NVIDIA đã phát hành Nemotron 3.5 ASR: Một mô hình truyền phát nhận biết bộ nhớ đệm 600 triệu tham số, phiên âm 40 ngôn ngữ-địa phương trong thời gian thực.
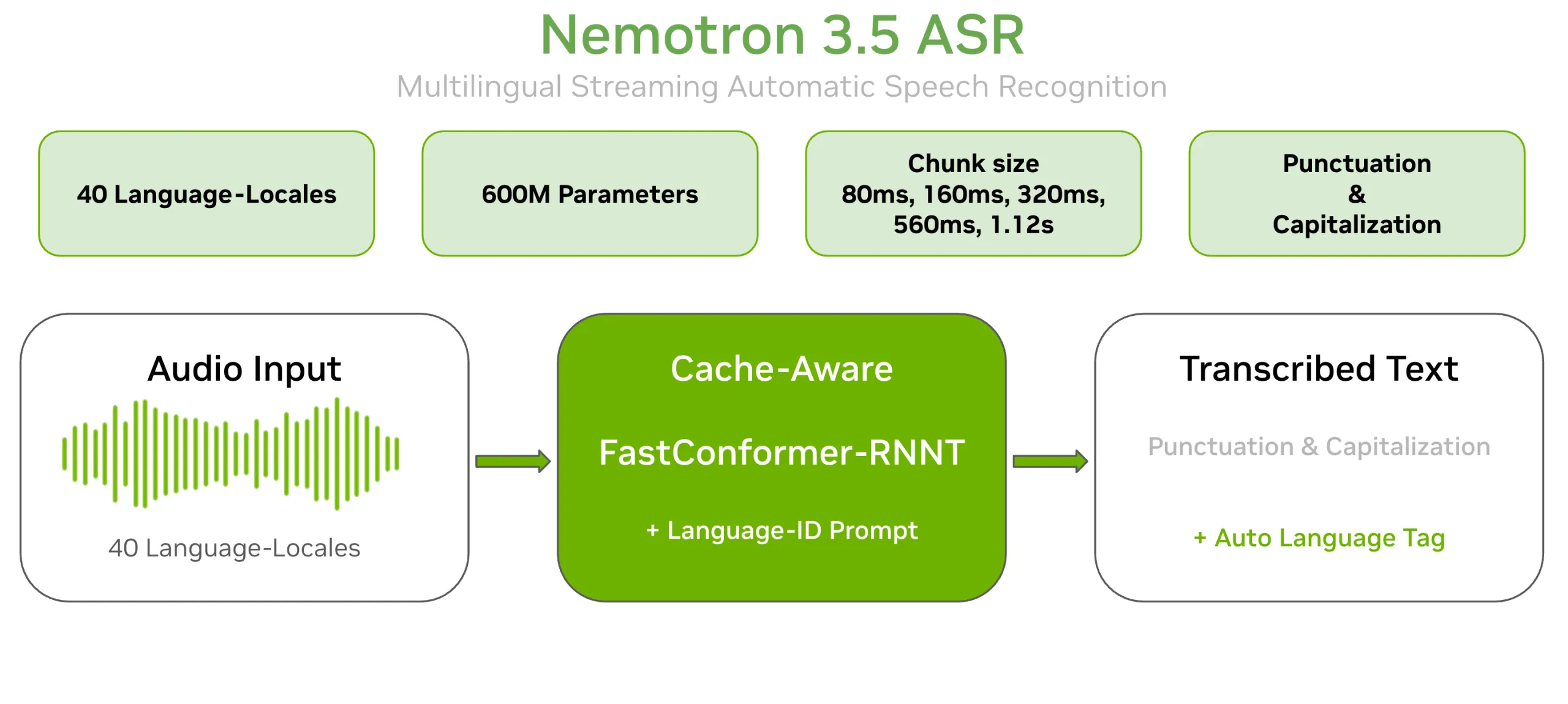
Nhóm Nemotron Speech của NVIDIA đã phát hành Nemotron 3.5 ASR. Đây là mô hình Nhận dạng giọng nói tự động (ASR) trực tuyến với 600 triệu tham số. Một điểm kiểm tra duy nhất có thể chuyển đổi giọng nói thành văn bản cho 40 ngôn ngữ-địa phương trong thời gian thực. Chức năng chấm câu và viết hoa được tích hợp sẵn. Mô hình được cung cấp dưới dạng trọng số mở trên Hugging Face. Giấy phép là OpenMDW-1.1. Kiến trúc là Cache-Aware FastConformer-RNNT.
