Trong các triển khai suy luận sản xuất, nhu cầu biến động theo thời gian, đòi hỏi các bản sao suy luận phải mở rộng quy mô linh hoạt. Việc khởi động lạnh (cold-starting) các tác vụ suy luận trên Kubernetes có thể mất vài phút. Trong thời gian đó, các GPU được cấp phát nhưng ở trạng thái nhàn rỗi, không tạo ra token và không phục vụ yêu cầu nào.
"Khởi động lạnh" (cold start) có nghĩa là toàn bộ chuỗi tác vụ mà một máy chủ mô hình phải hoàn thành trước khi phục vụ bất kỳ yêu cầu nào: kéo ảnh container, tải trọng số mô hình vào bộ nhớ GPU, khởi động các nhân CUDA, biên dịch hoặc thu thập các đồ thị CUDA, và đăng ký với lớp khám phá dịch vụ. Sự chậm trễ này làm tăng rủi ro.
Trong các triển khai suy luận sản xuất, nhu cầu biến động theo thời gian, đòi hỏi các bản sao suy luận phải mở rộng quy mô linh hoạt. Khởi động lạnh các tác vụ suy luận trên Kubernetes có thể mất vài phút. Trong thời gian đó, các GPU được cấp phát nhưng ở trạng thái nhàn rỗi, không tạo ra token và không phục vụ yêu cầu nào.
"Khởi động lạnh" (cold start) có nghĩa là toàn bộ chuỗi mà một máy chủ mô hình phải hoàn thành trước khi phục vụ bất kỳ yêu cầu nào: kéo ảnh container, tải trọng số mô hình vào bộ nhớ GPU, khởi động các kernel CUDA, biên dịch hoặc thu thập các đồ thị CUDA, và đăng ký với lớp khám phá dịch vụ. Sự chậm trễ này làm tăng nguy cơ vi phạm SLA (Thỏa thuận mức dịch vụ) trong các đợt tăng đột biến lưu lượng truy cập, vì hệ thống không thể mở rộng quy mô đủ nhanh để hấp thụ sự gia tăng đột ngột về nhu cầu.
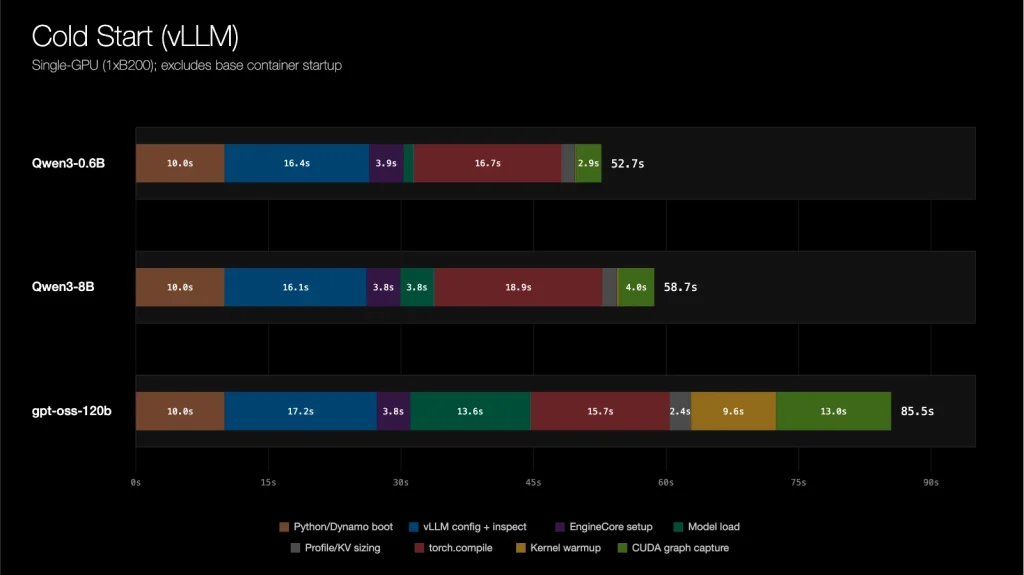
Độ trễ khởi động lạnh cho một tác vụ vLLM (v0.20.0) GPU đơn được chia thành ba phân đoạn: kéo container/ảnh, khởi tạo engine (tải trọng số, khởi động kernel, biên dịch đồ thị) và khởi động thời gian chạy phân tán.
