Hầu hết các lỗi của mô hình ngôn ngữ lớn (LLM) hoạt động lâu dài không phải là lỗi suy luận thuần túy. Đó là các lỗi chọn trạng thái: lệnh gọi mô hình tiếp theo nhận được ngữ cảnh không đầy đủ, lỗi thời hoặc không liên quan.
Trong các cuộc trò chuyện ngắn, việc thêm các tin nhắn gần đây thường hiệu quả. Trong các phiên liên tục, điều đó không còn hiệu quả vì các sự kiện bền vững biến mất, các cập nhật lỗi thời quay trở lại và lưu lượng truy cập thông thường tiêu tốn ngân sách lời nhắc (prompt budget).
Câu hỏi thực sự đặt ra là:
Những phần nào của trạng thái trước đó xứng đáng được đưa vào lệnh gọi mô hình tiếp theo?
Tôi đã xây dựng LLM-Context-Optimization-Engine để khám phá câu hỏi đó. Đây là một nguyên mẫu so sánh toàn bộ lịch sử, cửa sổ trượt (sliding windows), tóm tắt, truy xuất.
Hầu hết các lỗi của mô hình ngôn ngữ lớn (LLM) chạy dài không phải là lỗi suy luận thuần túy. Đó là các lỗi chọn trạng thái: lần gọi mô hình tiếp theo nhận được ngữ cảnh không đầy đủ, lỗi thời hoặc không liên quan.
Trong các cuộc trò chuyện ngắn, việc thêm các tin nhắn gần đây thường hiệu quả. Trong các phiên liên tục, điều đó sẽ không còn hiệu quả vì các sự kiện bền vững biến mất, các cập nhật lỗi thời quay trở lại và lưu lượng truy cập thông thường tiêu tốn ngân sách lời nhắc.
Câu hỏi thực sự trở thành:
Những phần trạng thái trước đó nào xứng đáng được đưa vào lần gọi mô hình tiếp theo?
Tôi đã xây dựng LLM-Context-Optimization-Engine để khám phá câu hỏi đó. Đây là một nguyên mẫu so sánh toàn bộ lịch sử, cửa sổ trượt, tóm tắt, truy xuất, ngữ cảnh lai, lựa chọn ngữ cảnh thích ứng và lưu giữ bộ nhớ dựa trên mức độ quan trọng.
Đóng góp ở đây không phải là một kiến trúc bộ nhớ mới. Đó là một công cụ kiểm tra có thể kiểm tra được, so sánh các chính sách ngữ cảnh trước khi gọi mô hình và cho thấy cách mỗi chính sách thất bại.
Vấn đề này ngày càng trở nên quan trọng khi các nền tảng tác nhân hướng tới bộ nhớ liên tục. Một khi các tác nhân có thể ghi nhớ qua các phiên, câu hỏi khó không phải là liệu bộ nhớ có tồn tại hay không, mà là cách trạng thái được lưu trữ được chọn, vô hiệu hóa, tin cậy và đưa vào tại thời điểm suy luận.
Phiên bản ngắn gọn:
Cửa sổ trượt rẻ tiền, nhưng chúng quên đi các sự kiện bền vững.
Toàn bộ lịch sử tối đa hóa khả năng gợi nhớ, nhưng mang theo bằng chứng lỗi thời và nhiễu.
Truy xuất cải thiện khả năng gợi nhớ, nhưng khả năng gợi nhớ cao vẫn có thể làm hỏng lời nhắc nếu các sự kiện lỗi thời đi kèm với nó.
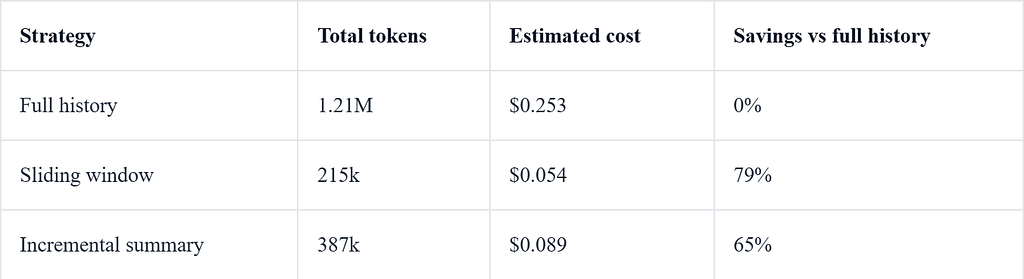
Trong một thử nghiệm tổng hợp 10.000 lượt, lựa chọn dựa trên mức độ quan trọng đã giữ lại 90,7% các sự kiện quan trọng hiện tại trong ngân sách 600 tin nhắn; cửa sổ trượt giữ lại 10,8%.
Bài học chính: các ứng dụng LLM chạy dài cần chính sách bộ nhớ, không chỉ lưu trữ bộ nhớ.
Điều này không tuyên bố giải quyết bộ nhớ dài hạn. Nó cung cấp một công cụ kiểm tra có kiểm soát để so sánh các chính sách ngữ cảnh và kiểm tra cách chúng thất bại dưới ngân sách lời nhắc hạn chế.
Tại sao các ứng dụng LLM chạy dài thất bại
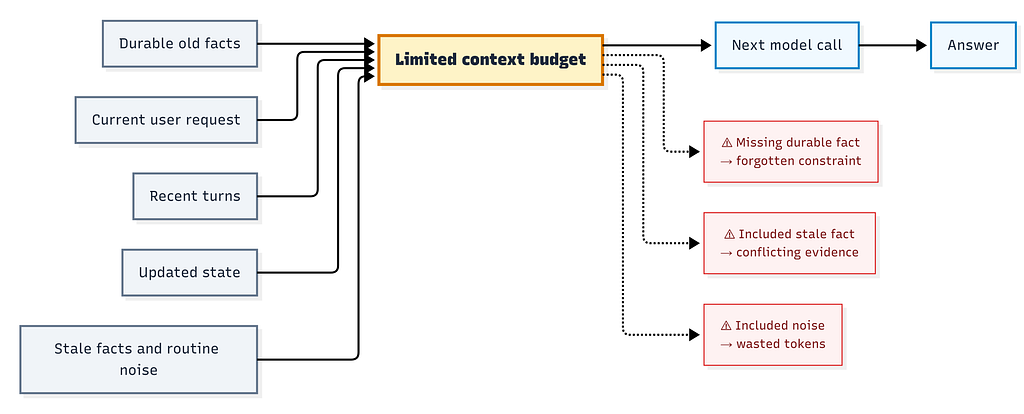
Trước khi đi vào triển khai, vấn đề cốt lõi là các loại trạng thái khác nhau cạnh tranh cho cùng một ngân sách lời nhắc hạn chế.
Các ứng dụng LLM chạy dài không chỉ cần nhiều bộ nhớ hơn. Chúng cần một chính sách để quyết định trạng thái nào sẽ nhập cho lần gọi mô hình tiếp theo. Cũ không có nghĩa là không liên quan. Gần đây không có nghĩa là đủ.
Một tùy chọn của người dùng từ 200 lượt trước có thể quan trọng hơn một tin nhắn thông thường gần đây. Một bản cập nhật gần đây có thể làm mất hiệu lực một sự kiện cũ hơn. Một bộ nhớ được truy xuất có thể liên quan và vẫn nguy hiểm nếu nó mang theo bằng chứng lỗi thời.
Đó là lý do tại sao các hệ thống LLM chạy dài cần chính sách ngữ cảnh, không chỉ lưu trữ ngữ cảnh.
Một ví dụ thất bại cụ thể
Hãy tưởng tượng một phiên trợ lý chạy dài để lập kế hoạch dự án.
Đầu phiên:
Lượt 18: Tùy chọn bữa trưa ưa thích của người dùng cho các buổi họp ngoài là ăn chay.
Sau đó:
Lượt 142: Tùy chọn cập nhật: người dùng hiện là người ăn chay trường, không chỉ ăn chay.
Sau đó nữa:
Lượt 260: Khởi chạy Dự án Atlas chuyển từ thứ Tư sang thứ Sáu.
Tại lượt 310, người dùng hỏi:
Bạn có thể lên kế hoạch bữa trưa ra mắt Atlas vào thứ Sáu không?
Bằng chứng cần thiết cho câu trả lời được chia thành nhiều thời điểm. Một sự kiện cũ nhưng vẫn hợp lệ, một sự kiện thay thế một tùy chọn cũ hơn và một sự kiện cập nhật trạng thái khởi chạy hiện tại.
Câu trả lời đúng phụ thuộc vào cả một tùy chọn bền vững cũ hơn và một bản cập nhật dự án mới hơn. Một chính sách bộ nhớ phải bảo toàn cả hai trong khi bỏ qua bằng chứng lỗi thời. Các chính sách khác nhau thất bại khác nhau.
