Miso Labs đã phát hành MisoTTS, một mô hình chuyển văn bản thành giọng nói (text-to-speech) mã nguồn mở với 8 tỷ tham số. Mô hình này tạo ra giọng nói biểu cảm từ cả văn bản và ngữ cảnh âm thanh. MisoTTS sử dụng lượng tử hóa vector dư (RVQ) để mở rộng dải âm thanh, tránh việc mở rộng một từ vựng phẳng duy nhất trong khi vẫn giữ nguyên số lượng tham số.
MisoTTS là gì?
MisoTTS là một mô hình RVQ Transformer chuyển văn bản thành hội thoại với 8 tỷ tham số. Mô hình này được lấy cảm hứng từ kiến trúc Sesame CSM, kết hợp một kiến trúc nền tảng kiểu Llama 3.2 với một bộ giải mã âm thanh nhỏ hơn. MisoTTS tạo ra mã âm thanh Mimi từ văn bản và ngữ cảnh âm thanh tùy chọn. Mô hình này hoạt động dựa trên điều kiện của cả hai yếu tố.
Miso Labs đã phát hành MisoTTS, một mô hình chuyển văn bản thành giọng nói (text-to-speech) với trọng số mở (open-weights) và 8 tỷ tham số. Mô hình này tạo ra giọng nói biểu cảm từ cả văn bản và ngữ cảnh âm thanh. MisoTTS sử dụng lượng tử hóa vector dư (RVQ) để mở rộng dải âm thanh, tránh việc mở rộng một từ vựng phẳng duy nhất trong khi vẫn giữ nguyên số lượng tham số.
**MisoTTS là gì?**
MisoTTS là một Transformer RVQ chuyển văn bản thành hội thoại với 8 tỷ tham số. Mô hình này lấy cảm hứng từ kiến trúc Sesame CSM, kết hợp một lõi (backbone) kiểu Llama 3.2 với một bộ giải mã âm thanh nhỏ hơn. MisoTTS tạo ra các mã âm thanh Mimi từ văn bản và ngữ cảnh âm thanh tùy chọn. Mô hình này điều kiện dựa trên cả văn bản và âm thanh trước đó. Đầu vào thứ hai cho phép mô hình phản hồi tông giọng của người nói.
Từ vựng văn bản có 128.256 token và có 32 sổ mã âm thanh (audio codebooks). Mimi là bộ mã hóa âm thanh (audio tokenizer) và độ dài chuỗi tối đa là 2.048. Quá trình suy luận mặc định chạy trong torch.bfloat16.
Miso Labs tuyên bố độ trễ 110ms. Hãng này liệt kê ElevenLabs có độ trễ 700ms và Sesame là 300ms.
**Vấn đề kích thước từ vựng**
Các Transformer tiêu chuẩn tạo ra từ một từ vựng cố định gồm các token rời rạc. Điều này hoạt động khi một từ vựng nhỏ có thể bao phủ không gian mục tiêu. Tuy nhiên, giọng nói của con người không phù hợp với giả định đó, vì nó thay đổi về cao độ, nhịp điệu, trọng âm, cảm xúc và giọng điệu.
Mở rộng từ vựng âm thanh là giải pháp rõ ràng. Nhưng các từ vựng lớn hơn đòi hỏi nhiều tham số hơn trong một Transformer tiêu chuẩn. Mỗi token phải được mô hình biểu diễn và dự đoán. Miso Labs gọi đây là vấn đề kích thước từ vựng.
Vấn đề thứ hai là điều kiện hóa. Hầu hết các mô hình TTS chỉ điều kiện dựa trên văn bản. Chúng bỏ qua tông giọng của người đối thoại. Miso Labs lập luận rằng điều này góp phần tạo ra hiệu ứng "thung lũng kỳ lạ" (uncanny valley).
**Lượng tử hóa vector dư: Ý tưởng cốt lõi**
MisoTTS giải quyết cả hai vấn đề bằng lượng tử hóa vector dư (RVQ). Miso Labs truy nguyên RVQ từ nghiên cứu tạo ảnh và từ CSM của Sesame cho âm thanh. Thay vì một chỉ mục token, mô hình phát ra một vector các chỉ mục.
Mỗi token âm thanh là 32 chỉ mục sổ mã trên các sổ mã 2048 chiều. Mô hình giữ một sổ mã riêng cho mỗi vị trí trong vector. Để khôi phục âm thanh, mô hình tổng hợp các vector đã tra cứu. Mỗi sổ mã bổ sung một sự tinh chỉnh khác cho tín hiệu.
