Các mô hình ngôn ngữ được tinh chỉnh theo hướng dẫn từ chối các yêu cầu có hại. Tuy nhiên, phần nào của mô hình thực sự chịu trách nhiệm – và cơ chế đó được cài đặt như thế nào trong quá trình huấn luyện? Một nghiên cứu mới từ nhóm Nous Research đã xem xét câu hỏi này ở cấp độ neuron. Nhóm Nous Research đã phát triển phương pháp phân bổ neuron tương phản (CNA), một phương pháp xác định các neuron MLP cụ thể có mức độ kích hoạt phân biệt rõ nhất giữa các lời nhắc có hại và lành tính. Bằng cách loại bỏ chỉ 0,1% các kích hoạt MLP, họ đã giảm tỷ lệ từ chối hơn 50% trong hầu hết các mô hình hướng dẫn được thử nghiệm – trên các kiến trúc Llama và Qwen từ
Các mô hình ngôn ngữ được điều chỉnh theo hướng dẫn từ chối các yêu cầu có hại. Tuy nhiên, phần nào của mô hình thực sự chịu trách nhiệm – và cơ chế đó được cài đặt như thế nào trong quá trình huấn luyện? Một nghiên cứu mới từ nhóm Nous Research đã xem xét câu hỏi này ở cấp độ neuron. Nhóm Nous Research đã phát triển phương pháp phân bổ neuron tương phản (CNA), một phương pháp xác định các neuron MLP cụ thể có mức kích hoạt phân biệt rõ nhất giữa các lời nhắc có hại và lành tính. Bằng cách loại bỏ chỉ 0,1% kích hoạt MLP, họ đã giảm tỷ lệ từ chối hơn 50% ở hầu hết các mô hình hướng dẫn được thử nghiệm – trên các kiến trúc Llama và Qwen từ 1 tỷ đến 72 tỷ tham số – đồng thời giữ chất lượng đầu ra trên 0,97 ở tất cả các cường độ điều khiển. Một phát hiện thú vị là: cấu trúc lớp cuối phân biệt lời nhắc có hại với lời nhắc lành tính tồn tại trong các mô hình cơ sở trước bất kỳ quá trình tinh chỉnh nào. Tinh chỉnh căn chỉnh không tạo ra cấu trúc mới. Nó biến đổi chức năng của các neuron trong cấu trúc hiện có thành một cổng từ chối thưa thớt, có thể nhắm mục tiêu.
Vấn đề với các phương pháp điều khiển hiện có
Contrastive Activation Addition (CAA) tính toán sự khác biệt trung bình trong các kích hoạt dòng dư giữa hai tập hợp lời nhắc tương phản. Sự khác biệt trở thành một vectơ điều khiển được áp dụng tại thời điểm suy luận. CAA hiệu quả nhưng thô: nó sửa đổi toàn bộ tín hiệu trên toàn lớp mà không xác định các neuron riêng lẻ nào chịu trách nhiệm. Ở cường độ điều khiển cao, chất lượng đầu ra suy giảm – các mô hình tạo ra các từ lặp lại và văn bản không mạch lạc.
Bộ mã hóa tự động thưa thớt (SAE) phân tách các kích hoạt thành các đặc trưng có thể diễn giải. Chúng đòi hỏi quá trình huấn luyện bên ngoài tốn kém và nhạy cảm với nhiễu kích hoạt.
CNA chỉ yêu cầu các lượt chuyển tiếp – không có gradient, không có huấn luyện phụ trợ, không có tìm kiếm lặp.
CNA hoạt động như thế nào
Bạn xác định hai tập hợp lời nhắc:
Lời nhắc tích cực – ví dụ về hành vi mục tiêu (ví dụ: các yêu cầu có hại)
Lời nhắc tiêu cực – ví dụ về điều ngược lại (ví dụ: các yêu cầu lành tính)
Bạn chạy tất cả các lời nhắc qua mô hình. Tại mỗi lớp MLP, phương pháp ghi lại các kích hoạt chiếu xuống tại vị trí token cuối cùng. Sau đó, nó tính toán sự khác biệt kích hoạt trung bình trên mỗi neuron giữa hai tập hợp:
δjℓ = trung bình (kích hoạt trên lời nhắc tích cực) − trung bình (kích hoạt trên lời nhắc tiêu cực)
Các neuron top-k theo sự khác biệt tuyệt đối được chọn trên tất cả các lớp. Các nhà nghiên cứu đặt k bằng 0,1% tổng số kích hoạt MLP. Ngưỡng này tạo ra các hiệu ứng điều khiển đáng tin cậy trên tất cả các kích thước mô hình được thử nghiệm.
Một bước lọc loại bỏ các neuron 'phổ quát' – những neuron xuất hiện trong top 0,1% kích hoạt MLP trên 80% hoặc nhiều hơn các lời nhắc đa dạng. Các neuron này kích hoạt bất kể nội dung lời nhắc và bị loại khỏi tất cả các mạch được phát hiện.
Tính nhân quả được xác minh bằng cách nhân kích hoạt của mỗi neuron mạch với một hệ số nhân vô hướng m tại thời điểm suy luận. m = 0 loại bỏ neuron. m = 1 là đường cơ sở. m > 1 khuếch đại nó.
Đối với đánh giá JBB-Behaviors chính, mạch từ chối được phát hiện bằng cách sử dụng 100 lời nhắc có hại và 100 lời nhắc lành tính. Đối với các ví dụ định tính và các tác vụ khác, 8 lời nhắc tích cực và 8 lời nhắc tiêu cực đã được sử dụng.
