Những phát triển gần đây trong Kiến trúc LLM: Chia sẻ KV, mHC và Chú ý nén
Ahead of AI· Sebastian Raschka, PhD· 16/5/2026models
Sau một kỳ nghỉ ngắn ngủi cùng gia đình, tôi rất vui mừng được trở lại và bắt kịp vài tuần bận rộn với các bản phát hành LLM trọng lượng mở. Điều nổi bật đối với tôi là mức độ các kiến trúc mới hơn tập trung vào hiệu quả theo ngữ cảnh dài hạn.
Khi các mô hình lý luận và quy trình làm việc của tác nhân giữ nhiều mã thông báo hơn (lâu hơn), kích thước bộ đệm KV, lưu lượng bộ nhớ và chi phí chú ý nhanh chóng trở thành những hạn chế chính và các nhà phát triển LLM đang bổ sung ngày càng nhiều thủ thuật kiến trúc để giảm những chi phí đó.
Các ví dụ chính mà tôi muốn xem xét là chia sẻ KV và nhúng theo từng lớp trong Gemma 4, lập ngân sách chú ý theo từng lớp trong
Sau một kỳ nghỉ ngắn ngủi cùng gia đình, tôi rất vui mừng được trở lại và bắt kịp vài tuần bận rộn với các bản phát hành LLM trọng lượng mở. Điều nổi bật đối với tôi là mức độ các kiến trúc mới hơn tập trung vào hiệu quả theo ngữ cảnh dài hạn.
Khi các mô hình lý luận và quy trình làm việc của tác nhân giữ nhiều mã thông báo hơn (lâu hơn), kích thước bộ đệm KV, lưu lượng bộ nhớ và chi phí chú ý nhanh chóng trở thành những hạn chế chính và các nhà phát triển LLM đang bổ sung ngày càng nhiều thủ thuật kiến trúc để giảm những chi phí đó.
Các ví dụ chính mà tôi muốn xem xét là chia sẻ KV và nhúng mỗi lớp trong Gemma 4, lập ngân sách chú ý theo lớp trong Laguna XS.2, chú ý tích chập được nén trong ZAYA1-8B và mHC cộng với chú ý được nén trong DeepSeek V4.
Hầu hết những thay đổi này trông giống như những điều chỉnh nhỏ trong sơ đồ kiến trúc của tôi, nhưng một số trong số chúng là những thay đổi thiết kế khá phức tạp đáng để thảo luận chi tiết hơn.
