Các mô hình ngôn ngữ lớn (LLM) trở nên tĩnh sau giai đoạn tiền huấn luyện. Kiến thức của chúng không được cập nhật khi thế giới thay đổi. Việc huấn luyện lại toàn bộ một LLM là quá tốn kém ở quy mô hiện tại. Tinh chỉnh (fine-tuning) có nguy cơ làm suy giảm kiến thức đã học trước đó. Tạo sinh có tăng cường truy xuất (RAG) gặp khó khăn khi các câu trả lời đòi hỏi suy luận từ nhiều tài liệu.
Một nhóm các nhà nghiên cứu từ Đại học Quốc gia Singapore, MIT CSAIL, A*STAR và Liên minh Singapore-MIT về Nghiên cứu và Công nghệ (SMART) đề xuất một phương pháp mới có tên MEMO (Memory as a Model - Bộ nhớ như một Mô hình).
MEMO Giải quyết Vấn đề Gì?
Các phương pháp hiện có để tích hợp n
Các mô hình ngôn ngữ lớn (LLM) trở nên tĩnh sau giai đoạn tiền huấn luyện. Kiến thức của chúng không được cập nhật khi thế giới thay đổi. Việc huấn luyện lại toàn bộ một LLM là quá tốn kém ở quy mô hiện tại. Tinh chỉnh (fine-tuning) có nguy cơ làm suy giảm kiến thức đã học trước đó. Tạo sinh có tăng cường truy xuất (RAG) gặp khó khăn khi các câu trả lời đòi hỏi suy luận trên nhiều tài liệu.
Một nhóm các nhà nghiên cứu từ Đại học Quốc gia Singapore, MIT CSAIL, A*STAR và Liên minh Singapore-MIT về Nghiên cứu và Công nghệ (SMART) đề xuất một phương pháp mới gọi là MEMO (Memory as a Model – Bộ nhớ như một Mô hình).
MEMO giải quyết vấn đề gì?
Các phương pháp hiện có để tích hợp kiến thức mới vào LLM thuộc ba loại. Các phương pháp phi tham số như RAG truy xuất tài liệu tại thời điểm suy luận. Chúng nhạy cảm với nhiễu truy xuất và gặp khó khăn với suy luận liên tài liệu. Các phương pháp tham số như tiền huấn luyện liên tục hoặc tinh chỉnh có giám sát nội hóa kiến thức vào trọng số mô hình. Chúng tốn kém về mặt tính toán và gây ra hiện tượng quên thảm khốc, trong đó việc huấn luyện mới làm suy giảm kiến thức đã thu được trước đó. Các phương pháp bộ nhớ tiềm ẩn nén kiến thức thành các token mềm. Các biểu diễn này gắn chặt với mô hình đã tạo ra chúng — một hạn chế mà nhóm nghiên cứu gọi là khớp nối biểu diễn (representation coupling), giới hạn khả năng chuyển giao giữa các LLM.
BỘ NHỚ như một Mô hình Riêng biệt