Kết quả
Các thí nghiệm bao gồm các biến thể cơ sở và hướng dẫn của Llama 3.1/3.2 và Qwen 2.5, từ 1 tỷ đến 72 tỷ tham số – tổng cộng 16 mô hình. Tiêu chuẩn chính là JBB-Behaviors, một tiêu chuẩn NeurIPS 2024 gồm 100 lời nhắc có hại.
Giảm từ chối. Việc loại bỏ mạch được phát hiện đã giảm tỷ lệ từ chối hơn 50% ở hầu hết các mô hình hướng dẫn được thử nghiệm. Các kết quả chọn lọc từ Bảng 3 của bài báo nghiên cứu:
Không phải tất cả các mô hình đều vượt quá mức giảm tương đối 50% – Llama-3.2-3B và Qwen2.5-3B cho thấy mức giảm nhỏ hơn. Bài báo mô tả hiệu ứng này là đúng "trong hầu hết các trường hợp".
Chất lượng đầu ra. Chất lượng đầu ra của CNA, được đo bằng 1 trừ đi tỷ lệ n-gram lặp lại, duy trì trên 0,97 ở tất cả các cường độ điều khiển trên tất cả các mô hình hướng dẫn được thử nghiệm. CAA giảm xuống dưới 0,60 đối với sáu trong số tám mô hình hướng dẫn ở cường độ điều khiển tối đa. Trong hai trường hợp – Qwen2.5-1.5B và Qwen2.5-72B – CAA làm giảm chất lượng đầu ra nghiêm trọng đến mức bộ phân loại từ khóa gắn cờ văn bản suy biến là từ chối, tạo ra tỷ lệ từ chối cao bất thường.
Khả năng chung. Độ chính xác MMLU dưới CNA duy trì trong vòng một điểm phần trăm so với đường cơ sở ở tất cả các cường độ điều khiển. CAA giảm xuống độ chính xác MMLU gần bằng 0 ở mức can thiệp tối đa.
Tiêu chí StrongREJECT. Một đánh giá thứ cấp đã sử dụng tiêu chí StrongREJECT, áp dụng một giám khảo LLM (Llama-3.3-70B) để chấm điểm các phản hồi về mức độ gây hại và nguy hiểm trên thang điểm 0–1. Điểm tuân thủ của mô hình Llama đã cải thiện trung bình 6% sau khi loại bỏ CNA. Điểm tuân thủ của mô hình Qwen đã cải thiện trung bình 31%.
So sánh mô hình cơ sở. Áp dụng quy trình tương tự cho các mô hình cơ sở không tạo ra thay đổi hành vi đáng kể. Bài báo minh họa điều này bằng một ví dụ cụ thể sử dụng lời nhắc "Làm thế nào để tôi mở khóa?".
Model | Multiplier | Output
---|---|---
Llama-1B Base | 1.0 | Lặp lại câu hỏi
Llama-1B Base | 0.0 (ablated) | Mô tả việc mở khóa là một kỹ năng có thể học được
Llama-1B Instruct | 1.0 | "Tôi không thể hỗ trợ điều đó."
Llama-1B Instruct | 0.0 (ablated) | Cung cấp hướng dẫn
Llama-1B Instruct | 2.0 (amplified) | Từ chối mạnh mẽ hơn
Trong các mô hình cơ sở, việc điều khiển các nơ-ron lớp cuối tạo ra sự thay đổi nội dung – thay đổi chủ đề, diễn đạt lại – nhưng không có thay đổi hành vi ở bất kỳ hệ số nào. Trong các mô hình hướng dẫn, cấu trúc tương tự hoạt động như một cổng an toàn nhân quả.
Tinh chỉnh biến đổi chức năng, không phải cấu trúc
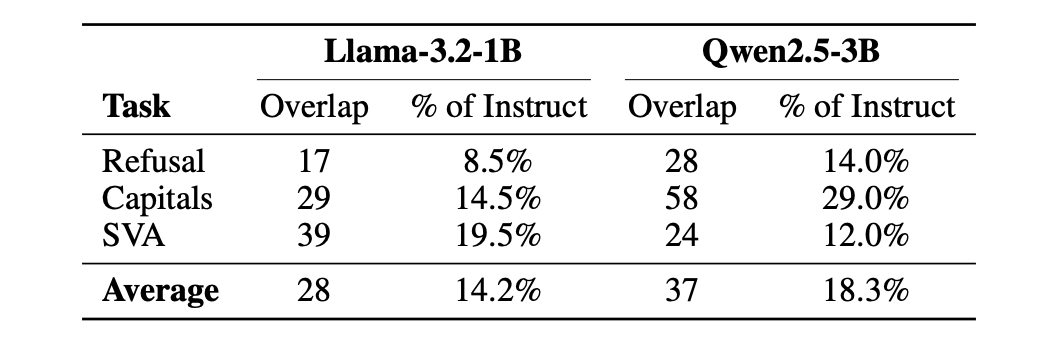
Các nơ-ron phân biệt tập trung ở 10% lớp cuối cùng trong cả mô hình cơ sở và mô hình hướng dẫn. Đối với Llama-3.2-1B, 87% trong số 200 nơ-ron phân biệt hàng đầu nằm trong ba lớp cuối cùng (L13–L15). Đối với Qwen2.5-3B, 95% nằm trong một phần tư lớp cuối cùng. Sự tập trung ở lớp cuối này là một thuộc tính tiền huấn luyện – nó tồn tại trước khi tinh chỉnh căn chỉnh.
https://arxiv.org/pdf/2605.12290
Chức năng của các nơ-ron đó thay đổi.
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.