NVIDIA AI ra mắt Nemotron 3 Ultra: Mô hình lai Mamba-Transformer 550B mã nguồn mở với kiến trúc Mixture-of-Experts (MoE) dành cho các tác nhân hoạt động dài hạn.
NVIDIA đã phát hành Nemotron 3 Ultra, mô hình lớn nhất trong dòng sản phẩm Nemotron 3 của hãng. Mô hình này hướng đến giải quyết một vấn đề cụ thể: các tác nhân (agent) chạy dài hạn, có khả năng lập kế hoạch, sử dụng công cụ và suy luận qua nhiều lượt. Khi các tác nhân hoạt động lâu hơn, số lượng token tăng lên và chi phí suy luận cũng tăng theo. Nemotron 3 Ultra được thiết kế để duy trì độ chính xác cao đồng thời giúp quá trình suy luận nhanh hơn và tiết kiệm chi phí hơn.
Nemotron 3 Ultra là gì
Nemotron 3 Ultra là một mô hình Mixture-of-Experts (MoE) với tổng cộng 550 tỷ tham số. Chỉ có 55 tỷ tham số hoạt động trên mỗi token. Thiết kế MoE giúp cải thiện độ chính xác trên mỗi tham số hoạt động.
Mô hình này sử dụng kiến trúc lai Mamba-Attention.
NVIDIA đã phát hành Nemotron 3 Ultra, mô hình lớn nhất trong dòng sản phẩm Nemotron 3. Mô hình này nhắm đến một vấn đề cụ thể: các tác nhân (agent) chạy dài hạn, thực hiện lập kế hoạch, gọi công cụ và suy luận qua nhiều lượt. Khi các tác nhân chạy lâu hơn, số lượng token tăng lên và chi phí suy luận cũng tăng theo. Nemotron 3 Ultra được thiết kế để duy trì độ chính xác cao đồng thời giúp quá trình suy luận nhanh hơn và tiết kiệm chi phí hơn.
**Nemotron 3 Ultra là gì**
Nemotron 3 Ultra là mô hình Mixture-of-Experts (MoE) với tổng cộng 550 tỷ tham số. Chỉ có 55 tỷ tham số hoạt động trên mỗi token. Thiết kế MoE cải thiện độ chính xác trên mỗi tham số hoạt động.
Mô hình này sử dụng kiến trúc Mamba-Attention lai thay vì Transformer thuần túy. Các lớp Mamba xử lý các chuỗi dài với khả năng mở rộng dưới bậc hai. Một vài lớp Attention được giữ lại để truy xuất chính xác trên các ngữ cảnh lớn.
Mô hình được huấn luyện trước trên 20 nghìn tỷ token văn bản. Ngữ cảnh sau đó được mở rộng lên 1 triệu token. Mô hình được huấn luyện sau bằng cách sử dụng Supervised Fine-Tuning (SFT), Reinforcement Learning (RL) và Multi-teacher On-Policy Distillation (MOPD).
Nhóm NVIDIA báo cáo thông lượng suy luận cao hơn khoảng 6 lần so với các LLM mở tương đương, với độ chính xác tương đương.
https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-Ultra-Technical-Report.pdf
**Kiến trúc**
Mô hình có 108 lớp và kích thước mô hình là 8.192. Nó sử dụng 64 đầu truy vấn (query head) và chỉ 2 đầu khóa-giá trị (key-value head), giúp bộ nhớ đệm KV nhỏ. Mỗi lớp MoE chứa 512 chuyên gia (expert), với 22 chuyên gia hàng đầu được kích hoạt trên mỗi token.
Ba lựa chọn thiết kế nổi bật:
LatentMoE định tuyến các chuyên gia hiệu quả hơn. Nó cho phép định tuyến nhiều chuyên gia hơn với chi phí suy luận cố định bằng cách đánh đổi chiều rộng chiều ẩn (hidden-dimension width). Nhóm NVIDIA báo cáo độ chính xác tốt hơn trên mỗi tham số so với các MoE hạt mịn (granular MoE) tiêu chuẩn.
Multi-Token Prediction (MTP) dự đoán một vài token tương lai trong một lần chuyển tiếp. Nó cho phép giải mã suy đoán (speculative decoding) tự nhiên để tạo ra nhanh hơn. Hai đầu MTP chia sẻ tham số trong quá trình huấn luyện.
Huấn luyện trước NVFP4 sử dụng kiểu dữ liệu 4 bit E2M1 với lượng tử hóa khối hai chiều trên trọng số. Nhóm NVIDIA gọi đây là minh chứng quy mô lớn nhất về huấn luyện NVFP4 ổn định, chính xác cho đến nay.
Ngăn xếp Mamba-Attention lai khá quan trọng đối với các tác nhân. Chi phí giải mã trên mỗi bước của Mamba không đổi khi độ dài chuỗi tăng lên. Đó là lý do tại sao lợi ích thông lượng mở rộng trên các khối lượng công việc dài, nặng về giải mã.
