Sakana AI đề xuất DiffusionBlocks: một khuôn khổ huấn luyện theo khối (block-wise training framework) chuyển đổi mạng dư (Residual Networks) thành các mô-đun khử nhiễu có thể huấn luyện độc lập.
Các nhà nghiên cứu từ Sakana AI và Đại học Tokyo đề xuất DiffusionBlocks. Phương pháp này huấn luyện các mạng dựa trên kiến trúc transformer từng khối một. Bộ nhớ huấn luyện được giảm đi B lần, trong đó B là số khối. Hiệu suất được duy trì trên nhiều kiến trúc khác nhau.
Vấn đề bộ nhớ trong huấn luyện mạng nơ-ron
Quá trình lan truyền ngược (backpropagation) từ đầu đến cuối yêu cầu lưu trữ các kích hoạt trung gian qua từng lớp. Mức tiêu thụ bộ nhớ tăng tuyến tính theo độ sâu của mạng. Khi các mô hình ngày càng sâu, đây trở thành một nút thắt cổ chai đáng kể trong quá trình huấn luyện.
Một kỹ thuật hiện có, kiểm tra điểm kích hoạt (activation checkpointing), giúp giảm kích hoạt
Các nhà nghiên cứu từ Sakana AI và Đại học Tokyo đề xuất DiffusionBlocks. Phương pháp này huấn luyện các mạng dựa trên kiến trúc transformer từng khối một. Bộ nhớ huấn luyện được giảm đi B lần, trong đó B là số khối. Hiệu suất được duy trì trên nhiều kiến trúc khác nhau.
Vấn đề bộ nhớ trong huấn luyện mạng thần kinh
Quá trình lan truyền ngược (backpropagation) từ đầu đến cuối yêu cầu lưu trữ các kích hoạt trung gian qua mỗi lớp. Mức tiêu thụ bộ nhớ tăng tuyến tính theo độ sâu của mạng. Khi các mô hình ngày càng sâu, đây trở thành một nút thắt cổ chai đáng kể trong quá trình huấn luyện.
Một kỹ thuật hiện có, kiểm tra điểm kích hoạt (activation checkpointing), giảm bộ nhớ kích hoạt bằng cách tính toán lại các kích hoạt theo yêu cầu. Tuy nhiên, kỹ thuật này không giảm bộ nhớ cho các tham số, gradient hoặc trạng thái bộ tối ưu hóa. Với bộ tối ưu hóa Adam, mỗi lớp yêu cầu bộ nhớ cho các tham số, gradient và hai trạng thái bộ tối ưu hóa (động lượng và phương sai). Tổng cộng, điều này bằng 4 lần kích thước tham số trên mỗi lớp, không thay đổi bởi kiểm tra điểm kích hoạt.
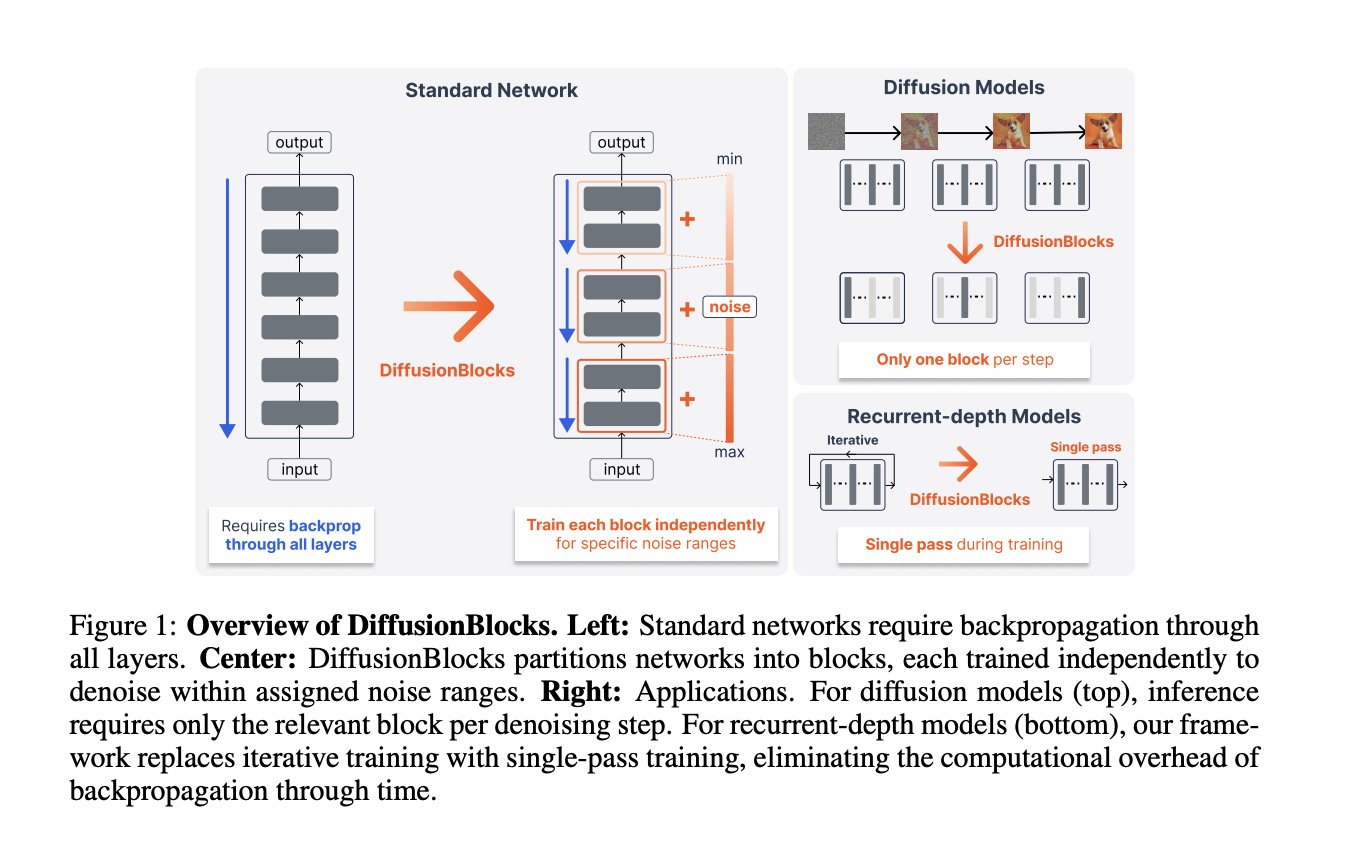