Để giải quyết vấn đề này, nhóm nghiên cứu AI của NVIDIA đã giới thiệu NVIDIA Dynamo Snapshot: một phương pháp kiểm tra/khôi phục cho các tác vụ suy luận AI trên Kubernetes.
https://developer.nvidia.com/blog/nvidia-dynamo-snapshot-fast-startup-for-inference-workloads-on-kubernetes/?linkId=100000423964029
CRIU và cuda-checkpoint là gì?
Trạng thái có thể kiểm tra của một worker suy luận đang chạy có hai thành phần. Trạng thái thiết bị (phía GPU) bao gồm các ngữ cảnh CUDA, luồng, bộ nhớ thiết bị và ánh xạ địa chỉ ảo — điều này không hiển thị với máy chủ. Để tuần tự hóa nó, cuda-checkpoint sử dụng khả năng kiểm tra của trình điều khiển CUDA để đổ trạng thái thiết bị vào bộ nhớ CPU của tiến trình sở hữu mỗi ngữ cảnh CUDA. Trạng thái máy chủ (phía CPU) bao gồm bộ nhớ CPU, luồng, bộ mô tả tệp và không gian tên. CRIU (Checkpoint/Restore in Userspace) duyệt qua sổ sách của nhân Linux và tuần tự hóa trạng thái cây tiến trình vào đĩa.
Khi kiểm tra, hai công cụ chạy theo thứ tự: cuda-checkpoint đổ tất cả trạng thái thiết bị vào bộ nhớ CPU trước, sau đó CRIU đổ tất cả trạng thái cây tiến trình phía máy chủ vào một thư mục trong bộ nhớ. Khi khôi phục trên cùng một nút hoặc một nút khác: CRIU khôi phục cây tiến trình từ bộ nhớ phân tán như NFS hoặc SMB trước, sau đó cuda-checkpoint khôi phục trạng thái GPU từ những gì hiện có trong bộ nhớ CPU sang các GPU mới.
CRIU về cơ bản là một cơ chế đóng băng và rã đông. Khi một tiến trình được khôi phục, quá trình thực thi tiếp tục tại chính lệnh mà nó đã được kiểm tra, hoàn toàn không nhận biết rằng việc kiểm tra hoặc khôi phục đã xảy ra. Do đó, bất kỳ sự phối hợp nào cần thiết trước khi kiểm tra, chẳng hạn như làm ngừng tác vụ, hoặc sau khi khôi phục, chẳng hạn như thiết lập lại trạng thái bên ngoài — phải được xử lý bên ngoài thông qua một trình điều phối hoặc các hook (móc nối) cụ thể cho tác vụ.
Cách Dynamo Snapshot hoạt động trên Kubernetes
Trong Kubernetes, các tác vụ chạy bên trong các container trong các pod. Vì các điểm kiểm tra của CRIU chứa các tham chiếu đến lớp hệ thống tệp có thể ghi của container, việc kiểm tra được thực hiện ở cấp độ container để trạng thái cây tiến trình và hệ thống tệp di chuyển cùng nhau.
NVIDIA cung cấp một DaemonSet đặc quyền, snapshot-agent, có thể cài đặt thông qua biểu đồ Helm. Một tác nhân chạy trên mọi nút và xử lý việc tạo điểm kiểm tra (checkpoint) và khôi phục (restore) cho các vùng chứa được quản lý bởi runc mà không yêu cầu sửa đổi runc. Khi tạo điểm kiểm tra, tác nhân đợi thăm dò khả năng sẵn sàng của khối lượng công việc, gọi cuda-checkpoint và CRIU từ phía máy chủ, sau đó ghi tạo phẩm vào bộ nhớ dùng chung. Khối lượng công việc có thể đã tạo hoặc xóa các tệp cục bộ trong vùng chứa (hệ thống tệp lớp phủ), tác nhân cũng tạo điểm kiểm tra cho các tệp này sau giai đoạn CRIU.
