Microsoft đã phát hành Fara1.5: Một bộ tác nhân sử dụng máy tính trên trình duyệt (4B/9B/27B) vượt trội hơn OpenAI Operator và Gemini 2.5 Computer Use trên Online-Mind2Web.
Phòng thí nghiệm AI Frontiers của Microsoft Research đã phát hành Fara1.5, một dòng mô hình tác nhân sử dụng máy tính (CUA) dành cho trình duyệt. Phiên bản này bao gồm ba kích thước: Fara1.5-4B, Fara1.5-9B và Fara1.5-27B. Các mô hình được tích hợp với MagenticLite, giao diện trình duyệt được bảo vệ (sandboxed) của Microsoft dành cho các tác nhân này.
Các tác nhân sử dụng máy tính là các mô hình từ pixel đến hành động, điều khiển một trình duyệt thực. Chúng đọc ảnh chụp màn hình và tạo ra các hành động chuột và bàn phím để hoàn thành nhiệm vụ. Các sản phẩm tác nhân gần đây như Operator của OpenAI và Gemini 2.5 Computer Use của Google thuộc loại này.
Fara1.5-27B đạt 72 điểm.
Phòng thí nghiệm AI Frontiers của Microsoft Research đã phát hành Fara1.5. Đây là một họ các mô hình tác nhân sử dụng máy tính (CUA) dành cho trình duyệt. Phiên bản này bao gồm ba kích thước: Fara1.5-4B, Fara1.5-9B và Fara1.5-27B. Các mô hình được tích hợp với MagenticLite, giao diện trình duyệt được bảo vệ (sandboxed) của Microsoft dành cho các tác nhân này.
Các tác nhân sử dụng máy tính là các mô hình từ pixel đến hành động, điều khiển một trình duyệt thực. Chúng đọc ảnh chụp màn hình và phát ra các hành động chuột và bàn phím để hoàn thành nhiệm vụ. Các sản phẩm tác nhân gần đây như Operator của OpenAI và Gemini 2.5 Computer Use của Google thuộc loại này.
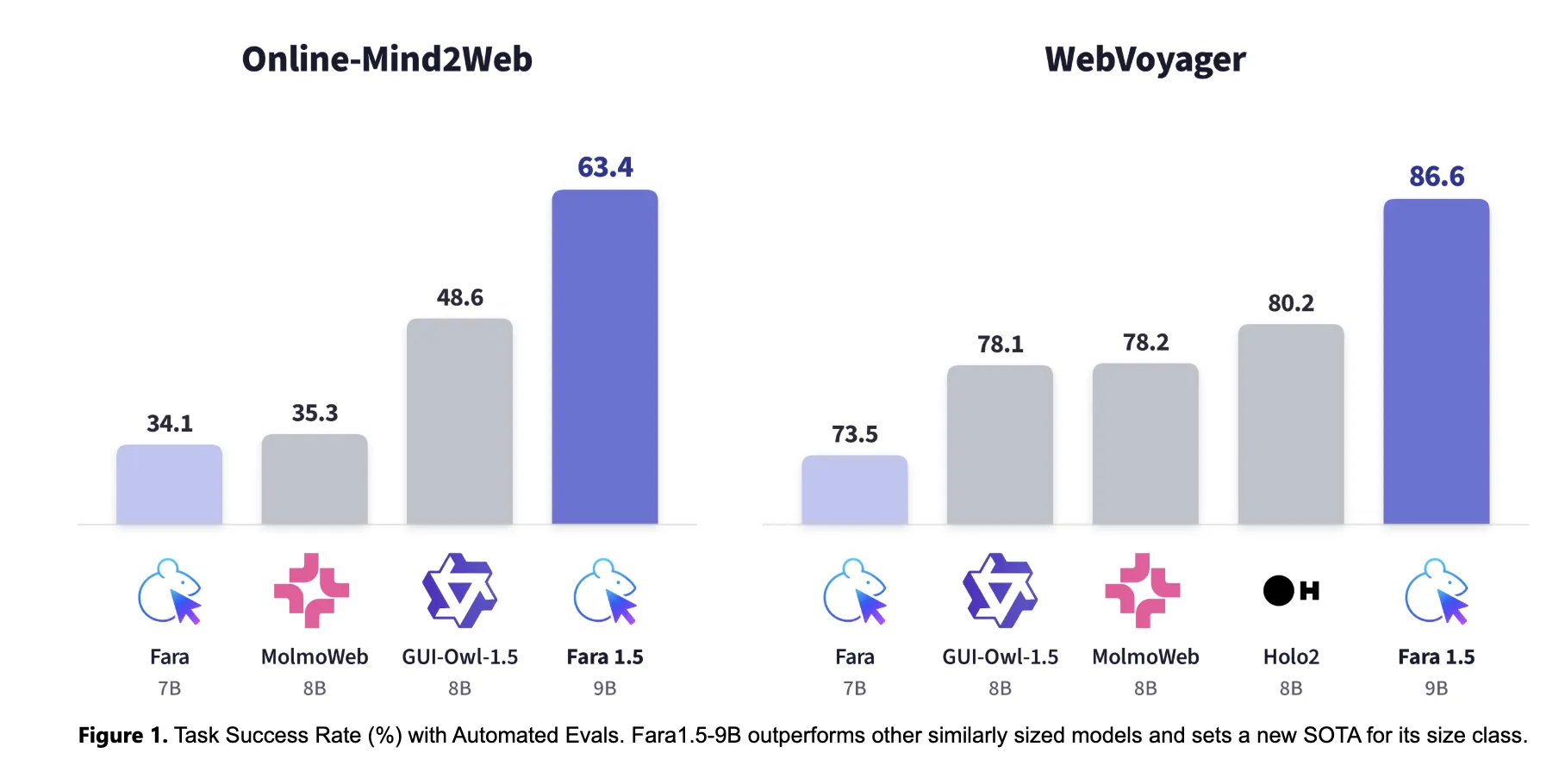
Fara1.5-27B đạt 72% tỷ lệ thành công nhiệm vụ trên Online-Mind2Web. Điểm chuẩn này bao gồm 300 nhiệm vụ trên 136 trang web phổ biến. Trong cùng một đánh giá, Operator của OpenAI đạt 58,3% và Gemini 2.5 Computer Use đạt 57,3%. Navigator n1 của Yutori đạt 64,7% và Fara1.5-9B đạt 63,4%. Con số này gần như gấp đôi so với phiên bản tiền nhiệm Fara-7B, vốn đạt 34,1% trên cùng một điểm chuẩn.
https://www.microsoft.com/en-us/research/articles/fara1-5-computer-use-agent/
Kiến trúc và vòng lặp tác nhân
Các mô hình sử dụng các điểm kiểm tra cơ sở Qwen3.5 trong các biến thể 4B, 9B và 27B của chúng. Chúng hoạt động thông qua một vòng lặp quan sát-suy nghĩ-hành động. Ở mỗi bước, mô hình lấy lịch sử hội thoại trước đó và ba ảnh chụp màn hình trình duyệt gần đây nhất. Sau đó, nó phát ra suy nghĩ và một hành động tiếp theo duy nhất.
Không gian hành động bao gồm các đầu vào chuột và bàn phím tiêu chuẩn và các hành động cụ thể trên web như tìm kiếm web. Nó cũng cung cấp các hành động meta để quản lý ngữ cảnh. Chúng bao gồm ghi nhớ các sự kiện để sử dụng sau này và đặt câu hỏi làm rõ cho người dùng. Các hành động meta này cho phép tác nhân hoạt động trong thời gian dài hơn và làm việc cộng tác với người dùng.
Tập dữ liệu huấn luyện
Việc huấn luyện sử dụng tinh chỉnh có giám sát trên khoảng hai triệu mẫu. Tập dữ liệu bao gồm 60% quỹ đạo web và 12,8% môi trường tổng hợp. Điền biểu mẫu và tương tác người dùng chiếm 12,5%. Grounding đóng góp 8,8% và VQA 4,9%. Các phần nhỏ hơn bao gồm kéo thả GUI, tuân thủ hướng dẫn và an toàn. Mất mát chỉ được áp dụng cho ba lượt gần đây nhất trong mỗi quỹ đạo.
https://www.microsoft.com/en-us/research/articles/fara1-5-computer-use-agent/
FaraGen1.5: quy trình dữ liệu tổng hợp
FaraGen1.5 là quy trình tổng hợp đã tạo ra các quỹ đạo huấn luyện. Nó có ba thành phần mô-đun: môi trường, bộ giải và bộ xác minh.
Môi trường được chia thành hai loại. Các nhiệm vụ trên internet mở chạy trên các trang web trực tiếp không yêu cầu đăng nhập. Các nhiệm vụ trên miền có cổng yêu cầu các phiên xác thực hoặc thực hiện các hành động không thể đảo ngược, như gửi email.
Đối với các miền có cổng, nhóm đã xây dựng sáu bản sao tổng hợp có tên FaraEnvs. Chúng bao gồm Mail, Calendar, Stream, ML, Stay và Scheduler. Mỗi bản sao có một giao diện người dùng thực tế, một API đầy đủ chức năng và một cơ sở dữ liệu với dữ liệu hạt giống dựa trên nhân vật.
Các môi trường này được xây dựng bằng GitHub Copilot CLI cùng với sự tinh chỉnh lặp đi lặp lại của con người. Vì nhóm kiểm soát toàn bộ hệ thống, họ biết kết quả chính xác cho mọi nhiệm vụ. Đối với các nhiệm vụ thay đổi phần phụ trợ, một LLM (mô hình ngôn ngữ lớn) đánh giá so sánh các ảnh chụp nhanh cơ sở dữ liệu trước và sau khi thực hiện. Các nhiệm vụ không thay đổi trạng thái được chấm điểm dựa trên các câu trả lời tham chiếu được tính toán trước.