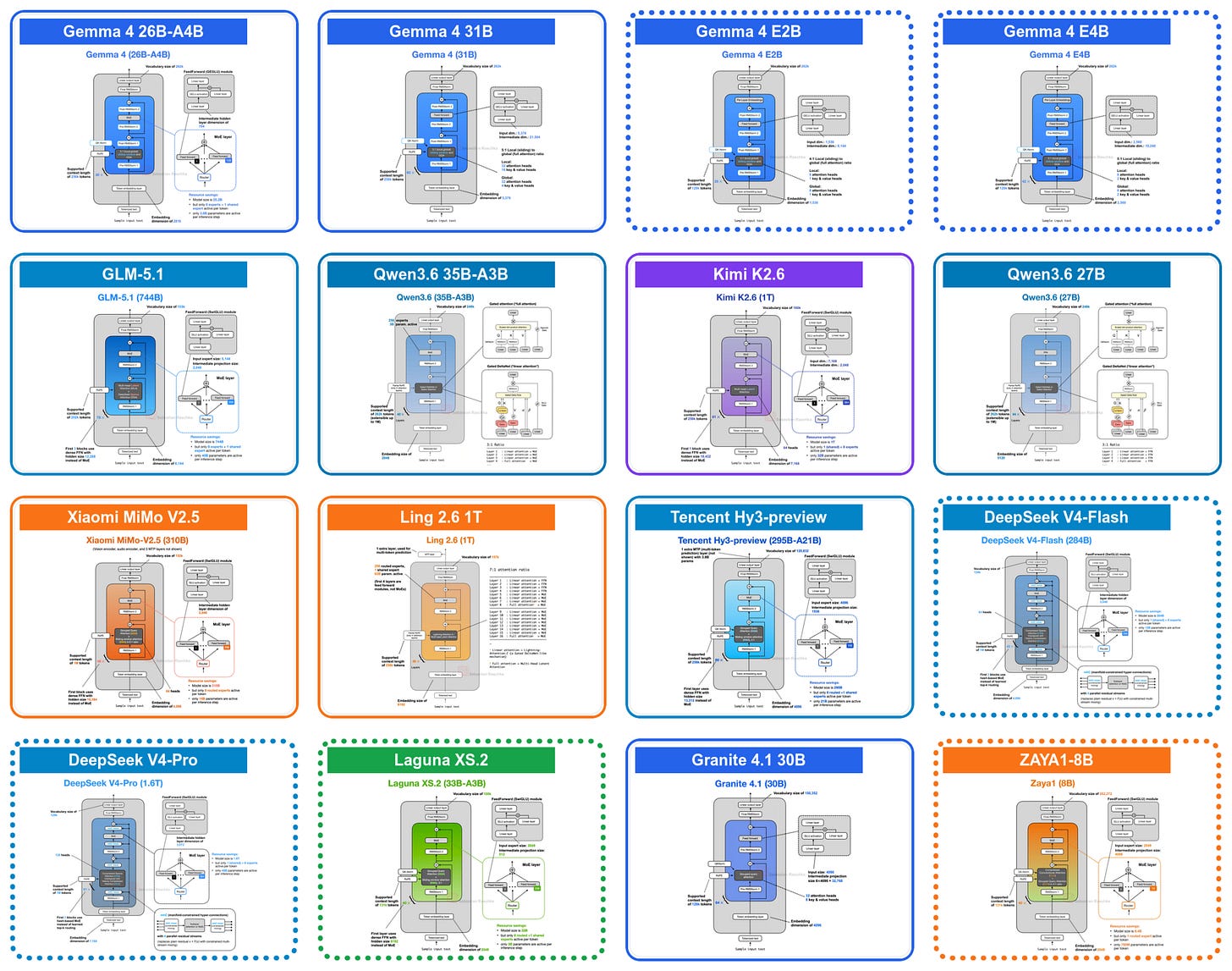
Hình 1. Bản vẽ kiến trúc LLM của các bản phát hành trọng lượng mở lớn gần đây (tháng 4 đến tháng 5). Bạn có thể tìm thấy hình ảnh và thông tin chi tiết khác trong thư viện kiến trúc LLM của tôi. Không phải tất cả các kích cỡ mô hình đều được hiển thị; Qwen3.6 bao gồm các biến thể 27B và 35B-A3B, và ZAYA1 được thể hiện bằng mô hình 8B (bỏ qua cơ sở ZAYA1 và cơ sở lý luận ZAYA1). Kiến trúc trong các hộp chấm được đề cập chi tiết hơn trong bài viết này.
Lưu ý rằng bài viết này nói về thiết kế kiến trúc, vì vậy tôi sẽ chủ yếu bỏ qua việc kết hợp tập dữ liệu, lịch đào tạo, chi tiết sau đào tạo, công thức RL, bảng điểm chuẩn và so sánh sản phẩm. Ngay cả với phạm vi hẹp hơn đó, vẫn có rất nhiều điều cần giải quyết. Và, như mọi khi, bài viết dài hơn tôi mong đợi, vì vậy tôi sẽ tập trung vào những thay đổi bên trong khối biến áp, luồng dư, bộ đệm KV hoặc tính toán chú ý.
Cũng xin lưu ý rằng tôi chỉ đề cập đến những chủ đề là những lựa chọn thiết kế thú vị (mới) và tôi chưa đề cập đến những chủ đề khác. Danh sách này bao gồm:
Chia sẻ KV và nhúng mỗi lớp trong Gemma 4
Sự chú ý tích chập được nén trong ZAYA1
Chú ý lập ngân sách ở Laguna XS.2
mHC và nén sự chú ý trong DeepSeek V4
Chủ đề trước đó
Trước khi đi vào phần mới, đây là 2 bài viết trước mình sẽ tham khảo lại. Phần đầu tiên cung cấp nền tảng kiến trúc rộng hơn về các mô hình MoE gần đây, các chuyên gia định tuyến, các tham số hoạt động và so sánh kích thước mô hình. Phần thứ hai bao gồm nền chú ý xuất hiện liên tục bên dưới, bao gồm MHA, MQA, GQA, MLA, chú ý theo cửa sổ trượt, chú ý thưa thớt và thiết kế chú ý kết hợp.
