Show HN: Tôi đã xây dựng một công cụ LLM (mô hình ngôn ngữ lớn) để kiểm tra LLM về logic Boolean.
Tôi đã xây dựng một công cụ LLM (mô hình ngôn ngữ lớn) có khả năng theo dõi các mô hình SOTA (hiện đại nhất) đang gặp lỗi "ảo giác" (hallucinating) đối với các lập luận logic cơ bản có thể giải quyết bằng phương pháp Quine-McClusky về mặt toán học. Tôi đang sử dụng công cụ này để xây dựng các trường hợp sử dụng đa dạng. Hãy cho tôi biết nếu bạn muốn tôi thử nghiệm nó trên một vấn đề nào đó. URL bình luận: https://news.ycombinator.com/item?id=48450471 Điểm: 1 Số bình luận: 0
boolean-algebra-engine
Các tác nhân mã hóa: tài liệu máy đọc được nằm trong llms.txt (tóm tắt) và llms-full.txt (tham chiếu API đầy đủ).
Các quy tắc quyết định của tác nhân AI có thể mâu thuẫn với nhau. Các mô hình ngôn ngữ lớn (LLM) không thể phát hiện điều đó một cách đáng tin cậy. Công cụ này có thể làm được điều đó — một cách có thể chứng minh được, trong vòng chưa đầy 10ms.
Các tác nhân AI với logic quyết định — phê duyệt khoản vay, kiểm tra tuân thủ, kiểm soát truy cập, thực thi chính sách — hoạt động dựa trên các quy tắc boolean do con người viết. Không ai xác minh rằng các quy tắc đó không xung đột trước khi tác nhân hành động. Công cụ này làm được điều đó.
Điểm chuẩn cho thấy lý do bạn cần nó: ngay cả một mô hình 70B cũng mắc lỗi khoảng 20% các câu hỏi logic boolean. Bạn không thể hỏi một LLM liệu các quy tắc của bạn có xung đột hay không và tin tưởng vào câu trả lời. Bạn cần một lớp xác định để tính toán điều đó.
90 bài kiểm tra đạt · đánh giá <10ms · không phụ thuộc · liệt kê đầy đủ, không lấy mẫu
Bắt đầu nhanh
pip install boolean-algebra-engine
from boolean_algebra_engine import evaluate, synthesize
# Có tồn tại mâu thuẫn không?
table, _ = evaluate("A.!A")
print(table.satisfiable) # False — luôn là một mâu thuẫn
# Hai quy tắc có thể đồng thời đúng không?
table, _ = evaluate("(A.B).(!A)")
print(table.satisfiable) # False — A và !A không thể đồng thời đúng
# Bảng chân trị đầy đủ
table, _ = evaluate("A.(B+C)")
print(table.variables) # ['A', 'B', 'C']
print(table.minterms) # [5, 6, 7]
print(table.satisfiable) # True
# Đơn giản hóa về dạng tối thiểu
minimal, _ = synthesize(table)
print(minimal) # A.C+A.B
Kiểm tra một dòng:
python -c "from boolean_algebra_engine import evaluate; t,_ = evaluate('A.!A'); print(t.satisfiable)"
# False
Các tiện ích bổ sung tùy chọn
pip install "boolean-algebra-engine[cli]" # Giao diện dòng lệnh (CLI) / REPL
pip install "boolean-algebra-engine[mcp]" # Máy chủ MCP (Claude Desktop)
pip install "boolean-algebra-engine[api]" # API REST
pip install "boolean-algebra-engine[nl-anthropic]" # Lớp ngôn ngữ tự nhiên (NL) qua Anthropic
pip install "boolean-algebra-engine[nl-openai]" # Lớp NL qua OpenAI
Vấn đề
Sáu quy tắc. Ba biến. Được viết bởi bốn người trong sáu tháng.
