Stability AI đã phát hành các trọng số mở (open weights) cho Stable Audio 3 cùng với một báo cáo nghiên cứu kỹ thuật. Stable Audio 3 là một dòng mô hình khuếch tán tiềm ẩn (latent diffusion models) tạo ra âm thanh stereo ở tần số 44,1 kHz. Các mô hình này hỗ trợ đầu ra có độ dài thay đổi, chỉnh sửa dựa trên inpainting (điền vào chỗ trống) và suy luận nhanh.
Stable Audio 3 là gì?
Stable Audio 3 là một dòng gồm ba quy mô mô hình: nhỏ, trung bình và lớn. Một mô hình khuếch tán tiềm ẩn tạo ra âm thanh bằng cách học cách loại bỏ dần nhiễu từ một biểu diễn âm thanh đã nén, được gọi là tiềm ẩn (latent). Mô hình học một ánh xạ từ nhiễu đến dữ liệu bằng cách huấn luyện trên nhiều (nhiễu l
Stability AI đã phát hành mã nguồn mở (open weights) cho Stable Audio 3 cùng với một báo cáo nghiên cứu kỹ thuật. Stable Audio 3 là một dòng mô hình khuếch tán tiềm ẩn (latent diffusion models) tạo ra âm thanh stereo ở tần số 44,1 kHz. Các mô hình này hỗ trợ đầu ra có độ dài thay đổi, chỉnh sửa dựa trên inpainting và suy luận nhanh.
Stable Audio 3 là gì?
Stable Audio 3 là một dòng gồm ba quy mô mô hình: nhỏ, trung bình và lớn. Một mô hình khuếch tán tiềm ẩn tạo ra âm thanh bằng cách học cách loại bỏ dần nhiễu khỏi một biểu diễn nén của âm thanh, được gọi là tiềm ẩn (latent). Mô hình học một ánh xạ từ nhiễu đến dữ liệu bằng cách huấn luyện trên nhiều cặp (tiềm ẩn nhiễu, âm thanh).
Ba quy mô mô hình khác nhau về dung lượng và độ dài tạo tối đa. Tất cả các số lượng tham số dưới đây chỉ dành cho thành phần biến đổi khuếch tán (diffusion transformer). Mỗi mô hình cũng bao gồm một bộ mã hóa tự động SAME (108M tham số cho SAME-S, 852M cho SAME-L).
small-music — 459M tham số biến đổi khuếch tán, tối đa 2 phút, chỉ nhạc.
small-sfx — 459M tham số biến đổi khuếch tán, tối đa 2 phút, chỉ hiệu ứng âm thanh.
medium — 1,4B tham số biến đổi khuếch tán, tối đa 6 phút 20 giây, nhạc và hiệu ứng âm thanh.
large — 2,7B tham số biến đổi khuếch tán, tối đa 6 phút 20 giây, nhạc và hiệu ứng âm thanh.
