Lựa chọn cơ sở dữ liệu vector phù hợp cho các ứng dụng RAG và AI
Các ứng dụng AI hiện đại dựa vào việc hiểu ý nghĩa thay vì chỉ khớp từ khóa. Khi các mô hình ngôn ngữ lớn (LLM), tìm kiếm ngữ nghĩa và hệ thống RAG trở nên phổ biến, cơ sở dữ liệu vector đã nổi lên như một hạ tầng quan trọng để lưu trữ và truy xuất các embedding (biểu diễn vector) có chiều cao ở quy mô lớn. Việc lựa chọn cơ sở dữ liệu vector phù hợp có thể có tác động lớn đến hiệu suất, khả năng mở rộng, chi phí và trải nghiệm của nhà phát triển. Bài viết Choosing the Right Vector Database for RAG and AI Applications xuất hiện lần đầu trên Analytics Vidhya.
So sánh cơ sở dữ liệu vector: Chọn đúng DB
Hội nghị AI tương lai nhất của Ấn Độ đã trở lại – Lớn hơn, Sắc nét hơn, Táo bạo hơn
Nhận thông tin chi tiết
Các khóa học miễn phí
Đường dẫn học tập
Chương trình tăng tốc
Chương trình GenAI Pinnacle
GenAI Pinnacle Plus
Người tiên phong AI Agentic
DeepSeek
DataHack Summit 2025
DHS 2026
Đăng nhập
Chuyển chế độ
Đăng xuất
Chuẩn bị phỏng vấn
Sự nghiệp
GenAI
Kỹ thuật nhắc lệnh (Prompt Engg)
ChatGPT
LLM
Langchain
RAG
AI Agents
Học máy (Machine Learning)
Học sâu (Deep Learning)
Công cụ GenAI
LLMOps
Python
NLP
SQL
Dự án AIML
Danh sách đọc
Đường dẫn học tập phân tích dữ liệu
Cách trở thành nhà phân tích dữ liệu vào năm 2025: Lộ trình hoàn chỉnh
Đường dẫn học tập Tableau
Lộ trình học tập toàn diện về Tableau vào năm 2025
Đường dẫn học tập NLP
Lộ trình học tập NLP toàn diện 2025
Đường dẫn học tập nhà khoa học dữ liệu
Lộ trình học tập để trở thành nhà khoa học dữ liệu vào năm 2025
Đường dẫn học tập kỹ sư dữ liệu
Lộ trình từng bước để trở thành kỹ sư dữ liệu vào năm 2025
Đường dẫn học tập MLOps
Lộ trình học tập MLOps toàn diện: Phiên bản 2025
Đường dẫn học tập kