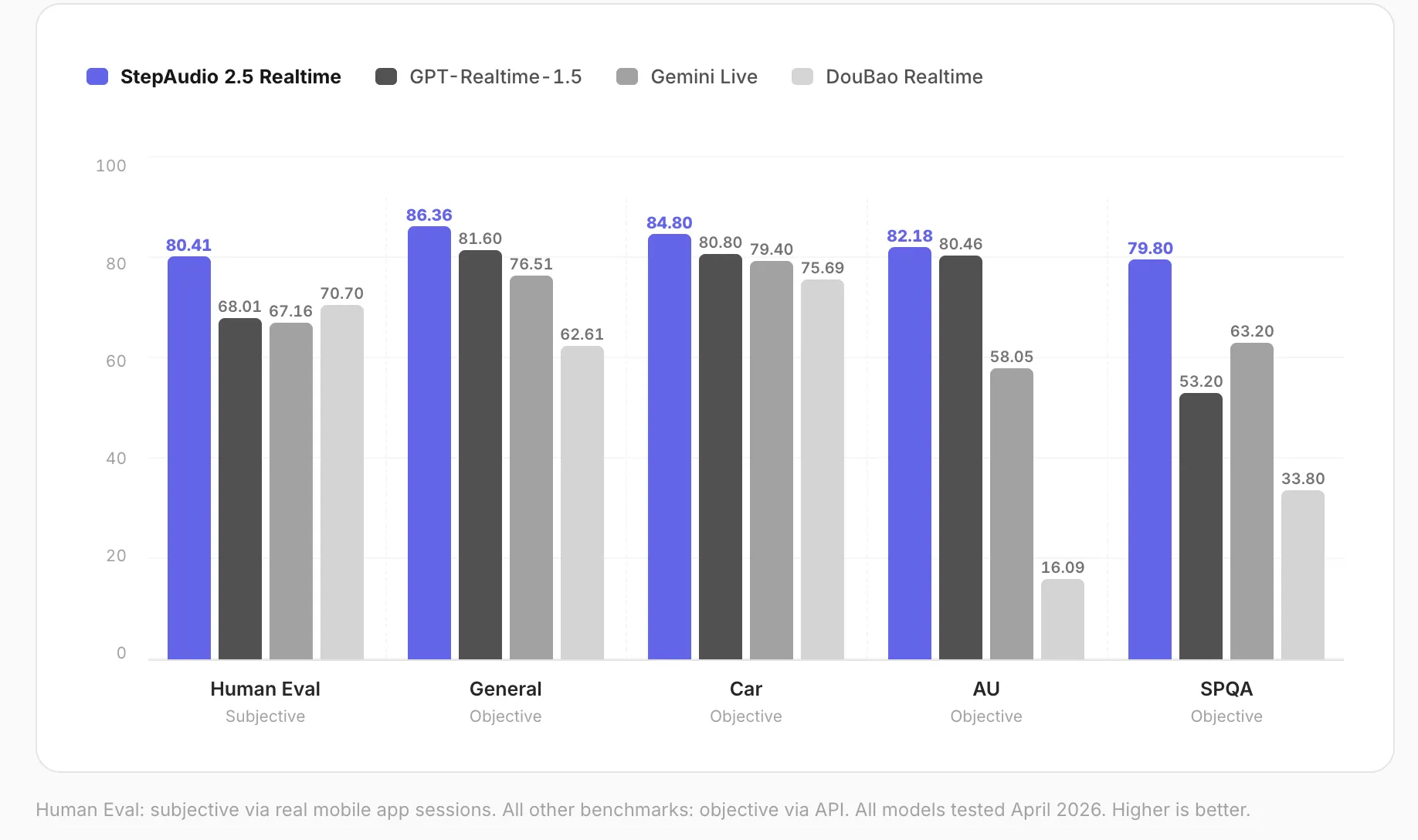
Nhóm nghiên cứu StepFun đã tiến hành một bộ đánh giá toàn diện về chủ quan và khách quan, so sánh StepAudio 2.5 Realtime với các mô hình giọng nói thời gian thực hàng đầu trên năm khía cạnh.
Đánh giá của con người được thực hiện thông qua các cuộc hội thoại ứng dụng di động thực tế được chấm điểm bởi người đánh giá. Các điểm số:
Đánh giá của con người (chủ quan): 80,41
Đối thoại chung (khách quan): 86,36
Kịch bản ô tô (khách quan): 84,80
Spoken QA, bao gồm 11 tác vụ hiểu âm thanh (khách quan): 79,80
Hiểu ngôn ngữ cận biên (khách quan): 82,18
Những điểm chính
StepAudio 2.5 Realtime là một mô hình ngôn ngữ lớn (LLM) giọng nói thời gian thực đầu cuối, được phát hành bởi StepFun có trụ sở tại Thượng Hải.
Mô hình sử dụng RLHF (Reinforcement Learning from Human Feedback - Học tăng cường từ phản hồi của con người) dành riêng cho từng cá nhân và tăng cường dữ liệu quy mô hàng triệu để duy trì tính nhất quán ổn định của nhân vật.
Mô hình xếp hạng đầu tiên trên cả năm tiêu chí đánh giá, được thử nghiệm vào tháng 4 năm 2026.
Hiểu ngôn ngữ cận biên — nhận biết giọng điệu, tốc độ, cảm xúc từ âm thanh — là một yếu tố kỹ thuật khác biệt cốt lõi.
Truy cập API thông qua WebSocket tại wss://api.stepfun.com/v1/realtime với chuỗi mô hình step-2.5-realtime.
Hãy xem Thẻ mô hình (Model Card) và Bản thử nghiệm (Demo). Ngoài ra, bạn có thể theo dõi chúng tôi trên Twitter và đừng quên tham gia Cộng đồng Reddit về Học máy (ML SubReddit) với hơn 150.000 thành viên của chúng tôi và Đăng ký nhận Bản tin (Newsletter) của chúng tôi. Bạn có sử dụng Telegram không? Giờ đây bạn cũng có thể tham gia cùng chúng tôi trên Telegram.
Cần hợp tác với chúng tôi để quảng bá Kho lưu trữ GitHub (GitHub Repo) HOẶC Trang Hugging Face HOẶC Phát hành sản phẩm HOẶC Hội thảo trực tuyến (Webinar) của bạn, v.v.? Hãy liên hệ với chúng tôi.
Bài viết StepFun phát hành StepAudio 2.5 Realtime: Một mô hình giọng nói đầu cuối với RLHF dành riêng cho nhập vai và khả năng hiểu ngôn ngữ cận biên xuất hiện lần đầu trên MarkTechPost.
Nguồn tin: MarkTechPost — Tác giả: Michal Sutter. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.