Mã nguồn mở cho các mô hình nhỏ và trung bình có sẵn trên Hugging Face. Mô hình lớn có sẵn theo giấy phép doanh nghiệp.
Kiến trúc: Hai thành phần
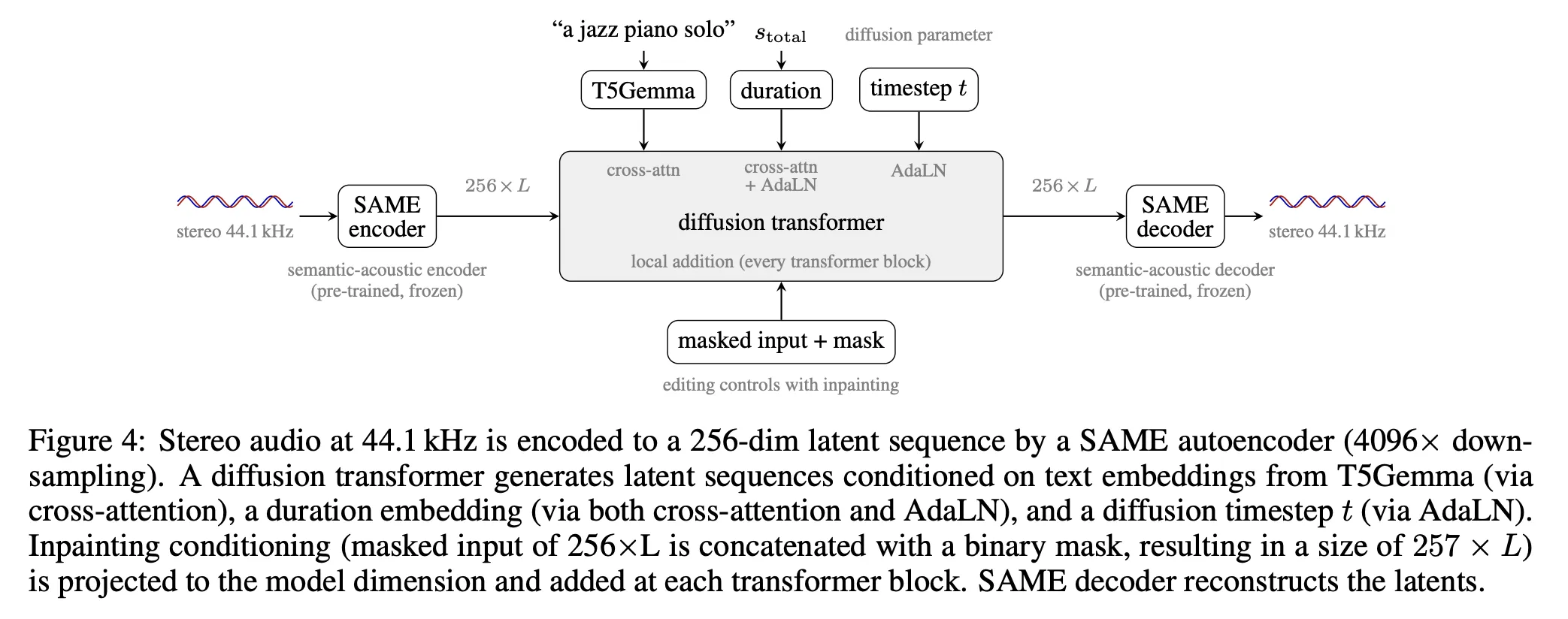
Stable Audio 3 có hai thành phần chính: một bộ mã hóa tự động ngữ nghĩa-âm thanh (semantic-acoustic autoencoder) có tên SAME, và một biến đổi khuếch tán (diffusion transformer) tạo ra các chuỗi tiềm ẩn được điều kiện hóa theo văn bản, thời lượng và mặt nạ inpainting.
https://arxiv.org/pdf/2605.17991
Bộ mã hóa tự động SAME
SAME (Semantically-Aligned Music autoEncoder) chuyển đổi âm thanh stereo 44,1 kHz thành một biểu diễn tiềm ẩn nhỏ gọn và ngược lại. Tham số thiết kế chính của nó là tỷ lệ lấy mẫu giảm 4096× — cao hơn đáng kể so với tỷ lệ 1024× đến 2048× thường thấy trong các bộ mã hóa tự động âm thanh trước đây. Tỷ lệ cao hơn này làm giảm độ dài chuỗi tiềm ẩn đủ để tạo ra các dạng dài chạy trên phần cứng tiêu dùng.
SAME đạt được khả năng nén 4096× thông qua hai giai đoạn. Đầu tiên, giai đoạn vá (patching stage) định hình lại âm thanh stereo thành các bản vá không chồng chéo gồm 256 mẫu trên mỗi kênh, đạt được khả năng lấy mẫu giảm 256×. Thứ hai, một khối lấy mẫu lại biến đổi (Transformer Resampling Block - TRB) áp dụng thêm khả năng lấy mẫu giảm 16× bằng cách sử dụng các nhúng đầu ra có thể học được xen kẽ với chuỗi đầu vào, được xử lý thông qua một biến đổi. Đầu ra kết hợp là một chuỗi tiềm ẩn 256 chiều ở khoảng 10,76 Hz cho đầu vào 44,1 kHz.
Bộ mã hóa tự động SAME được huấn luyện với năm loại hàm mất mát: tái tạo phổ, đối kháng, căn chỉnh khuếch tán, hồi quy ngữ nghĩa (dự đoán sắc độ và sự khác biệt mức độ giữa hai tai), và căn chỉnh tiềm ẩn tương phản. Các hàm mất mát này thúc đẩy tiềm ẩn duy trì cả chất lượng tái tạo âm thanh và cấu trúc ngữ nghĩa. Một nút cổ chai chuẩn hóa mềm (soft-normalisation bottleneck) giới hạn quy mô của tiềm ẩn, cung cấp mã hóa xác định.
Bộ mã hóa tự động SAME được đóng băng trong quá trình huấn luyện khuếch tán. Các mô hình nhỏ sử dụng SAME-S (108M tham số, được tối ưu hóa cho suy luận CPU); các mô hình trung bình và lớn sử dụng SAME-L (852M tham số).