Khi khôi phục, tác nhân khởi chạy một pod giữ chỗ nhẹ, khôi phục hệ thống tệp lớp phủ và khôi phục điểm kiểm tra CRIU/CUDA vào các không gian tên của nó. Mỗi tác nhân hoạt động độc lập trên nút cục bộ của mình, cho phép việc tạo điểm kiểm tra và khôi phục được song song hóa một cách tự nhiên trên toàn cụm.
Cách tiếp cận DaemonSet này được chọn thay vì hỗ trợ tạo điểm kiểm tra/khôi phục gốc của Kubernetes trong runc vì ba lý do: nó hoàn toàn di động mà không phụ thuộc vào các cổng tính năng của nhà cung cấp đám mây, nó cho phép kiểm soát chặt chẽ hơn CRIU để điều chỉnh hiệu suất và nó cho phép các tạo phẩm điểm kiểm tra nằm trong các kho lưu trữ linh hoạt thay vì được nhúng vào các hình ảnh OCI.
Các hook tạm dừng/tiếp tục: Một nhân viên suy luận Dynamo khởi tạo theo hai giai đoạn có thứ tự. Đầu tiên là khởi tạo công cụ: các bộ giao tiếp được khởi tạo, trọng số được tải, các kernel được làm nóng và các đồ thị CUDA được biên dịch. Nhân viên hoàn toàn sẵn sàng tại thời điểm này nhưng chưa thể được phát hiện bên ngoài pod của nó. Thứ hai là khởi động thời gian chạy phân tán: nhân viên kết nối với mặt phẳng điều khiển Dynamo và đăng ký với phần phụ trợ khám phá. Các kết nối TCP mở đến mặt phẳng điều khiển tồn tại từ thời điểm này trở đi.
Nếu điểm kiểm tra được thực hiện sau khi khởi động thời gian chạy phân tán, sẽ có các kết nối TCP đang hoạt động mà CRIU không thể nắm bắt. Giải pháp là các hook tạm dừng/tiếp tục: nhân viên ghi một tệp tín hiệu 'sẵn sàng cho điểm kiểm tra' sau khi khởi tạo công cụ nhưng trước khi khởi động thời gian chạy phân tán. Sau đó, nhân viên đi vào một vòng lặp thăm dò chờ tệp tín hiệu 'khôi phục hoàn tất' trong khi tác nhân ảnh chụp nhanh tạo điểm kiểm tra nó từ bên ngoài. Vì CRIU khôi phục thực thi tại chính xác lệnh mà việc tạo điểm kiểm tra xảy ra, nhân viên tiếp tục trực tiếp bên trong vòng lặp thăm dò, phát hiện tệp tín hiệu và tiến hành khởi tạo thời gian chạy phân tán mà không yêu cầu đồng bộ hóa bổ sung.
Mẫu tạm dừng/tiếp tục cũng quan trọng đối với các điểm kiểm tra đa GPU và đa nút (được lên kế hoạch cho bản phát hành trong tương lai): các kết nối TCP đi ra được sử dụng cho RPC không thể được tạo điểm kiểm tra ở trạng thái đã thiết lập vì địa chỉ IP của pod thay đổi giữa điểm kiểm tra và khôi phục, và các đăng ký RDMA cùng trạng thái NIC cần được tạo lại sau khi khôi phục.
Tối ưu hóa 1: Hủy ánh xạ và Giải phóng bộ nhớ đệm KV
Sau khi đo lường mức sử dụng bộ nhớ GPU cao nhất trong khi trọng số, đồ thị CUDA và các bộ đệm khác được cấp phát, các công cụ suy luận cấp phát phần bộ nhớ GPU còn lại dưới dạng một bộ đệm bộ nhớ đệm KV lớn. S
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.