**Huấn luyện trước và Phát hành dữ liệu**
Huấn luyện trước sử dụng lịch trình tốc độ học Warmup-Stable-Decay trên 20 nghìn tỷ token. Nó được chia thành hai giai đoạn. 15 nghìn tỷ token đầu tiên ưu tiên sự đa dạng. 5 nghìn tỷ token cuối cùng ưu tiên dữ liệu chất lượng cao.
Nhóm NVIDIA cũng phát hành các bộ dữ liệu huấn luyện trước chuyên biệt theo lĩnh vực mới. Chúng bao gồm 173 tỷ token mã GitHub được làm mới. Trong một thử nghiệm Nemotron 3 Nano, một bộ dữ liệu pháp lý tổng hợp đã nâng điểm trung bình LegalBench từ 64,6 lên 74,7. Trong một thử nghiệm tương tự, một bộ dữ liệu tìm kiếm thông tin dựa trên Wiki đã nâng điểm SimpleQA từ 40,2 lên 50,2.
Bản phát hành sau huấn luyện cũng rất lớn. NVIDIA bổ sung 10 triệu mẫu SFT mới và 1 triệu tác vụ RL mới. Nó bổ sung 15 môi trường RL mới. Tổng số Nemotron mở tích lũy đạt 50 triệu mẫu SFT, 2 triệu tác vụ RL và 55 môi trường RL.
Quá trình huấn luyện không hoàn toàn suôn sẻ. NVIDIA ghi nhận hai sự phân kỳ mất mát và coi chúng là một hồ sơ kỹ thuật hữu ích. Lần đầu tiên, gần 8 nghìn tỷ token, được truy nguyên từ việc chuyển giảm độ dốc lớp đầu ra từ FP32 sang BF16. Đóng góp độ dốc MTP thực tế đã bị mất trong 7 bit mantissa của BF16. Việc quay trở lại giảm độ dốc FP32 đã ổn định lại quá trình huấn luyện.
Sự phân kỳ thứ hai, gần 16 nghìn tỷ token, không có nguyên nhân gốc rễ được xác nhận. NVIDIA đã khắc phục bằng cách điều chỉnh sớm tốc độ học. Sau đó, công ty đã cắt giảm tổng số token xuống còn 20 nghìn tỷ token.
Sau đào tạo: SFT, RLVR và MOPD
Quy trình sau đào tạo chạy SFT, sau đó là RLVR thống nhất, tiếp theo là khởi động MOPD, MOPD và MTP Boosting. Toàn bộ vòng lặp có thể lặp lại trong vài chu kỳ.
RLVR là viết tắt của Reinforcement Learning with Verifiable Reward (Học tăng cường với phần thưởng có thể xác minh). Nó đào tạo trên nhiều môi trường cùng một lúc: sử dụng thiết bị đầu cuối, kỹ thuật phần mềm, tìm kiếm, toán học, mã hóa, an toàn và nhiều hơn nữa. Phần thưởng trong các cài đặt này thường thưa thớt và phụ thuộc vào môi trường.
MOPD là phương pháp sau đào tạo mới chính. RLVR môi trường hỗn hợp làm loãng tín hiệu học khi số lượng môi trường tăng lên. Để giải quyết vấn đề này, nhóm NVIDIA đã đào tạo hơn mười mô hình giáo viên chuyên biệt theo từng lĩnh vực. Mỗi giáo viên có quy trình đào tạo riêng.
Trong quá trình MOPD, mô hình học sinh tự tạo ra các lượt chạy thử (rollout) trên các lĩnh vực. Mỗi lượt chạy thử được chấm điểm bởi giáo viên tương ứng với hướng dẫn dày đặc, cấp độ token. Đây là một tín hiệu dày đặc hơn so với phần thưởng thưa thớt của RLVR. Quá trình này chạy không đồng bộ, với việc tạo lượt chạy thử, chấm điểm giáo viên và cập nhật học sinh được thực hiện theo quy trình.
MOPD cũng là một quá trình lặp đi lặp lại. Sau một điểm kiểm tra MOPD, các giáo viên mới được khởi tạo từ học sinh đã cải thiện. Các cải tiến của chúng được hợp nhất vào vòng tiếp theo. Nhóm NVIDIA đã thực hiện hai lần lặp MOPD cho Nemotron 3 Ultra.
Một lưu ý thực tế đáng chú ý là MOPD hoạt động tốt nhất khi các lượt chạy thử của học sinh nằm trong phạm vi hỗ trợ của giáo viên. Một quá trình khởi động SFT ngắn gọn sẽ điều chỉnh hai phân phối trước. Nhóm NVIDIA nhận thấy rằng các cải tiến nhỏ hơn đối với các tác vụ suy luận độc lập mà học sinh hiếm khi lấy mẫu.
Kiểm soát nỗ lực suy luận
Nemotron 3 Ultra hỗ trợ ba chế độ suy luận: tắt suy luận, thông thường và nỗ lực trung bình. Các chế độ thông thường và trung bình cũng chấp nhận kiểm soát ngân sách thời gian suy luận.