Tôi cũng đã chuyển một số giải thích này thành các trang hướng dẫn ngắn, độc lập trong Thư viện Kiến trúc LLM. Ví dụ: người đọc có thể tìm thấy phần giải thích ngắn gọn về GQA, MLA, sự chú ý của cửa sổ trượt, Chú ý thưa thớt DeepSeek, định tuyến MoE và các khái niệm khác được liên kết từ thẻ mô hình và nhãn khái niệm tương ứng.
1. Tái sử dụng KV Tensors trên các lớp để thu nhỏ bộ đệm (Gemma 4)
Đối với chuyến tham quan về những tiến bộ và cải tiến về kiến trúc này, chúng ta sẽ quay trở lại đầu tháng 4 khi Google phát hành bộ mô hình Gemma 4 trọng lượng mở mới của họ. Chúng có 3 loại lớn:
các mô hình Gemma 4 E2B và E4B dành cho thiết bị di động và thiết bị cục bộ nhỏ (được nhúng) (còn gọi là IoT),
mô hình hỗn hợp các chuyên gia (MoE) Gemma 4 26B, được tối ưu hóa để suy luận cục bộ hiệu quả,
và mô hình dày đặc Gemma 4 31B, cho chất lượng tối đa và thuận tiện hơn sau đào tạo (vì MoE khó làm việc hơn)
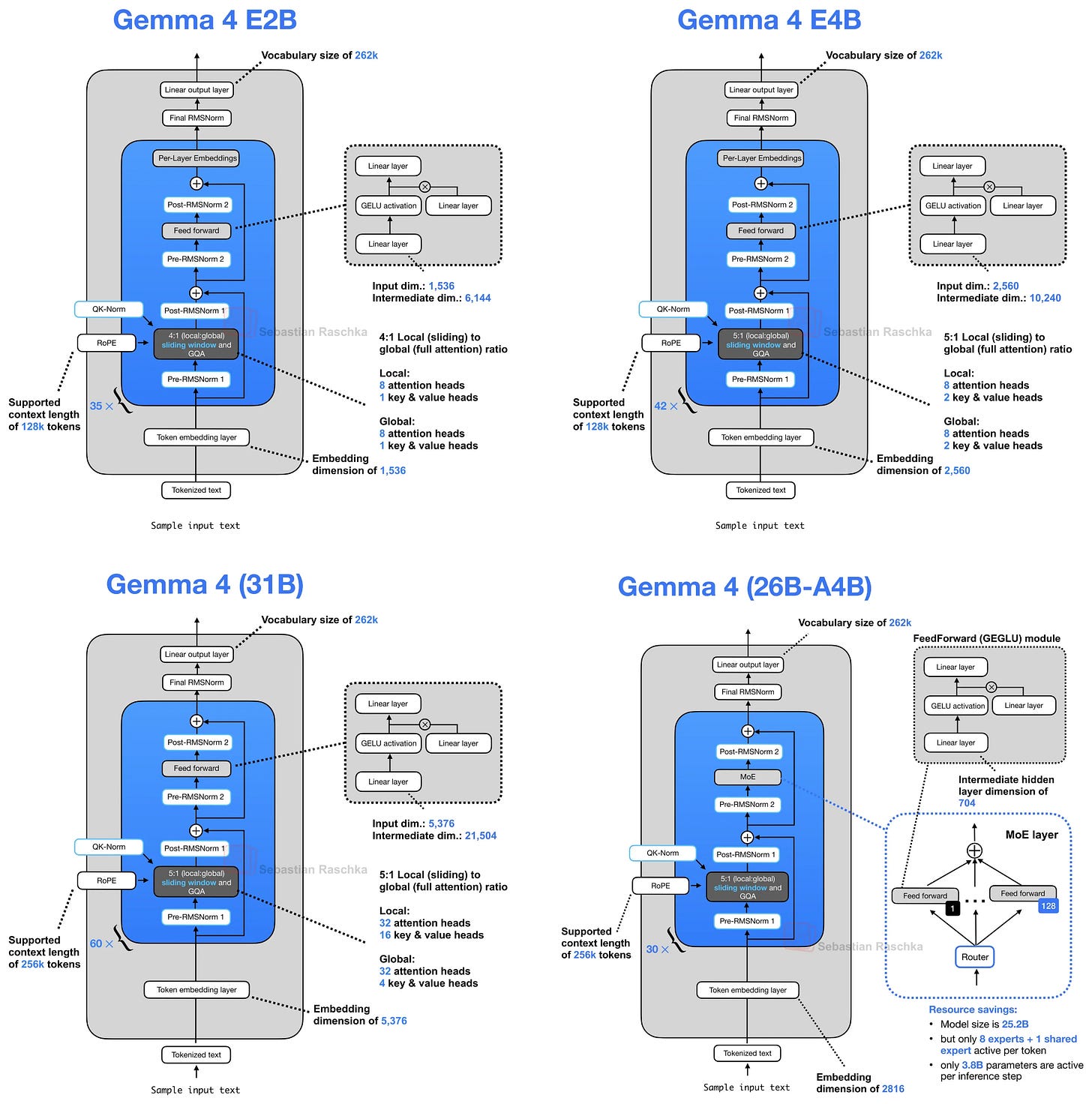