Đây là vấn đề cốt lõi: một sự kiện có thể cũ và vẫn quan trọng, trong khi một sự kiện gần đây có thể không liên quan. Một chính sách bộ nhớ phải xếp hạng các sự kiện, không chỉ các lượt.
Tại sao các chính sách phổ biến thất bại
Toàn bộ lịch sử có vẻ an toàn vì nó tối đa hóa khả năng gợi nhớ, nhưng nó cũng có thể
mang bằng chứng cũ và nhiễu vào lời nhắc.
Cửa sổ trượt (sliding windows) rẻ và dễ dự đoán, nhưng chúng nhầm lẫn tính thời sự với tầm quan trọng.
Tóm tắt làm giảm tải token, nhưng việc nén có thể bị sai lệch. Một bản tóm tắt bỏ qua một ràng buộc đã âm thầm thay đổi trạng thái của ứng dụng.
Truy xuất (retrieval) khôi phục các sự kiện cũ hơn, nhưng nó không tự động an toàn. Một bộ truy xuất có thể trả về sự thật đúng và một sự thật sai gần đó trong cùng một tập hợp top-k.
Độ thu hồi cao (high recall) là không đủ nếu lời nhắc cũng chứa bằng chứng cũ.
Cách trạng thái trở thành ngữ cảnh
Công cụ được tổ chức xung quanh một đường dẫn thời gian chạy duy nhất: lưu trữ tin nhắn, lập chỉ mục bộ nhớ, quyết định nguồn ngữ cảnh nào sẽ sử dụng, tập hợp lời nhắc, gọi mô hình và ghi lại việc sử dụng.
Lịch sử được lưu trữ được lập chỉ mục và tóm tắt, sau đó trình tạo ngữ cảnh kết hợp yêu cầu hiện tại, các tin nhắn gần đây, các sự kiện được truy xuất và siêu dữ liệu bộ nhớ trước khi gọi mô hình tiếp theo. Đối với một phiên dài, trình tạo ngữ cảnh có thể sử dụng các tin nhắn gần đây, một bản tóm tắt tăng dần, các sự kiện trước đó được truy xuất, ngữ cảnh nguồn được ghim, siêu dữ liệu bộ nhớ và truy vấn người dùng hiện tại.
Cấu hình mặc định giữ 15 tin nhắn gần đây, truy xuất tối đa 6 đoạn trích trước đó, sử dụng điểm truy xuất tối thiểu là 0,08 và giới hạn tóm tắt ở 2.000 token. SQLite giữ cho điểm chuẩn có thể tái tạo. Sản xuất sẽ cần một cấu hình lưu trữ và độ trễ khác.
Cách bộ nhớ được chấm điểm
Mọi tin nhắn được lưu trữ đều được lập chỉ mục và chấm điểm. Bộ chấm điểm là xác định và dựa trên quy tắc, vì vậy điểm chuẩn dễ kiểm tra.
Hàm chấm điểm kết hợp tính thời sự, cách diễn đạt bền vững, tùy chọn người dùng, đề cập thực thể, tần suất truy xuất, điều khoản cập nhật, điều khoản sự kiện theo tập, độ dài, vai trò, dấu hiệu cũ và dấu hiệu nhiễu.
Công thức chấm điểm đơn giản hóa trông như sau:
recency = exp(-age / 500)
retrieval_frequency = log1p(retrieval_count) / log(10)
score = role_signal * (
0,13 * recency
+ 0,18 * persistence
+ 0,18 * preference
+ 0,15 * entity_importance
+ 0,14 * retrieval_frequency
+ 0,12 * contradiction_risk
+ 0,06 * episodic_event
+ 0,04 * length_signal
)
score -= 0,22 * noise
score -= 0,32 * stale_marker * (1.0 - retrieval_frequency)
Các trọng số được lựa chọn thủ công, không qua tối ưu hóa. Bộ tính điểm được thiết kế có chủ đích để dễ bị lỗi: hữu ích vì có thể kiểm tra được, không phải vì các trọng số này nên được triển khai mà không thay đổi.
Lưu ý đó rất quan trọng. Nếu một điểm chuẩn tổng hợp tạo ra các sự kiện quan trọng với các mẫu ưu tiên, cập nhật và thực thể dễ nhận biết, thì một bộ tính điểm dựa trên quy tắc tìm kiếm các tín hiệu đó sẽ có lợi thế. Một sự phát triển trong sản xuất sẽ
Nguồn tin: Medium Towards AI — Tác giả: Samarth vinayaka. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.