Phục vụ MiniMax-M3 để suy luận hiệu quả: Mở khóa ngữ cảnh 1 triệu token và đa phương thức không hối tiếc
Together đã phục vụ MiniMax-M3 một cách hiệu quả với cơ chế sparse attention (cơ chế chú ý thưa thớt) KV-block-major, giải mã MSA phân trang, tối ưu hóa tính điểm chỉ mục và cổng đa phương thức dựa trên Rust.
Together AI là đối tác đám mây được ưu tiên của MiniMax M3. Together AI sẽ lưu trữ mô hình mã nguồn mở dưới dạng điểm cuối dành cho nhà phát triển khi mô hình này được phát hành công khai.
Các nhóm Suy luận và Kernel của chúng tôi đã đạt được những đột phá kỹ thuật đáng kể để phục vụ M3 một cách hiệu quả, bao gồm các tối ưu hóa quan trọng như kernel chú ý thưa KV-Block-Major, tích hợp chú ý phân trang mới cho MSA, kernel tính điểm chỉ mục được tối ưu hóa cao và cổng tiền xử lý đa phương thức dựa trên Rust, mang lại cải thiện thông lượng từ 81–125% trên các mức đồng thời khác nhau.
Việc phục vụ MiniMax M3 ở quy mô lớn trong môi trường sản xuất khẳng định Together AI là nền tảng suy luận hàng đầu cho các mô hình vượt qua giới hạn về các vấn đề hệ thống khó khăn, giúp triển khai thực tế.
MiniMax đã ra mắt mô hình tiên tiến nhất M3 và Together AI rất vui mừng được trở thành đối tác đám mây được ưu tiên, giúp MiniMax phục vụ M3 hiệu quả trong môi trường sản xuất ở quy mô lớn. Khi MiniMax M3 được phát hành dưới dạng mô hình mã nguồn mở trong vài ngày tới, Together AI cũng sẽ lưu trữ mô hình này dưới dạng điểm cuối trực tiếp cho các nhà phát triển. Đằng sau quy mô đó là công việc xuất sắc của các nhóm Suy luận và Kernel của chúng tôi, những người đã thúc đẩy tối ưu hóa hiệu suất sâu rộng và đảm bảo độ tin cậy cấp độ sản xuất cho một mô hình vượt qua giới hạn: cửa sổ ngữ cảnh 1 triệu token, đa phương thức gốc và kiến trúc đòi hỏi kỹ thuật nghiêm túc để phục vụ hiệu quả. Trong bài viết này, chúng tôi sẽ trình bày cách chúng tôi thực hiện điều đó. Xin chúc mừng đội ngũ MiniMax về việc ra mắt mô hình mang tính bước ngoặt và sự đổi mới không ngừng.
MiniMax M3 là một mô hình tất cả trong một, kết hợp hiệu suất mã hóa tiên tiến, hỗ trợ quy trình làm việc của tác nhân và khả năng suy luận đa phương thức gốc. Ngoài những khả năng này, nó còn được thiết kế để hỗ trợ ngữ cảnh 1 triệu token trong khi vẫn rất tiết kiệm chi phí để phục vụ. Điều này làm cho nó phù hợp với các tác vụ thực tế, nơi các tài liệu dài, cơ sở mã, sử dụng công cụ, hình ảnh và suy luận lặp đi lặp lại thường xuất hiện cùng nhau và nặng về ngữ cảnh. So với thế hệ trước, việc phục vụ M3 đặt ra nhiều thách thức hơn vì các khả năng mới đòi hỏi tối ưu hóa trên nhiều khía cạnh hơn, bao gồm tính toán chú ý thưa, quản lý bộ nhớ đệm KV lớn hơn, xử lý đa phương thức, v.v.