Huấn luyện theo khối (block-wise training) cung cấp một cách tiếp cận khác. Chia mạng thành B khối và huấn luyện từng khối độc lập giúp giảm bộ nhớ xuống khoảng 1/B. Mức giảm tỷ lệ thuận với số lượng khối. Thách thức là xác định một mục tiêu cục bộ có nguyên tắc cho mỗi khối mà vẫn tạo ra một mô hình nhất quán toàn cầu.
Các cách tiếp cận trước đây như thuật toán Forward-Forward của Hinton và huấn luyện từng lớp tham lam dựa vào các mục tiêu cục bộ tùy chỉnh. Chúng liên tục hoạt động kém hơn so với huấn luyện từ đầu đến cuối và chủ yếu giới hạn ở các tác vụ phân loại.
DiffusionBlocks giải quyết cả khoảng cách lý thuyết và khả năng ứng dụng hạn chế của các phương pháp trước đây.
https://arxiv.org/pdf/2506.14202
Ý tưởng cốt lõi: Kết nối dư (Residual Connections) như các bước Euler
Điểm mấu chốt được xây dựng dựa trên một mối liên hệ đã được thiết lập trong tài liệu. Các mạng dư cập nhật đầu vào của mỗi lớp thông qua zℓ=zℓ−1+fθℓ(zℓ−1)zℓ = zℓ−1 + fθℓ (zℓ−1) . Điều này tương ứng với phép rời rạc hóa Euler của các phương trình vi phân thông thường.
Nhóm nghiên cứu chỉ ra rằng các cập nhật này tương ứng cụ thể với ODE dòng xác suất (probability flow ODE) trong các mô hình khuếch tán dựa trên điểm số (score-based diffusion models). Trong công thức Variance Exploding (VE), quá trình khuếch tán ngược tuân theo:
d𝐳σdσ=−σ∇𝐳logpσ(𝐳σ) \frac{\mathrm{d}\mathbf{z}_\sigma}{\mathrm{d}\sigma} = -\sigma \nabla_{\mathbf{z}} \log p_\sigma(\mathbf{z}_\sigma)
Áp dụng phép rời rạc hóa Euler cho phương trình này tạo ra một quy tắc cập nhật phù hợp về mặt cấu trúc với cập nhật kết nối dư. Một chồng các khối dư có thể được hiểu là các bước khử nhiễu rời rạc. Các bước này trải dài một phạm vi mức nhiễu [𝞂min, 𝞂max].
Trong các mô hình khuếch tán dựa trên điểm số, mục tiêu khớp điểm số có thể được tối ưu hóa độc lập ở mỗi mức nhiễu. Điều này có nghĩa là mỗi khối có thể được huấn luyện độc lập, chỉ sử dụng mục tiêu cục bộ của riêng nó. Không cần giao tiếp giữa các khối trong quá trình huấn luyện.