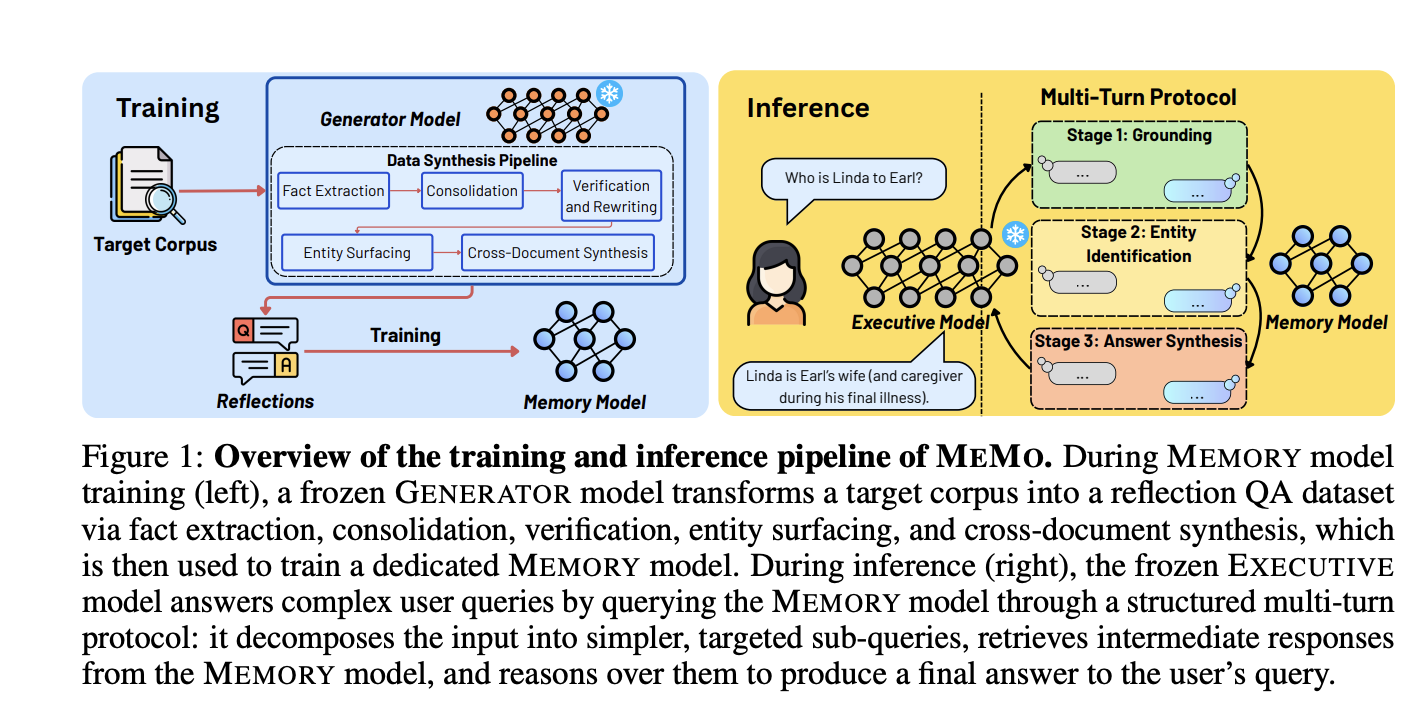
MEMO tách bộ nhớ khỏi suy luận. Mô hình BỘ NHỚ là một mô hình ngôn ngữ nhỏ, chuyên dụng được huấn luyện để nội hóa kiến thức từ một tập dữ liệu mục tiêu. Mô hình ĐIỀU HÀNH (EXECUTIVE) là LLM chính — được đóng băng và chỉ được truy vấn thông qua giao diện đầu vào-đầu ra tiêu chuẩn của nó.
Trong các thử nghiệm, mô hình BỘ NHỚ là Qwen2.5-14B-Instruct. Mô hình ĐIỀU HÀNH là Qwen2.5-32B-Instruct hoặc Gemini-3-Flash, một mô hình độc quyền, mã nguồn đóng. Vì MEMO coi mô hình ĐIỀU HÀNH như một hộp đen, nó không yêu cầu quyền truy cập trọng số hoặc logit đầu ra.
https://arxiv.org/pdf/2605.15156
Cách mô hình BỘ NHỚ được huấn luyện
Quá trình huấn luyện bắt đầu với một quy trình tổng hợp dữ liệu gồm năm bước được hướng dẫn bởi một mô hình TẠO SINH (GENERATOR) — Qwen2.5-32B-Instruct trong các thử nghiệm. Quy trình này chuyển đổi một tập tài liệu thô thành một tập dữ liệu QA phản ánh: các cặp câu hỏi-trả lời đại diện cho kiến thức của tập dữ liệu dưới các biến thể truy vấn đa dạng.
Năm bước bao gồm:
Trích xuất sự kiện — trích xuất trực tiếp các sự kiện được nêu rõ ràng và trích xuất gián tiếp thông tin suy luận, chạy song song trên mỗi đoạn tài liệu.
Hợp nhất — các cặp QA có chung ngữ cảnh (thực thể, khoảng thời gian, mối quan hệ) được hợp nhất thành các cặp đa sự kiện.
Xác minh và viết lại — mỗi cặp QA được kiểm tra tính tự chứa. Các cặp có đại từ không được giải quyết hoặc tham chiếu ngầm được viết lại bằng cách sử dụng đoạn nguồn hoặc bị loại bỏ.
Làm nổi bật thực thể — các cặp QA được tạo ra trong đó các câu hỏi mã hóa các thuộc tính và mối quan hệ của thực thể, và các câu trả lời tiết lộ danh tính của thực thể. Điều này nhằm mục đích giải quyết vấn đề đảo ngược (reversal curse), trong đó các mô hình được huấn luyện trên "A là B" không suy luận được "B là A".
Tổng hợp liên tài liệu — mô hình TẠO SINH xây dựng các cặp QA trải rộng trên nhiều tài liệu. Nó xác định hai loại kết nối liên tài liệu: các manh mối hội tụ (nhiều tài liệu về cùng một thực thể) và các thuộc tính song song (các thực thể khác nhau chia sẻ một thuộc tính hoặc vai trò chung).