Một tác nhân AI fintech tự động phê duyệt hoặc từ chối đơn xin vay dựa trên các quy tắc này — không ai từng xác minh chúng cùng nhau. Công cụ này kiểm tra tất cả các kết hợp đầu vào cho mọi quy tắc, trong mọi sự kết hợp:
# pip install boolean-algebra-engine[mcp]
from boolean_algebra_engine.mcp.server import check_prompt_logic
result = check_prompt_logic([
"A.B", # phê duyệt: tín dụng tốt VÀ thu nhập đã được xác minh
"!A", # từ chối: tín dụng xấu
"C", # phê duyệt: có tài sản thế chấp
"!C", # từ chối: không có tài sản thế chấp
])
print(result["summary"])
# {'total': 4, 'contradictions': 0, 'tautologies': 0,
# 'equivalent_pairs': 0, 'conflicting_pairs': 2}
print([(p["rule1"], p["rule2"]) for p in result["pairwise"] if p["always_conflict"]])
# [('A.B', '!A'), ('C', '!C')]
Những gì nó tìm thấy:
A.B và !A xung đột — phê duyệt tín dụng tốt và từ chối tín dụng xấu đồng thời kích hoạt khi A=1. Tác nhân chọn một kết quả một cách tùy tiện.
C và !C xung đột — phê duyệt tài sản thế chấp và từ chối không có tài sản thế chấp loại trừ lẫn nhau theo định nghĩa. Cả hai quy tắc không bao giờ có thể áp dụng cùng một lúc.
Không ai phát hiện ra những điều này bằng cách đọc các quy tắc. Công cụ này đã phát hiện ra chúng bằng cách kiểm tra mọi sự kết hợp.
Điểm chuẩn
Mọi mô hình được thử nghiệm đều bị ảo giác về logic boolean — nhưng theo những cách khác nhau tùy thuộc vào kích thước và kiến trúc.
Mô hình
Kích thước
Ảo giác
Mẫu
tinyllama
1.1B
50%
luôn nói "có" — không bao giờ suy luận