Hình 2: Bản vẽ kiến trúc Gemma 4.
Điều chỉnh kiến trúc nhỏ đầu tiên trong các biến thể E2B và E4B là chúng áp dụng sơ đồ bộ đệm KV dùng chung, trong đó các lớp sau sử dụng lại trạng thái khóa-giá trị từ các lớp trước đó để giảm bộ nhớ ngữ cảnh dài và tính toán.
Tính năng chia sẻ KV này không phải do Gemma 4 phát minh ra. Ví dụ: xem Brandon và cộng sự, “Giảm kích thước bộ nhớ đệm giá trị khóa của máy biến áp bằng sự chú ý giữa các lớp” (NeurIPS 2024). Nhưng đây là kiến trúc phổ biến đầu tiên mà tôi thấy khái niệm này được áp dụng. (Không nên nhầm lẫn sự chú ý xuyên lớp với sự chú ý chéo.)
Trước khi giải thích thêm về việc chia sẻ KV, hãy nói ngắn gọn về động cơ. Như tôi đã viết và nói trong những tháng gần đây, một trong những chủ đề chính gần đây trong thiết kế kiến trúc LLM là giảm kích thước bộ đệm KV. Đổi lại, động lực đằng sau việc giảm kích thước bộ đệm KV là để giảm bộ nhớ cần thiết, cho phép chúng ta làm việc với các bối cảnh dài hơn, điều