Bước 5 là thành phần quan trọng nhất. Một phép loại bỏ từng phần (leave-one-out ablation) cho thấy rằng việc loại bỏ bước này làm giảm độ chính xác từ 24,00% xuống 6,37% trên NarrativeQA. Đây cũng là nguồn chính của các cặp huấn luyện trong tập dữ liệu cuối cùng.
Mô hình MEMORY sau đó được huấn luyện thông qua tinh chỉnh có giám sát (SFT). Sai số được tính toán chỉ trên các mã thông báo trả lời. Các tài liệu nguồn không bao giờ được cung cấp trong quá trình suy luận. Mô hình phải trả lời từ kiến thức tham số nội hóa.
Suy luận: Giao thức đa lượt có cấu trúc
Trong quá trình suy luận, mô hình EXECUTIVE truy vấn mô hình MEMORY thông qua một giao thức đa lượt có cấu trúc với ba giai đoạn tuần tự.
Giai đoạn 1: Định vị. Mô hình EXECUTIVE phân tách truy vấn thành các câu hỏi phụ nguyên tử. Mỗi câu hỏi phụ nhắm mục tiêu một ràng buộc nhận dạng duy nhất. Mô hình MEMORY trả lời từng câu hỏi một cách độc lập.
Giai đoạn 2: Nhận dạng thực thể. Sử dụng các phản hồi định vị, mô hình EXECUTIVE đưa ra các truy vấn phụ tiếp theo có mục tiêu. Nó lặp đi lặp lại thu hẹp các thực thể ứng cử viên cho đến khi một thực thể được xác nhận hoặc ngân sách giai đoạn hết.
Giai đoạn 3: Tìm kiếm và tổng hợp câu trả lời. Dựa trên thực thể đã được xác định, mô hình EXECUTIVE truy vấn mô hình MEMORY để tìm các dữ kiện hỗ trợ. Sau đó, nó tổng hợp tất cả các phản hồi đã truy xuất thành một câu trả lời cuối cùng.
Các phản hồi của mô hình MEMORY là các đoạn ngôn ngữ tự nhiên nhỏ gọn. Độ dài của chúng không phụ thuộc vào kích thước tập dữ liệu, do đó chi phí truy xuất không tăng theo số lượng tài liệu. Điều này trái ngược với RAG, nơi chi phí suy luận tăng theo tập dữ liệu.
Kết quả thực nghiệm
MEMO được đánh giá trên ba bộ dữ liệu chuẩn: BrowseComp-Plus (nghiên cứu sâu đa bước), NarrativeQA (hiểu diễn ngôn qua sách và kịch bản phim) và MuSiQue (lý luận 2–4 bước qua các đoạn Wikipedia). Các mô hình cơ sở bao gồm BM25, NV-Embed-V2, HippoRAG2 và Cartridges. Cartridges yêu cầu quyền truy cập hộp trắng vào mô hình EXECUTIVE và đạt 0,00% trên BrowseComp-Plus và 3,75% trên NarrativeQA.
Trên NarrativeQA với Gemini-3-Flash, MEMO đạt 53,58%. HippoRAG2 đạt 23,21% trên cùng thiết lập. Trên MuSiQue, MEMO đạt 60,20% so với 57,00% của HippoRAG2. Trên BrowseComp-Plus, MEMO đạt 66,67% so với 66,33% của HippoRAG2.
Với Qwen2.5-32B-Instruct làm mô hình EXECUTIVE, MEMO đạt 54,22% trên BrowseComp-Plus và 48,30% trên MuSiQue. Chuyển sang Gemini-3-Flash mang lại mức tăng 12,45%, 26,73% và 11,90% trên ba bộ dữ liệu chuẩn. Mô hình MEMORY không được huấn luyện lại khi mô hình EXECUTIVE thay đổi.
Khả năng chống nhiễu truy xuất: Nhóm nghiên cứu đánh giá hiệu suất khi các tài liệu gây nhiễu được thêm vào tập dữ liệu. NV-Embed-V2 và HippoRAG2 giảm tới 6,22% trên BrowseComp-Plus khi một tài liệu tiêu cực được thêm vào mỗi tài liệu bằng chứng. Độ chính xác của MEMO trên cùng bộ dữ liệu chuẩn thay đổi +0,55% — trong phạm vi một độ lệch chuẩn.
Kiến trúc mô hình MEMORY
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.