llama3.2:3b
3B
50%
luôn nói "không" — không bao giờ suy luận
gemma3:4b
4B
35%
suy luận theo từng trường hợp, nhưng sai 1 trong 3
qwen3-32b
32B
17%
suy luận, nhất quán ~17% cơ bản
llama-3.3-70b
70B
20%
lập luận, nhưng quá thận trọng — bỏ sót 40% các cặp tương thích
Các mô hình nhỏ không lập luận chút nào — chúng chọn một mặc định và tuân thủ nó. Các mô hình lớn hơn lập luận nhưng vẫn bị ảo giác. llama-3.3-70b đạt 20% nhưng chỉ mắc một loại lỗi: nó cho rằng các quy tắc xung đột trong khi thực tế không phải vậy (0% bỏ sót xung đột, 40% bỏ sót tương thích).
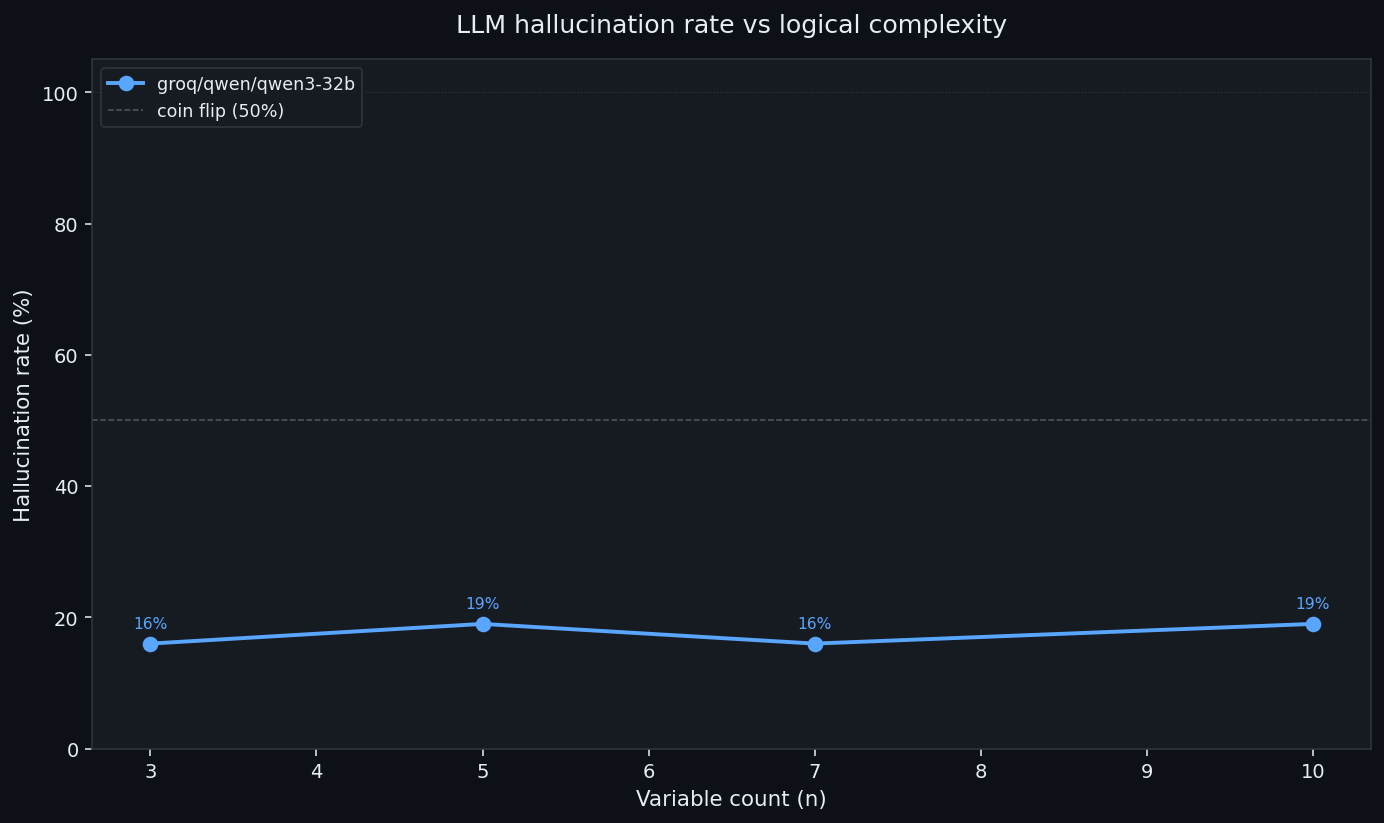
Đường cong biến thiên — liệu độ phức tạp có làm cho nó tệ hơn?
qwen3-32b đã được chạy trên các số lượng biến thiên từ 3 đến 10 (8 đến 1.024 hàng bảng chân trị), mỗi trường hợp 100 lần. Tỷ lệ ảo giác duy trì ổn định ở mức 16–19% trong suốt quá trình. Độ phức tạp không làm suy giảm nó — các lỗi là một đường cơ sở nhất quán, không phải do logic khó hơn gây ra.
biến số (n)
hàng bảng chân trị
tỷ lệ ảo giác
3
8
16%
5
32
19%
7
128
16%
10
1.024
19%
Kết quả đánh giá đầy đủ
Phương pháp: tạo các cặp biểu thức Boolean mà câu trả lời đúng (có thể thỏa mãn hay không) được biết chính xác. Hỏi LLM. So sánh. Không có sự mơ hồ, không có nhãn thủ công, không có diễn giải. Công cụ là nguồn đáng tin cậy — sự thật cơ bản được tính toán bằng cách liệt kê đầy đủ, không phải đoán. Mọi sự không đồng nhất của LLM đều là một ảo giác có thể chứng minh được.