này đặc biệt phù hợp trong thời đại của các mô hình và tác nhân lý luận. Để biết thêm thông tin cơ bản về bộ đệm KV, hãy xem bài viết “Tìm hiểu và mã hóa bộ đệm KV trong LLM từ đầu” của tôi:
Trên thực tế, tất cả các biến thể chú ý phổ biến mà tôi đã mô tả trong bài viết Hướng dẫn trực quan về các biến thể chú ý trong LLM hiện đại đều được thiết kế để giảm kích thước bộ đệm KV:
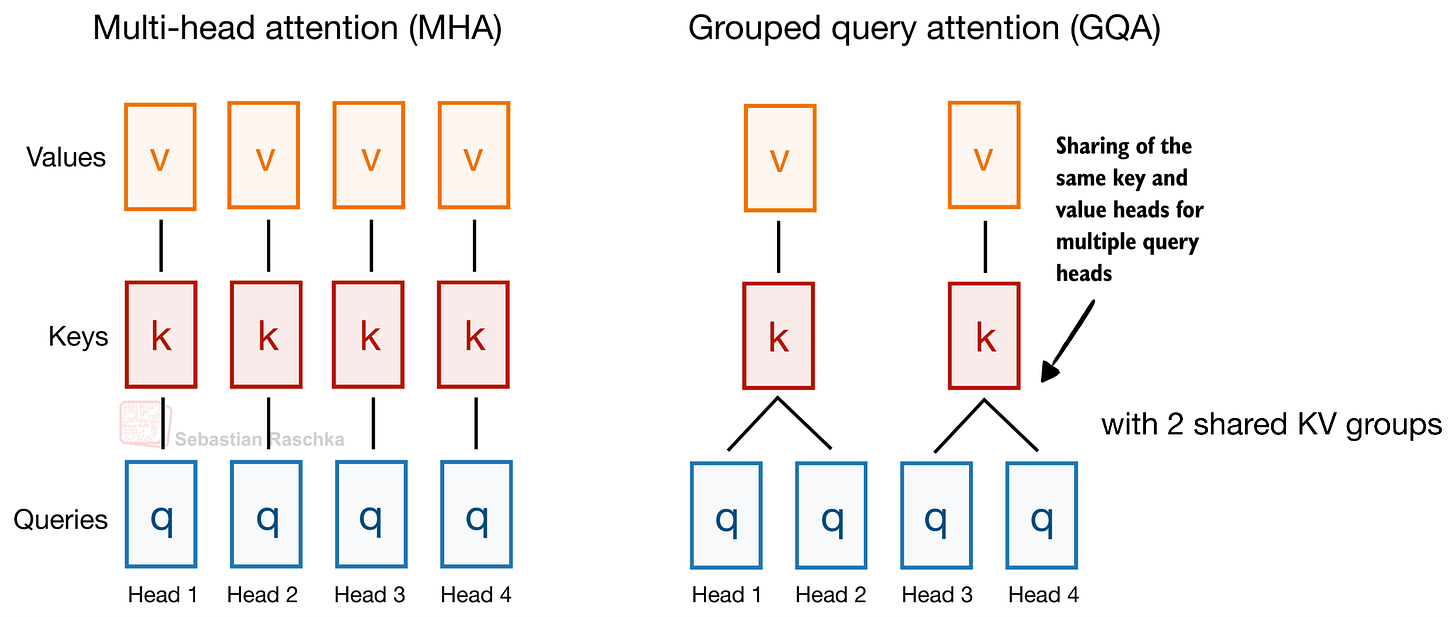
Để chọn một ví dụ cổ điển (mà Gemma 4 vẫn sử dụng): Chú ý truy vấn được nhóm (GQA) đã chia sẻ các đầu khóa-giá trị (KV) trên các đầu truy vấn khác nhau để giảm kích thước bộ đệm KV, như được minh họa trong hình bên dưới.
Hình 3: Chú ý truy vấn được nhóm (GQA) chia sẻ cùng một đầu khóa (K) và giá trị (V) giữa nhiều đầu truy vấn (Q).
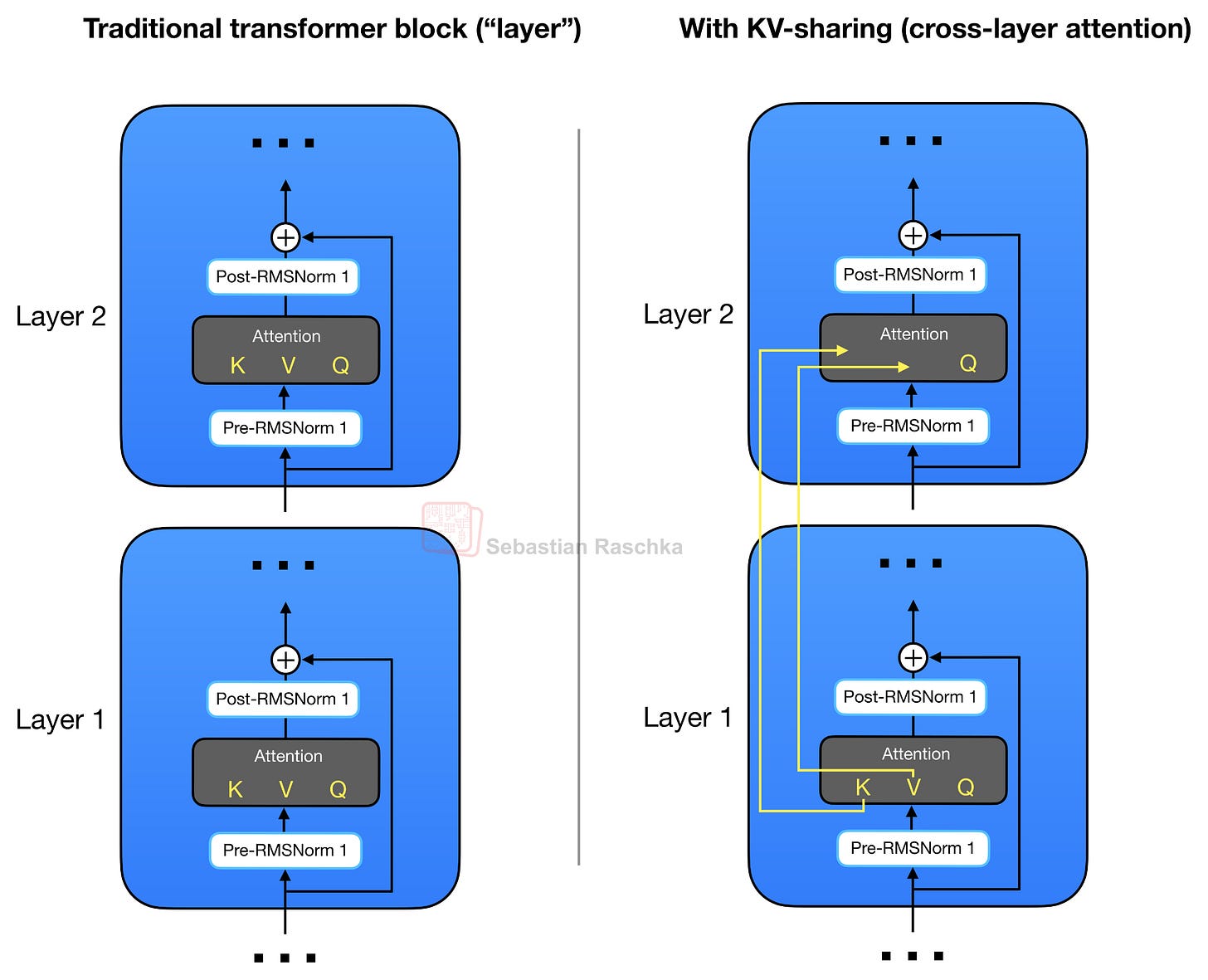
Như đã đề cập trước đó, Gemma 4 sử dụng GQA. Tuy nhiên, ngoài việc chia sẻ KV giữa các truy vấn như một phần của GQA, Gemma 4 còn chia sẻ các phép chiếu KV trên các lớp khác nhau thay vì tính toán nó như một phần của mô-đun chú ý trong mỗi lớp. Sơ đồ chia sẻ KV này, còn được gọi là sự chú ý giữa các lớp, được minh họa trong hình bên dưới.
Hình 4: Các khối biến áp thông thường tính toán các phép chiếu Q, K và V riêng biệt trong mỗi mô-đun chú ý (trái). Các thiết kế chú ý nhiều lớp (phải) có chung các hình chiếu K và V trên nhiều lớp.
Như được gợi ý ngắn gọn trong phần tổng quan về kiến trúc trong Hình 2, Gemma 4 E2B sử dụng GQA thông thường và sự chú ý của cửa sổ trượt theo mẫu 4:1. (Chính xác hơn là Gemma 4 E2B sử dụng MQA, đây là trường hợp đặc biệt một đầu KV của GQA).
Trong trường hợp GQA (hoặc MQA), việc chia sẻ KV hoạt động như thế này. Các lớp sau không còn tính toán các phép chiếu khóa và giá trị của riêng chúng nữa mà sử dụng lại các tensor KV từ lớp không chia sẻ gần đây nhất trước đó
Nguồn tin: Ahead of AI — Tác giả: Sebastian Raschka, PhD. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.