Kiến trúc / Đặc điểm
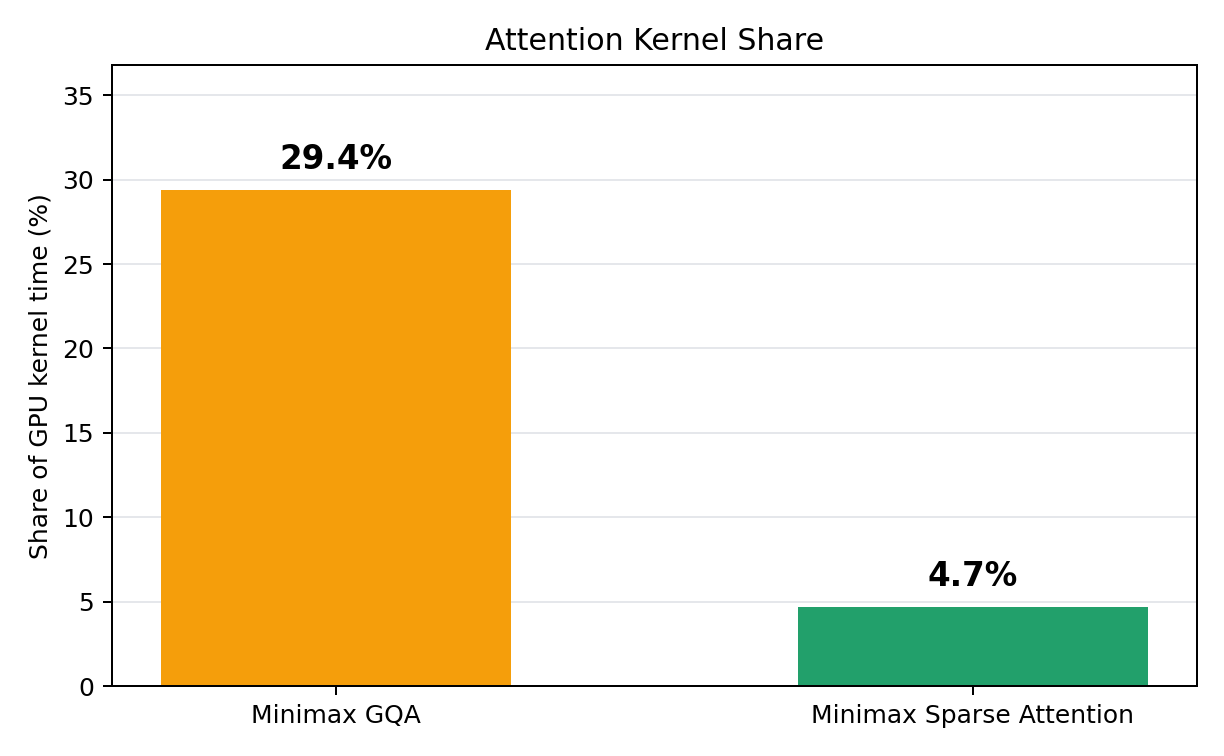
Thay đổi kiến trúc mới lạ nhất trong M3 là MiniMax Sparse Attention (MSA), được thiết kế để giải quyết nút thắt cổ chai tính toán chú ý được thấy trong MiniMax M2.7. Cơ chế chú ý thưa theo khối của nó giới hạn số lượng token tối đa mà mỗi truy vấn có thể chú ý, giảm chi phí xử lý ngữ cảnh dài và làm cho các cửa sổ ngữ cảnh dài hơn nhiều trở nên khả thi. Điều này mang lại tốc độ tăng hơn 9 lần trong giai đoạn tiền điền và hơn 15 lần trong giai đoạn giải mã.
Về bản chất, tính toán của MSA bao gồm hai phần: tính toán điểm số để xác định các khối K phù hợp nhất để chú ý cho mỗi nhóm KV, và sau đó là chú ý dày đặc giữa token truy vấn và các khối đó. Thiết kế này bảo toàn khả năng biểu đạt dọc theo chiều nhóm KV trong khi vẫn đặt giới hạn về số lượng token KV tối đa mà một token truy vấn chú ý. Bản thân tính toán chú ý không còn tăng theo N^2 với độ dài ngữ cảnh, do đó rất phù hợp cho khối lượng công việc ngữ cảnh dài.