Tác nhân giải quyết sử dụng GPT-5.4 của OpenAI với các công cụ tùy chỉnh phản ánh không gian hành động của Fara1.5. Tác nhân giải quyết đạt 83% trên Online-Mind2Web bằng cách sử dụng WebJudge tự động. Tác nhân giải quyết Fara-7B trước đó đạt 67% trên cùng một đánh giá. Một trình mô phỏng người dùng được gọi khi tác nhân giải quyết đưa ra lệnh ask_user hoặc khi nó hoàn thành một nhiệm vụ.
Ba bộ kiểm định sẽ quyết định quỹ đạo nào được đưa vào huấn luyện. Tính đúng đắn sử dụng các tiêu chí do LLM tạo ra cho các tác vụ trên internet mở và đánh giá cơ sở dữ liệu đặc quyền cho các tác vụ tổng hợp. Hiệu quả sẽ xử phạt các hành động thừa hoặc không cần thiết. Kiểm định tương tác người dùng sẽ kiểm tra xem tác nhân có tạm dừng tại các điểm quan trọng hay không.
Các điểm quan trọng và an toàn
Fara1.5 được huấn luyện để dừng lại và hỏi người dùng trong ba tình huống. Thứ nhất: tác vụ yêu cầu thông tin cá nhân mà người dùng chưa cung cấp. Thứ hai: mô tả tác vụ không rõ ràng hoặc thiếu các chi tiết cần thiết để thực hiện. Thứ ba: một hành động không thể đảo ngược sắp được thực hiện mà chưa có sự chấp thuận trước.
Huấn luyện an toàn sử dụng các bộ dữ liệu an toàn công cộng và các tác vụ nội bộ phù hợp với Chính sách AI có trách nhiệm của Microsoft. Bên trong MagenticLite, tất cả các hành động của tác nhân đều được ghi lại và có thể kiểm tra. Trình duyệt được bảo vệ (sandboxed browser) cũng đóng vai trò là ranh giới bảo mật giữa tác nhân và máy của người dùng.
Các tiêu chuẩn khác
Trên WebVoyager, Fara1.5-27B đạt 88,6%, phiên bản 9B đạt 86,6% và phiên bản 4B đạt 80,8%. Phiên bản 9B cũng vượt trội so với các đối thủ cùng kích thước như MolmoWeb 8B, GUI-Owl-1.5 8B và Holo2 8B. Tất cả các lần chạy đánh giá Fara1.5 đều sử dụng Browserbase để ổn định các phiên và giảm tình trạng chặn cấp phiên. Các con số được tính trung bình trên ba lần chạy độc lập.
Trên WebTailBench v1.5, một tiêu chuẩn nhắm mục tiêu các tác vụ web đuôi dài, Fara1.5-9B đạt 64,5% thành công quy trình và 32,3% thành công kết quả. GPT-5.4 đạt 79,6% quy trình và 57,4% kết quả trên cùng tiêu chuẩn này.
Những điểm chính
Dưới đây là 5 điểm chính tóm tắt trong một dòng:
Microsoft Research đã phát hành Fara1.5, một dòng tác nhân sử dụng máy tính trên trình duyệt với các kích thước 4B, 9B và 27B, được xây dựng trên Qwen3.5.
Fara1.5-27B đạt 72% trên Online-Mind2Web, vượt qua OpenAI Operator (58,3%), Gemini 2.5 CU (57,3%) và Yutori Navigator n1 (64,7%).
Quy trình dữ liệu tổng hợp FaraGen1.5 mở khóa khả năng huấn luyện trên các miền được kiểm soát thông qua sáu bản sao ứng dụng chức năng (FaraEnvs) được xây dựng bằng GitHub Copilot CLI.
Fara1.5 tạm dừng để hỏi người dùng tại các điểm quan trọng: thiếu thông tin, tác vụ không rõ ràng hoặc hành động không thể đảo ngược mà không có sự chấp thuận.
Xem chi tiết kỹ thuật. Ngoài ra, hãy theo dõi chúng tôi trên Twitter và đừng quên tham gia Cộng đồng ML SubReddit hơn 150 nghìn thành viên của chúng tôi và Đăng ký nhận Bản tin của chúng tôi. Bạn có dùng Telegram không? Bây giờ bạn cũng có thể tham gia cùng chúng tôi trên Telegram.
Cần hợp tác với chúng tôi để quảng bá Kho lưu trữ GitHub HOẶC Trang Hugging Face HOẶC Phát hành sản phẩm HOẶC Hội thảo trên web của bạn, v.v.? Liên hệ với chúng tôi.
Bài đăng Microsoft phát hành Fara1.5: Một dòng tác nhân sử dụng máy tính trên trình duyệt (4B/9B/27B) vượt trội hơn OpenAI Operator.
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.