Chế độ nỗ lực trung bình là đòn bẩy hiệu quả. Nhóm NVIDIA báo cáo rằng nó sử dụng ít hơn khoảng 2,5 lần token so với chế độ thông thường. Chi phí là giảm khoảng 7% độ chính xác. Đối với các bước tác nhân có khối lượng lớn, sự đánh đổi đó có thể giảm đáng kể chi phí.
Trường hợp điểm chuẩn
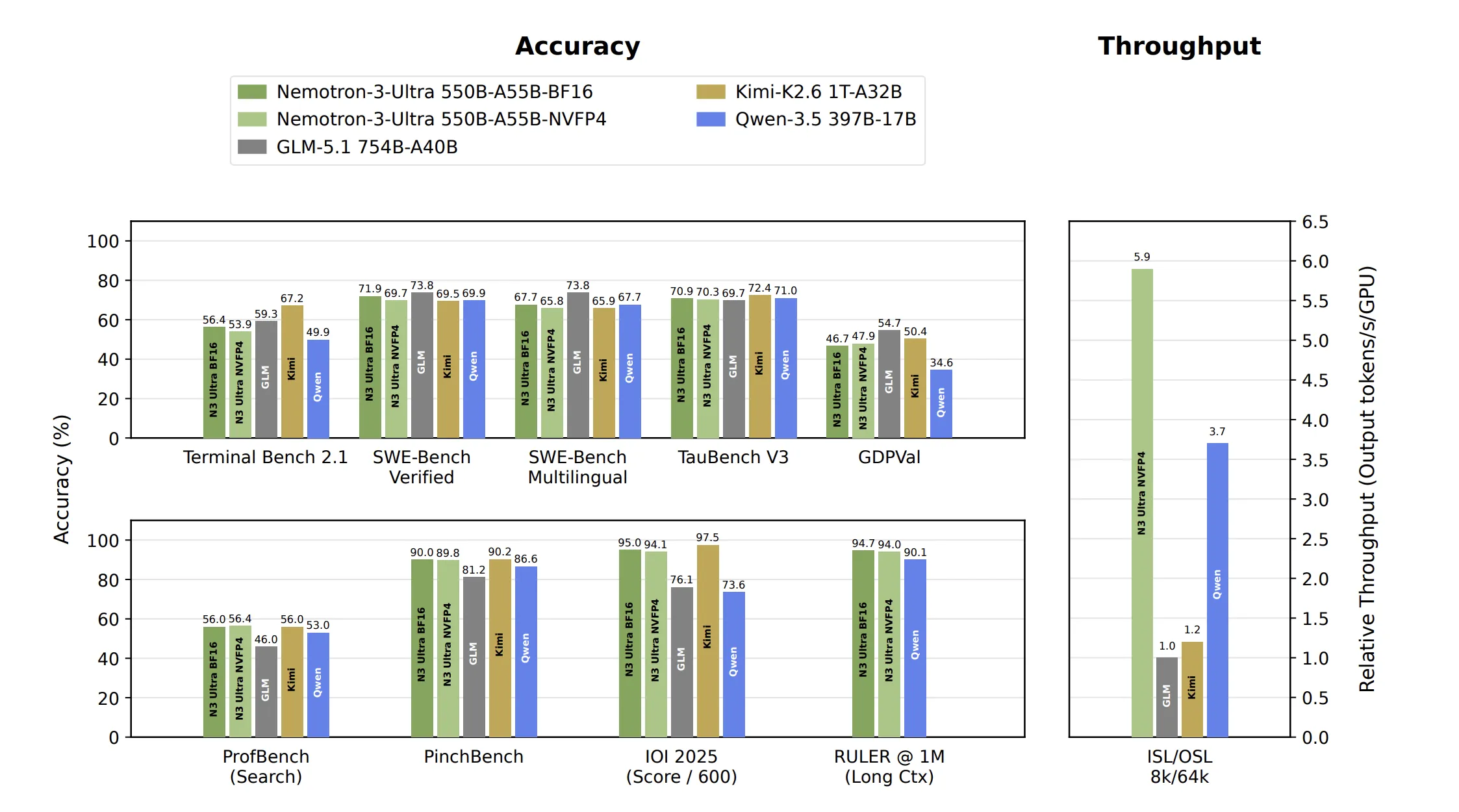
Các so sánh trong báo cáo nghiên cứu của NVIDIA sử dụng GLM-5.1 (754B), Kimi-K2.6 (1T) và Qwen-3.5 (397B), cùng với các mô hình khác. Bức tranh là cạnh tranh chứ không phải thống trị.
Đối với các tác vụ tác nhân, Nemotron 3 Ultra đạt 90.0 trên PinchBench và 56.0 trên ProfBench (Tìm kiếm). Nhóm NVIDIA đã dành cả hai làm cổng tổng quát hóa được giữ lại, chỉ được chấm điểm một lần trên mô hình cuối cùng. Nó đạt 71.9 trên SWE.
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.