Chuyển đổi một mạng: Ba bước
Chuyển đổi một mạng dư tiêu chuẩn sang DiffusionBlocks yêu cầu ba sửa đổi:
Phân vùng khối: Chia mạng L lớp thành B khối. Mỗi khối chứa một nhóm các lớp liên tiếp.
Gán phạm vi nhiễu: Xác định phân phối nhiễu pnoise và phạm vi nhiễu [𝞂min, 𝞂max]. Chia phạm vi này thành B khoảng và gán một khoảng cho mỗi khối. Nhóm nghiên cứu khuyến nghị sử dụng phân phối log-normal cho pnoise.
Điều kiện hóa nhiễu: Mở rộng đầu vào của mỗi khối để bao gồm một phiên bản nhiễu của mục tiêu. Thêm điều kiện hóa mức độ nhiễu thông qua AdaLN (Chuẩn hóa lớp thích ứng). Mỗi khối học cách dự đoán mục tiêu sạch từ phiên bản nhiễu của nó trong phạm vi nhiễu được chỉ định.
Trong quá trình huấn luyện, một khối duy nhất được lấy mẫu trong mỗi lần lặp. Các khối khác không được tính toán. Mức tiêu thụ bộ nhớ tương ứng với L/B lớp, không phải tất cả L lớp.
Phân vùng đồng xác suất
Một phân vùng đồng nhất đơn giản chia [𝞂min, 𝞂max] thành các khoảng bằng nhau. Điều này bỏ qua sự khác biệt về độ khó của việc khử nhiễu giữa các mức độ nhiễu. Các mức độ nhiễu trung gian đóng góp nhiều nhất vào chất lượng tạo ra dưới phân phối huấn luyện log-normal.
DiffusionBlocks sử dụng phân vùng đồng xác suất thay thế. Các ranh giới được chọn sao cho mỗi khối xử lý chính xác 1/B tổng khối lượng xác suất dưới pnoise. Các khối được gán cho các mức độ nhiễu trung gian nhận được các khoảng hẹp hơn. Các khối xử lý các vùng nhiễu cực đoan nhận được các khoảng rộng hơn.
Trong các nghiên cứu loại bỏ trên CIFAR-10 sử dụng DiT-S/2, việc chồng chéo khối đã bị vô hiệu hóa để cô lập từng thành phần. Phân vùng đồng xác suất đạt được FID là 38,03 so với 43,53 đối với phân vùng đồng nhất (thấp hơn là tốt hơn). Cả hai đều sử dụng phân phối lớp đồng nhất [4,4,4] trên 3 khối.
Kết quả thực nghiệm
Nhóm nghiên cứu đã đánh giá DiffusionBlocks trên năm kiến trúc trải dài ba loại tác vụ. Tất cả các kết quả so sánh DiffusionBlocks (được huấn luyện theo khối) với cùng một kiến trúc được huấn luyện bằng phương pháp lan truyền ngược từ đầu đến cuối.
Kiến trúcTập dữ liệuChỉ sốĐường cơ sởDiffusionBlocksGiảm bộ nhớViT, 12 lớp, B=3CIFAR-100Độ chính xác (cao hơn là tốt hơn)60,25%59,30%3xDiT-S/2, 12 lớp, B=3CIFAR-10Kiểm tra FID (thấp hơn là tốt hơn)39,8337,203xDiT-L/2, 24 lớp, B=3ImageNet 256×256Kiểm tra FID (thấp hơn là tốt hơn)12,0910,633xMDM, 12 lớp, B=3text8BPC (thấp hơn là tốt hơn)1,561,453xAR Transformer, 12 lớp, B=4LM1BMAUVE (cao hơn là tốt hơn)0,500,714xAR Transformer, 12 lớp, B=4OpenWebTextMAUVE (cao hơn là tốt hơn)0,850,824xHuginn recurrent-depthLM1BMAUVE (cao hơn là tốt hơn)0,490,70~10x tính toán
So sánh Forward-Forward: Trên CIFAR-100, thuật toán Forward-Forward chỉ đạt được độ chính xác 7,85% dưới cùng kiến trúc ViT. Điều này làm nổi bật khoảng cách giữa các mục tiêu tương phản đặc biệt và mục tiêu khớp điểm được sử dụng bởi DiffusionBlocks.
Hiệu quả suy luận DiT: Đối với các mô hình khuếch tán, mỗi bước khử nhiễu trong quá trình suy luận chỉ kích hoạt một khối. Một DiT 12 lớp với B=3 chỉ sử dụng 4 lần đánh giá lớp cho mỗi bước khử nhiễu. Đây là mức giảm tính toán suy luận 3 lần so với việc chạy tất cả 12 lớp.
Huấn luyện Huginn: Huginn áp dụng cùng một khối lặp lại 4 lớp một cách lặp lại. Nó sử dụng độ sâu lặp lại ngẫu nhiên trung bình 32 lần lặp.
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.