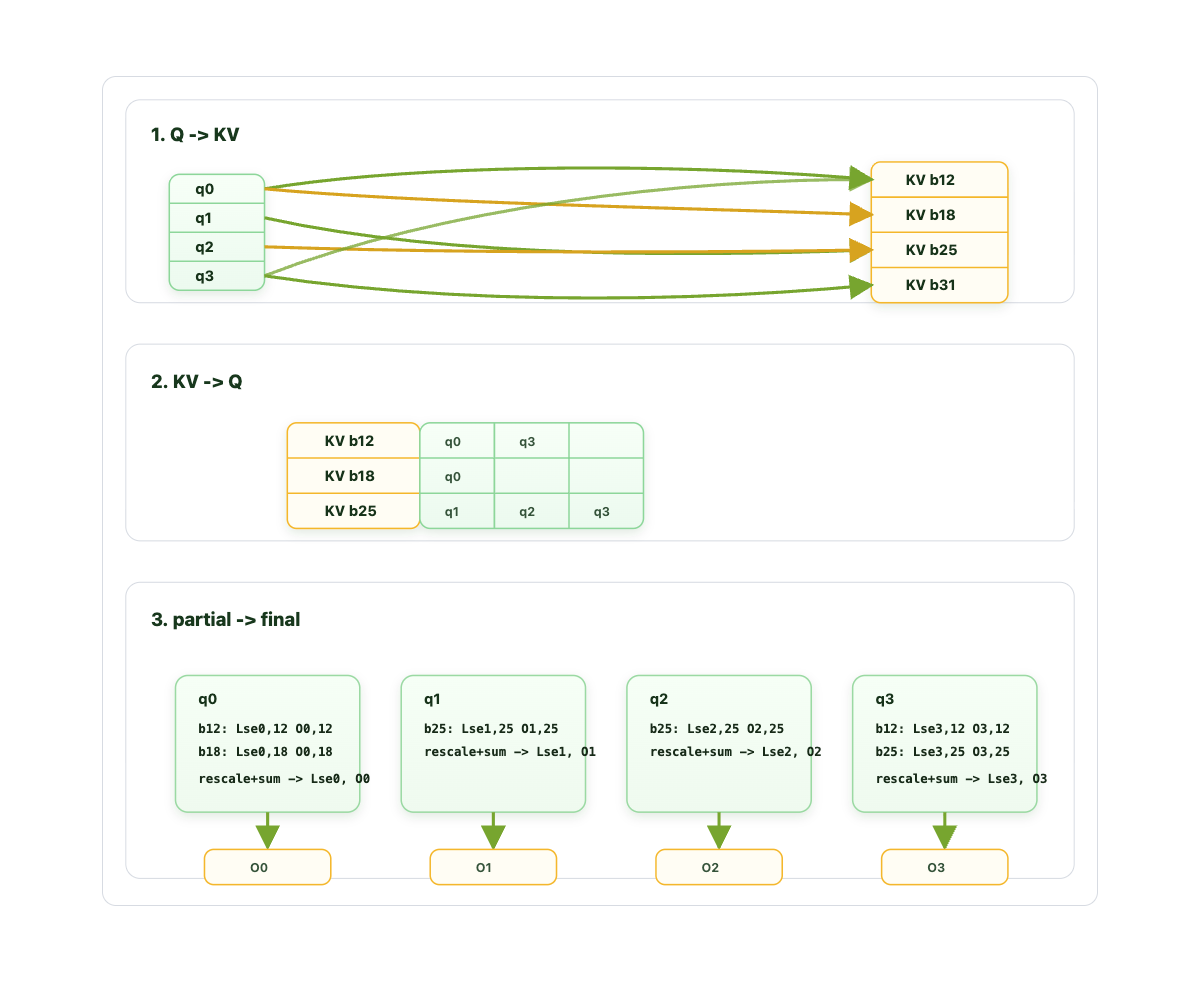
Chúng tôi đã đo thời gian thực thi kernel dưới dạng lưu lượng truy cập kiểu tác nhân (bộ nhớ đệm tiền tố 60k) với đồng thời 8 trên B200. MSA làm giảm đáng kể phần trăm thời gian thực của tính toán chú ý thực tế trên mỗi lần lặp.
Ngoài thay đổi về kiến trúc attention, M3 còn được trang bị hỗ trợ đa phương thức với một thành phần thị giác và các chức năng tiền xử lý hình ảnh, video mới.
Với những thay đổi cơ bản này, Together AI đã hợp tác chặt chẽ với đội ngũ kỹ thuật của MiniMax để giải quyết các thách thức mới nổi. Một số thách thức chính bao gồm:
Mặc dù tính toán attention thưa của MiniMax tự nó rất hiệu quả, nhưng việc hỗ trợ độ dài ngữ cảnh 1 triệu vẫn là một thách thức từ góc độ kỹ thuật.
Xử lý video và hình ảnh vốn phức tạp hơn việc mã hóa văn bản.