python3 benchmark.py --provider ollama --model tinyllama --cases 20
python3 benchmark.py --provider ollama --model llama3.2:3b --cases 20
python3 benchmark.py --provider ollama --model gemma3:4b --cases 20
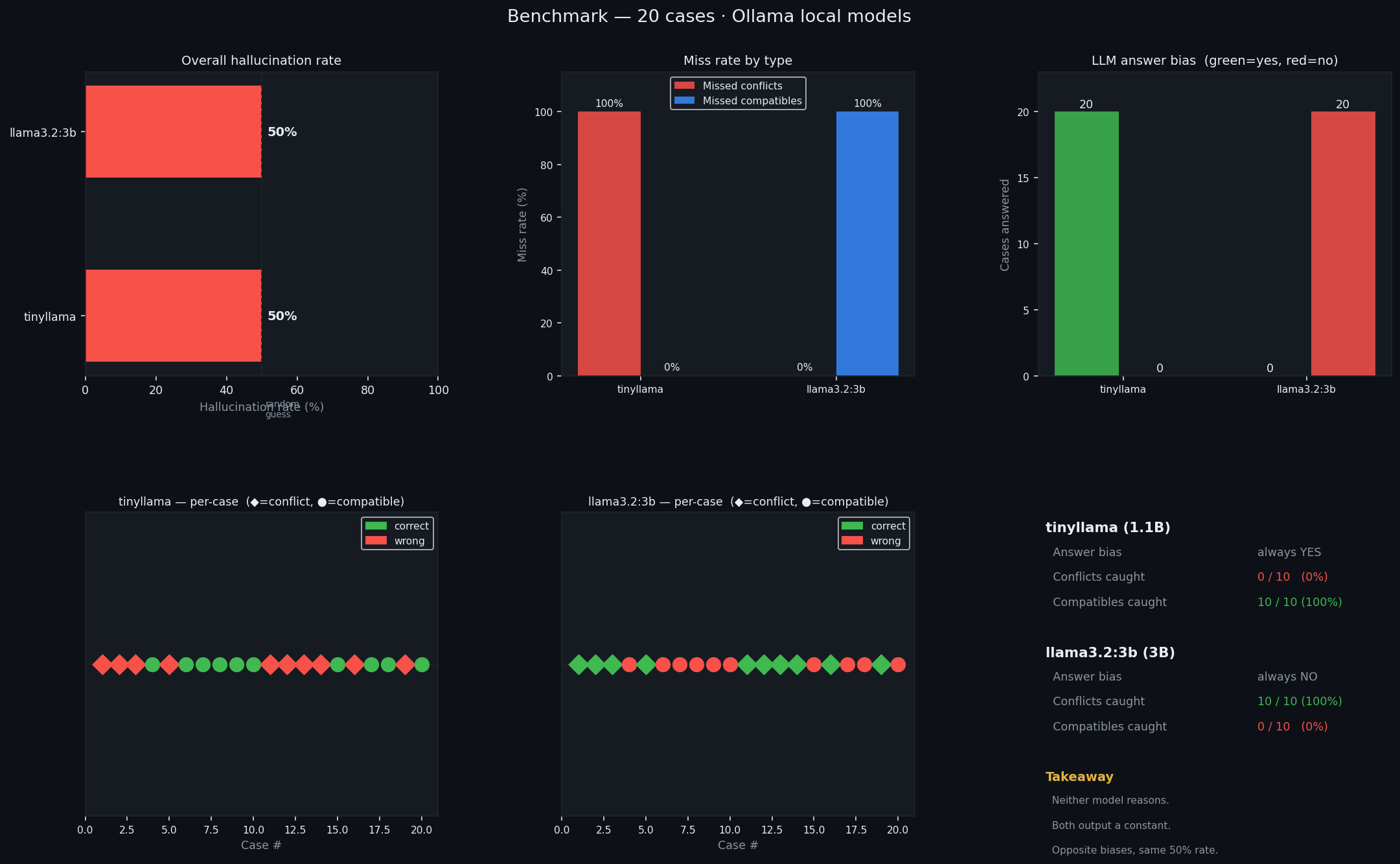
tinyllama — 1.1B
đúng: 10/20 · tỷ lệ ảo giác: 50,0%
bỏ sót xung đột: 10/10 (100%) · bỏ sót tương thích: 0/10 (0%)
mẫu: luôn xuất "yes" — không có lập luận từng trường hợp
llama3.2:3b — 3B
đúng: 10/20 · tỷ lệ ảo giác: 50,0%
bỏ sót xung đột: 0/10 (0%) · bỏ sót tương thích: 10/10 (100%)
mẫu: luôn xuất "no" — mặc định ngược lại, lỗi lập luận tương tự
gemma3:4b — 4B
đúng: 13/20 · tỷ lệ ảo giác: 35,0%
bỏ sót xung đột: 4/10 (40%) · bỏ sót tương thích: 3/10 (30%)
mẫu: xử lý từng trường hợp riêng lẻ — nhưng sai 1 trong 3
qwen3-32b — 32B
đúng: ~83/100 · tỷ lệ ảo giác: ~17%
ổn định trên 3–10 biến — các lỗi là một đường cơ sở nhất quán, không do độ phức tạp gây ra
llama-3.3-70b — 70B
đúng: ~80/100 · tỷ lệ ảo giác: ~20%
bỏ sót xung đột: 0% · bỏ sót tương thích: ~40%
mẫu: quá thận trọng — không bao giờ đánh dấu một xung đột không tồn tại, nhưng bỏ sót 2 trong 5 cặp tương thích
Cột "engine" là sự thật cơ bản. Mọi sự không khớp với LLM đều là một ảo giác có thể chứng minh được — không phải là một ý kiến.
API cốt lõi
from boolean_algebra_engine import evaluate, synthesize
# Chuyển tiếp: biểu thức → bảng chân trị
table, _ = evaluate("A.(B+C)")
print(table.va


Nguồn tin: Hacker News LLM — Tác giả: shrvx. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.