Nemotron 3.5 ASR là gì
Nemotron 3.5 ASR mở rộng mô hình nvidia/nemotron-speech-streaming-en-0.6b sang nhiều ngôn ngữ. Mô hình này bổ sung tính năng điều kiện hóa nhận dạng ngôn ngữ dựa trên lời nhắc vào mô hình cơ sở. Điều đó cho phép một mô hình 600 triệu tham số
Nhóm Nemotron Speech của NVIDIA đã phát hành Nemotron 3.5 ASR. Đây là mô hình Nhận dạng giọng nói tự động (ASR) trực tuyến với 600 triệu tham số. Một điểm kiểm tra duy nhất có thể chuyển đổi 40 ngôn ngữ-khu vực thành văn bản theo thời gian thực. Dấu câu và chữ hoa được tích hợp sẵn. Mô hình được phát hành dưới dạng trọng số mở trên Hugging Face. Giấy phép là OpenMDW-1.1. Kiến trúc là Cache-Aware FastConformer-RNNT.
Nemotron 3.5 ASR là gì
Nemotron 3.5 ASR mở rộng nvidia/nemotron-speech-streaming-en-0.6b sang nhiều ngôn ngữ. Mô hình này bổ sung điều kiện nhận dạng ngôn ngữ dựa trên lời nhắc vào mô hình cơ sở. Điều đó cho phép một điểm kiểm tra 600 triệu tham số bao phủ 40 ngôn ngữ-khu vực. Không yêu cầu mô hình riêng cho từng ngôn ngữ hoặc việc hoán đổi mô hình.
Mô hình này nhắm đến hai khối lượng công việc. Thứ nhất là truyền phát độ trễ thấp cho âm thanh trực tiếp. Thứ hai là chuyển đổi hàng loạt với thông lượng cao. Đầu ra là văn bản sẵn sàng sản xuất với chữ hoa và dấu câu phù hợp. Không cần bước khôi phục dấu câu riêng biệt.
Nguồn ảnh: https://huggingface.co/nvidia/nemotron-3.5-asr-streaming-0.6b
Cách hoạt động của Cache-Aware FastConformer-RNNT
Mô hình có hai phần chính. Phần đầu tiên là bộ mã hóa Cache-Aware FastConformer với 24 lớp. FastConformer là một sự phát triển hiệu quả của kiến trúc Conformer. Nó sử dụng cơ chế chú ý có thể mở rộng tuyến tính. Phần thứ hai là bộ giải mã RNNT (Recurrent Neural Network Transducer). RNNT phát ra văn bản từng khung hình khi âm thanh được truyền vào.
Thiết kế "cache-aware" là đòn bẩy hiệu quả. Truyền phát đệm xử lý lại các cửa sổ âm thanh chồng chéo ở mỗi bước. Điều đó lặp lại cùng một công việc và làm tăng độ trễ. Thay vào đó, mô hình này lưu trữ các kích hoạt tự chú ý và tích chập của bộ mã hóa. Nó tái sử dụng các trạng thái được lưu trữ đó khi âm thanh mới đến. Vì vậy, mỗi khung âm thanh được xử lý chính xác một lần, không có sự chồng chéo. Cả tính toán và độ trễ đầu cuối đều giảm, mà không ảnh hưởng đến độ chính xác.
Nút điều chỉnh độ trễ: att_context_size
Một cài đặt suy luận kiểm soát sự đánh đổi giữa độ trễ và độ chính xác. Đó là kích thước ngữ cảnh chú ý, att_context_size. Ngữ cảnh nhỏ hơn phát ra văn bản sớm hơn nhưng thấy ít âm thanh tương lai hơn. Ngữ cảnh lớn hơn làm tăng độ chính xác với độ trễ cao hơn.
Cùng một điểm kiểm tra bao phủ toàn bộ phạm vi. Các cài đặt tương ứng với kích thước đoạn 80ms, 160ms, 320ms, 560ms và 1,12s. Ví dụ, [56,0] cung cấp chế độ độ trễ cực thấp 80ms. Cài đặt [56,13] cung cấp 1,12s cho độ chính xác cao nhất. Các nhóm chọn điểm hoạt động tại thời điểm suy luận, không cần đào tạo lại.
Phát hiện và bao phủ ngôn ngữ
40 ngôn ngữ-khu vực bao gồm các biến thể tiếng Anh, tiếng Tây Ban Nha, tiếng Đức và tiếng Pháp. Chúng cũng bao gồm tiếng Ả Rập, tiếng Nhật, tiếng Hàn, tiếng Quan Thoại, tiếng Hindi và tiếng Thái. Một số ngôn ngữ châu Âu và Bắc Âu khác cũng được bao gồm.
Điều kiện ngôn ngữ hoạt động theo hai cách. Đặt target_lang thành một ngôn ngữ-khu vực đã biết thường cho độ chính xác tốt nhất. Đặt target_lang=auto cho phép mô hình tự phát hiện ngôn ngữ. Ở chế độ tự động, nó phát ra một thẻ ngôn ngữ sau dấu câu cuối cùng. Một triển khai sau đó có thể chuyển đổi lưu lượng truy cập đa ngôn ngữ. Không cần thành phần nhận dạng ngôn ngữ riêng biệt.