Tối ưu hóa
KV-Block-Major Sparse Attention
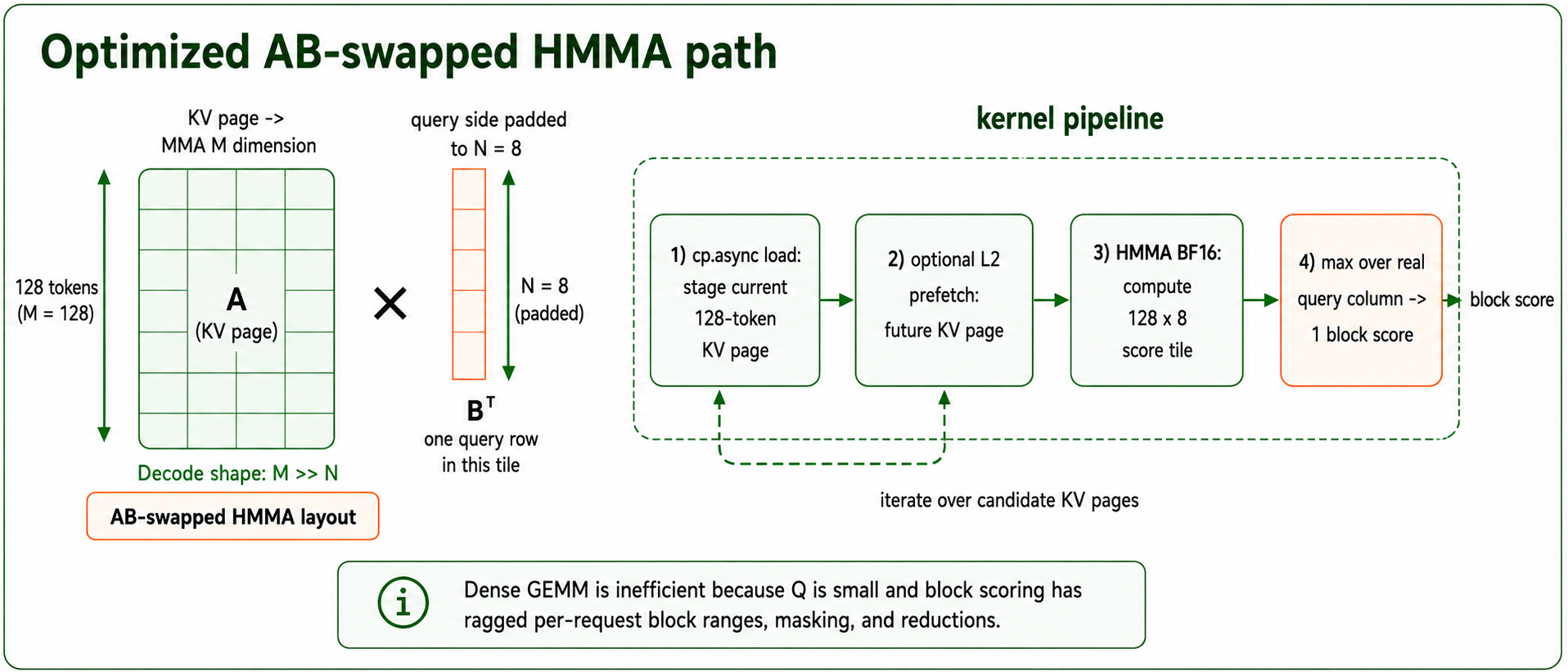
Trong quá trình tiền điền (prefill), tính toán attention vẫn có thể là một yếu tố lớn đối với đầu vào ngữ cảnh dài, vì đối với mỗi token, chúng ta cần tính toán Selected Block * KV Head Group * Tokens. Bản chất của attention thưa theo khối cho phép nhiều truy vấn tập trung vào cùng một khối khóa-giá trị. Do đó, nếu chúng ta lặp lại từng truy vấn để tính toán attention với các khối khóa-giá trị, chúng ta đang sao chép việc di chuyển KV từ HBM sang SRAM trên GPU. Lặp lại nhóm khóa-giá trị trong vòng lặp ngoài và tính toán attention giữa các token truy vấn trong vòng lặp trong cho phép cường độ số học tốt hơn vì bộ nhớ đệm KV chỉ được di chuyển một lần.