Biến đổi khuếch tán
Biến đổi khuếch tán hoạt động trên các tiềm ẩn SAME. Điều kiện hóa đi vào thông qua ba đường dẫn:
Văn bản — một bộ mã hóa T5Gemma đóng băng tạo ra một chuỗi 256 nhúng có kích thước 768. Các lời nhắc ngắn được đệm đến 256 bằng một nhúng đã học; các lời nhắc dài bị cắt bớt.
Thời lượng – được mã hóa dưới dạng vectơ đặc trưng Fourier và được đưa vào thông qua cả Chuẩn hóa lớp thích ứng (AdaLN) và cơ chế chú ý chéo cùng với lời nhắc văn bản.
Nội suy (Inpainting) – một mặt nạ nhị phân được nối với âm thanh tham chiếu đã được che giấu, sau đó được chiếu qua một MLP 2 lớp và thêm vào luồng dư của mỗi khối biến đổi (transformer block).
Mỗi khối biến đổi chứa cơ chế tự chú ý (self-attention), chú ý chéo (cross-attention), điều kiện bổ sung cục bộ cho nội suy, và mạng truyền thẳng SwiGLU. Các mô hình cỡ trung bình và lớn sử dụng cơ chế chú ý vi phân (differential attention), tính toán hai bản đồ chú ý riêng biệt bằng cách sử dụng hai cặp (Q, K) chia sẻ một tập hợp giá trị V, sau đó trừ một bản đồ khỏi bản đồ kia. Điều này giúp loại bỏ các mẫu chú ý phổ biến cho cả hai đầu. Bộ biến đổi thêm 64 nhúng bộ nhớ có thể học được vào trước khi xử lý mỗi chuỗi. Những nhúng này cung cấp một bộ đệm ngữ cảnh toàn cục mà mọi vị trí có thể chú ý đến, và được loại bỏ trước khi tính toán bất kỳ tổn thất nào.
Tạo sinh độ dài biến đổi
Hầu hết các mô hình khuếch tán tiềm ẩn trước đây cho âm thanh hoạt động ở độ dài chuỗi tối đa cố định. Việc tạo ra một đoạn âm thanh ngắn vẫn yêu cầu chạy suy luận ở độ dài đầy đủ, gây lãng phí tài nguyên tính toán cho sự im lặng. Stable Audio 3 được huấn luyện để tạo ra âm thanh với độ dài biến đổi một cách tự nhiên, sử dụng ba cơ chế:
Cơ chế chú ý flash độ dài biến đổi và tổn thất được che giấu – các chuỗi ngắn hơn độ dài tối đa của lô được đệm bên phải trong không gian tiềm ẩn. Các vị trí đệm được loại trừ khỏi cơ chế tự chú ý và khỏi tổn thất.
Dịch chuyển thời gian theo từng phần tử – các chuỗi dài hơn giữ lại nhiều cấu trúc hơn ở một mức độ nhiễu nhất định do sự dư thừa giữa các phần tử lân cận. Để bù đắp, lịch trình nhiễu được dịch chuyển về phía mức độ nhiễu cao hơn cho các chuỗi dài hơn trong quá trình huấn luyện, sử dụng một dịch chuyển logistic được tham số hóa bởi µ (nội suy giữa µmin=0,5 và µmax=1,15 dựa trên độ dài chuỗi).
Tăng cường sự im lặng – vùng tín hiệu được mở rộng ngẫu nhiên với các nhúng im lặng đã được tính toán trước, được lấy từ một phân phối mũ, trung bình 4 giây. Điều này giúp mô hình học cách kết thúc âm thanh bằng sự im lặng tự nhiên.
Kết quả thực tế là chi phí suy luận tỷ lệ thuận với thời lượng đầu ra. Mô hình cỡ trung bình tạo ra 20 giây âm thanh trong khoảng 0,62 giây trên H200. Tạo ra 380 giây mất 1,31 giây trên cùng phần cứng.
Quy trình huấn luyện ba giai đoạn
Giai đoạn 1 – Huấn luyện trước khớp luồng (Flow Matching Pre-Training). Mô hình học một trường vận tốc chuyển nhiễu Gaussian về phía các tiềm ẩn âm thanh. Huấn luyện sử dụng khớp nối vận chuyển tối ưu theo lô nhỏ thông qua các lần lặp Sinkhorn, ghép mỗi mẫu dữ liệu với vectơ nhiễu gần nhất có sẵn trong lô. Điều này làm thẳng các quỹ đạo huấn luyện và
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.