So sánh
Sản phẩm
Công ty
Truy cập
Truyền phát gốc
Phạm vi ngôn ngữ
Độ trễ được báo cáo
Mô hình định giá
Nemotron 3.5 ASR
NVIDIA
Trọng số mở (OpenMDW-1.1), tự lưu trữ; được lưu trữ trên DeepInfra
Có – FastConformer-RNNT nhận biết bộ nhớ đệm
40 ngôn ngữ-địa phương
80ms–1,12s, có thể cấu hình tại thời điểm suy luận
Miễn phí tự lưu trữ; dựa trên mức sử dụng thông qua máy chủ
Whisper large-v3
OpenAI
Trọng số mở (MIT), tự lưu trữ; API
Không – ngoại tuyến/theo lô
~99 ngôn ngữ
Không phải là truyền phát gốc
Tự lưu trữ miễn phí; API ~0,006 USD/phút (theo lô)
Nova-3
Deepgram
API đóng; tại chỗ/tự lưu trữ (doanh nghiệp)
Có – truyền phát + theo lô
Đa ngôn ngữ; +10 ngôn ngữ đơn ngữ được thêm vào tháng 1/2026
Truyền phát độ trễ thấp (được báo cáo dưới 300ms)
~0,0077 USD/phút (Nova-3 Đơn ngữ, PAYG)
Universal-3 Pro Streaming
AssemblyAI
API đóng (có sẵn điểm cuối EU)
Có
6 ngôn ngữ: tiếng Anh, tiếng Tây Ban Nha, tiếng Pháp, tiếng Đức, tiếng Ý, tiếng Bồ Đào Nha
Dưới 300ms (chính thức); một phần đầu tiên ~750ms
Dựa trên mức sử dụng (PAYG)
Scribe v2 Realtime
ElevenLabs
API đóng
Có
Hơn 90 ngôn ngữ (99 theo ElevenLabs)
~150ms (p50)
~0,28 USD/giờ
Ursa / streaming
Speechmatics
API + tại chỗ + biên
Có – truyền phát + theo lô
Hơn 50 ngôn ngữ với nhận dạng tự động
Độ trễ cực thấp (được định vị)
Doanh nghiệp/sử dụng
Kết quả tinh chỉnh
Do trọng số là mở, các nhóm có thể tinh chỉnh cho một ngôn ngữ, miền hoặc giọng. NVIDIA đã công bố một ví dụ thực tế về tiếng Hy Lạp và tiếng Bulgaria. Nó đã tinh chỉnh điểm kiểm tra cơ sở bằng cùng một công thức Cache-Aware FastConformer-RNNT. Mỗi đoạn clip mang một thẻ target_lang để điều kiện ngôn ngữ. Dữ liệu đào tạo đến từ các kho ngữ liệu công cộng, bao gồm Granary, Common Voice và FLEURS.
Kết quả được đo bằng WER trên FLEURS được giữ lại, ở cài đặt 80ms. WER tiếng Hy Lạp giảm từ 35 xuống 24, cải thiện tương đối 32%. Tiếng Bulgaria giảm từ 22 xuống 15, cải thiện tương đối 31%. Đây là tỷ lệ phần trăm WER thô ở chế độ truyền phát độ trễ thấp nhất. NVIDIA lưu ý rằng việc đánh giá ở độ trễ triển khai, trên dữ liệu được giữ lại, cho số liệu trung thực.
Điểm mạnh và cân nhắc
Điểm mạnh:
Một điểm kiểm tra 600M tham số bao gồm 40 ngôn ngữ-địa phương, cắt giảm sự phân tán triển khai.
Truyền phát nhận biết bộ nhớ đệm xử lý mỗi khung hình một lần, được báo cáo ở mức đồng thời đệm 17x trên H100.
att_context_size điều chỉnh độ trễ từ 80ms đến 1,12s tại thời điểm suy luận, không cần đào tạo lại.
Dấu câu, viết hoa và gắn thẻ ngôn ngữ tự động được tích hợp sẵn.
Trọng số mở cho phép giảm WER tương đối 31–32% trên tiếng Hy Lạp và tiếng Bulgaria sau khi tinh chỉnh.
Cân nhắc:
Mô hình xử lý tiếng Anh, nhưng NVIDIA khuyến nghị mô hình tiếng Anh chuyên dụng của họ để chỉ sử dụng tiếng Anh.
Chế độ 80ms đánh đổi một số độ chính xác để có độ trễ thấp nhất.
Tiếng Nhật và tiếng Hàn sử dụng CER, vì vậy cần cẩn thận khi so sánh lỗi giữa các ngôn ngữ.
Số liệu thông lượng được đo trên H100, vì vậy kết quả trên các GPU khác sẽ khác nhau.
NIM sản xuất với truyền phát gRPC đã được công bố, nhưng chưa được phát hành.
Những điểm chính
Nemotron 3.5 ASR của NVIDIA là một mô hình truyền phát trọng số mở (OpenMDW-1.1), 600M tham số, phiên âm 40 ngôn ngữ-địa phương từ một điểm kiểm tra.
Thiết kế Cache-Aware FastConformer-RNNT của nó xử lý mỗi khung âm thanh trên
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.