Để đạt được điều này, chúng ta cần sắp xếp lại ánh xạ từ {q, kv block} thành {kv block, q} và triển khai lại kernel attention. Bởi vì chúng ta chỉ tính toán đầu ra O một phần cho khối kv, chúng ta cần một "phép rút gọn" cuối cùng dựa trên Log-Sum-Exp để điều chỉnh lại đầu ra O và tổng. Quá trình này như sau:
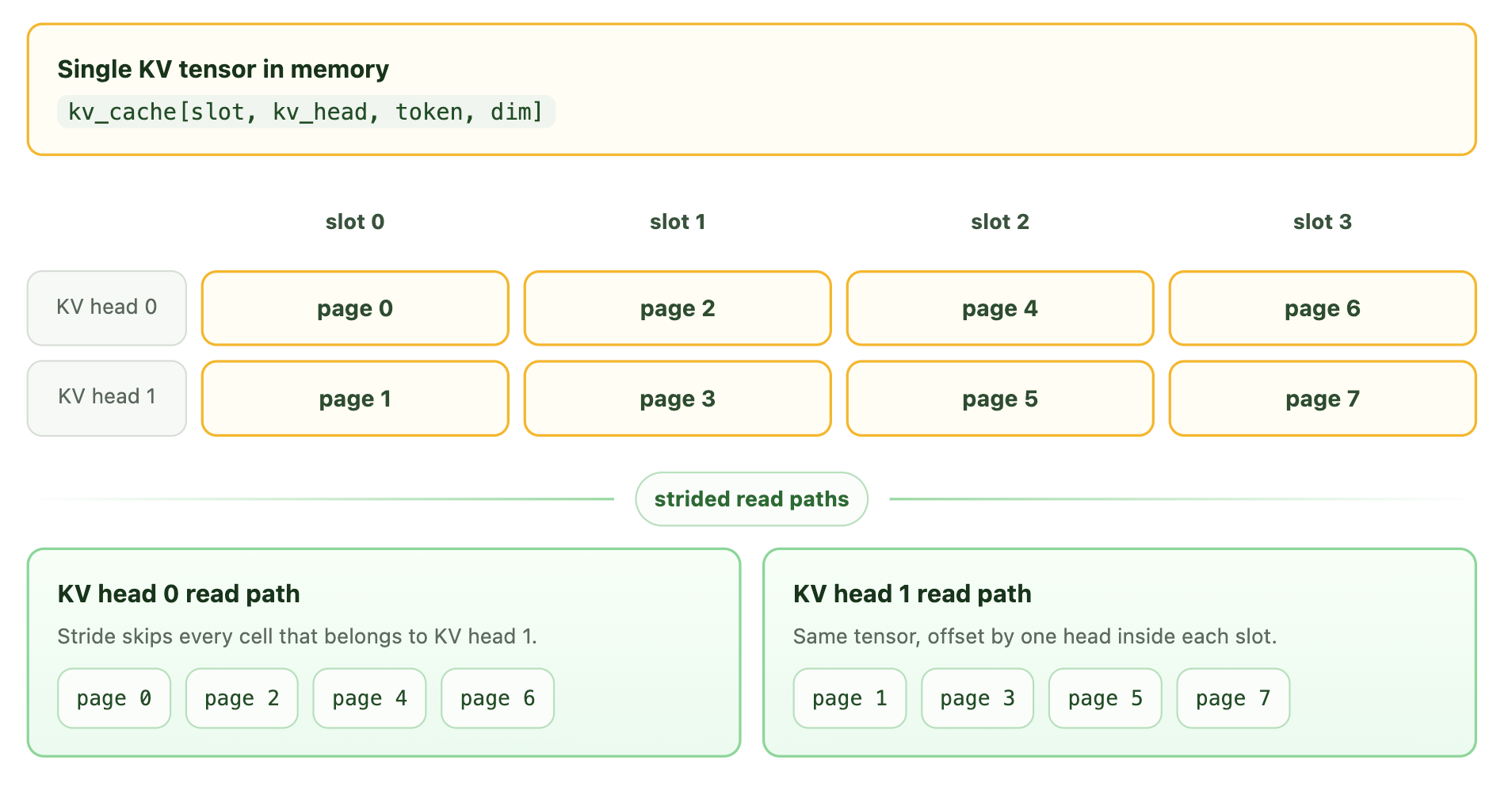
Tích hợp MSA với Paged Attention
Trong các công cụ suy luận hiện đại, paged attention thường được sử dụng để quản lý ngữ cảnh bộ nhớ đệm KV cho các yêu cầu. Phần lớn các kernel attention được tối ưu hóa cao được viết với một tập hợp cố định các hỗ trợ kích thước trang. Trở ngại ngăn cản chúng ta sử dụng các kernel này là các khối được chọn khác nhau giữa các nhóm KV.
Tại Together AI, chúng tôi đề xuất một cách mới để tích hợp MiniMax Sparse Attention vào công cụ. Trong quá trình giải mã, chúng ta xây dựng một bảng trang dựa trên các khối được chọn, làm phẳng chiều nhóm KV thành chiều lô, và tận dụng chế độ xem theo bước của tensor bộ nhớ đệm KV để cung cấp cho kernel attention con trỏ cần thiết để truy xuất trang KV. Mấu chốt là bước nhảy: địa chỉ trang tăng theo D để chọn một điểm bắt đầu trang ảo, trong khi các token tăng theo Hkv * D. Điều đó tách rời một tensor vật lý thành các trang trên mỗi đầu, do đó mỗi hàng được làm phẳng hiện có thể sử dụng một bảng trang khác nhau.
Thiết kế này đã giúp chúng tôi có thể sử dụng các kernel attention hiện có hỗ trợ GQA.
Nguồn tin: Together AI Blog. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.