Đây là điều làm cho việc mở rộng quy mô hoạt động. Từ vựng có thể địa chỉ bằng kích thước sổ mã lũy thừa độ sâu. Tăng độ sâu không thêm tham số vào mô hình. Do đó, MisoTTS đạt khoảng 2048^32, hay khoảng 10^105 token có thể địa chỉ. Miso Labs lưu ý rằng việc mở rộng quy mô một cách ngây thơ sẽ đòi hỏi một mạng lưới lớn hơn nhiều.
https://www.misolabs.ai/blog/miso-tts-8b
**Kiến trúc hai Transformer**
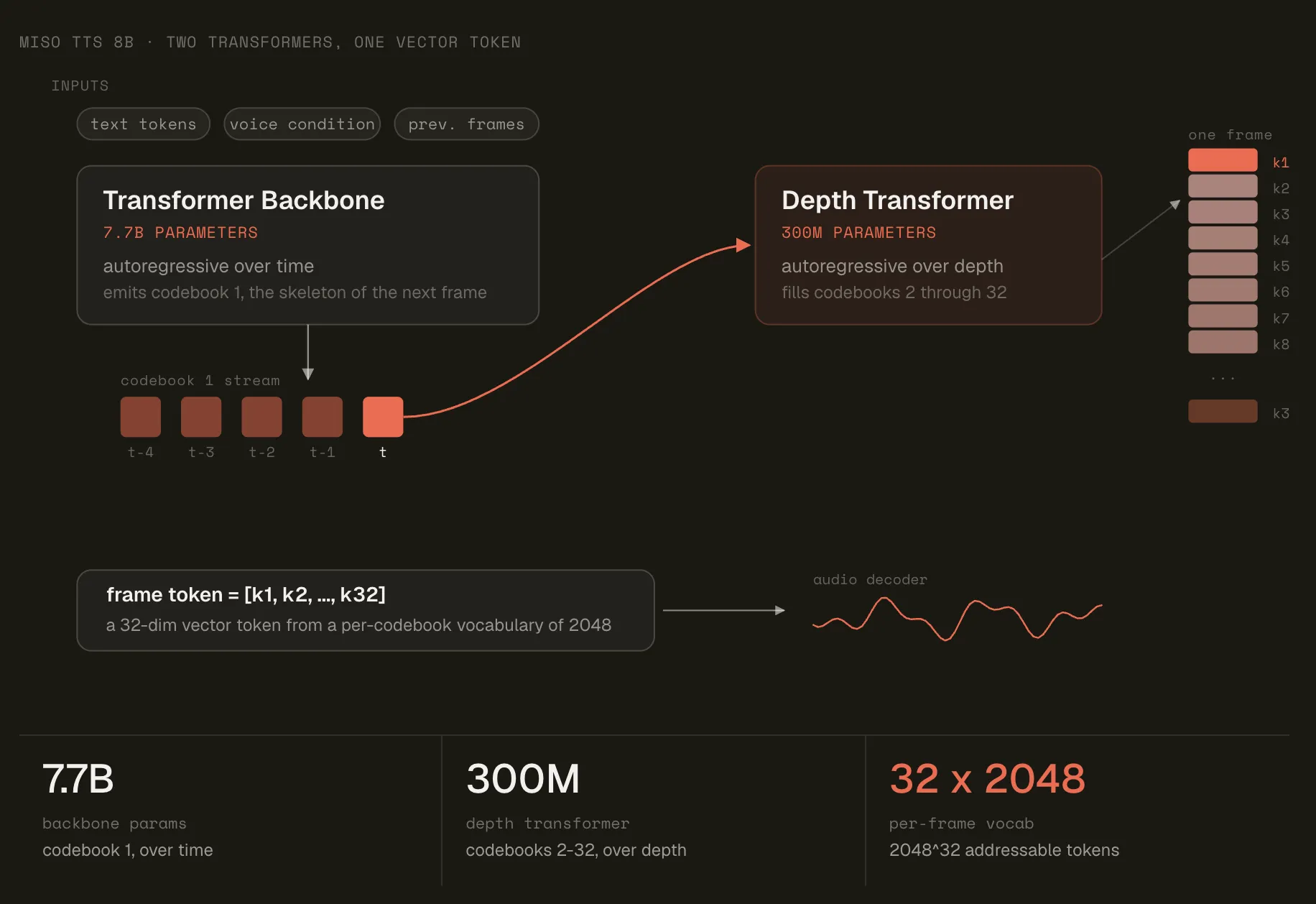
Mô hình được chia thành một lõi (backbone) và một bộ giải mã (decoder). Lõi là một Transformer 7,7 tỷ tham số, tự hồi quy theo thời gian. Nó dự đoán chỉ mục sổ mã đầu tiên và trạng thái ẩn cuối cùng.
Một bộ giải mã 300 triệu tham số sau đó chạy tự hồi quy theo độ sâu. Nó dự đoán các chỉ mục sổ mã còn lại, từng vị trí một. Mỗi dự đoán điều kiện dựa trên các chỉ mục đã được chọn trong khung. Cùng 300 triệu tham số được tái sử dụng cho mọi vị trí.
Các nhúng (embeddings) tuân theo cùng một logic. Các token văn bản sử dụng một lần tra cứu duy nhất. Nhúng của một token âm thanh là tổng của các lần tra cứu sổ mã theo từng vị trí. Việc xen kẽ văn bản và âm thanh cho phép lõi sử dụng lịch sử hội thoại. Đây là cách nó mang ngữ cảnh qua các lượt.
**Điểm mạnh và thách thức**
Điểm mạnh:
* Trọng số mở ngay từ ngày đầu, theo giấy phép MIT đã sửa đổi.
* RVQ mở rộng dải âm thanh mà không tăng số lượng tham số.
* Điều kiện dựa trên ngữ cảnh âm thanh, không chỉ văn bản.
* Triển khai cục bộ giữ dữ liệu âm thanh nhạy cảm trong nội bộ.
Kiến trúc và các phép toán được ghi lại trong một bài đăng blog công khai.
Thách thức:
Chỉ bán song công, chưa có cơ chế luân phiên.
Mô hình lớn yêu cầu GPU CUDA mạnh mẽ.
Quyền truy cập API đã được công bố nhưng chưa khả dụng.
Các tuyên bố về độ trễ và chất lượng vẫn cần được bên thứ ba kiểm tra.
Giải thích trực quan của Marktechpost
Marktechpost · Tóm tắt mô hình
01 / 09
Phát hành mã nguồn mở · ngày 3/6/2026
MisoTTS
Mô hình chuyển văn bản thành giọng nói biểu cảm 8B từ Miso Labs, được xây dựng trên lượng tử hóa vector dư (residual vector quantization) và được điều kiện hóa bởi cả văn bản và âm thanh.
8B tham số
RVQ Transformer
Mã Mimi
Giấy phép MIT sửa đổi
MisoTTS là gì
Một RVQ Transformer chuyển văn bản thành hội thoại
Một mô hình 8B tham số lấy cảm hứng từ kiến trúc Sesame CSM.
Kết hợp một kiến trúc lõi kiểu Llama 3.2 với một bộ giải mã âm thanh nhỏ hơn.
Tạo mã âm thanh Mimi từ văn bản và ngữ cảnh âm thanh tùy chọn.
Điều kiện hóa trên âm thanh trước đó, do đó đầu ra phản ứng với tông giọng của người nói.
Sơ lược
Thông số kỹ thuật đã công bố
Tham số
8B (7.7B + 300M)
Kiến trúc
RVQ Transformer
Sổ mã âm thanh
32 (2048 chiều)
Bộ mã hóa âm thanh
Mimi
Từ vựng văn bản
128.256
Độ dài chuỗi tối đa
2.048
Độ chính xác mặc định
torch.bfloat16
Giấy phép
MIT sửa đổi
Động lực
Vấn đề kích thước từ vựng
Các Transformer tạo ra từ một từ vựng cố định gồm các token rời rạc.
Giọng nói thay đổi về cao độ, nhịp điệu, trọng âm, cảm xúc và giọng điệu.
Một từ vựng âm thanh lớn hơn cần nhiều tham số hơn trong một Transformer tiêu chuẩn.
Hầu hết các TTS chỉ điều kiện hóa trên văn bản, bỏ qua tông giọng — hiệu ứng "thung lũng kỳ lạ" (uncanny valley).
Ý tưởng cốt lõi
Lượng tử hóa vector dư
Mô hình phát ra một vector các chỉ số, không phải một chỉ số token duy nhất.
Mỗi token là 32 chỉ số sổ mã trên các sổ mã 2048 chiều.
Tổng hợp các vector đã tra cứu sẽ tái tạo âm thanh.
Độ sâu mở rộng từ vựng có thể địa chỉ hóa lên đến ~2048^32 (≈10^105) mà không cần thêm tham số.
Kiến trúc
Hai Transformer, một token vector
Backbone (7.7B) — tự hồi quy theo thời gian; dự đoán chỉ số sổ mã k_1 và trạng thái ẩn h_0.
Decoder (300M) — tự hồi quy theo độ sâu; dự đoán k_2 đến k_32.
Cùng 300M tham số được tái sử dụng cho mọi vị trí.
Văn bản và âm thanh xen kẽ cho phép backbone sử dụng lịch sử hội thoại.
Chạy cục bộ
Suy luận trong vài dòng mã
from generator import load_miso_8b
import torchaudio
gen = load_miso_8b(device="cuda",
model_path_or_repo_id="MisoLabs/MisoTTS")
audio =
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.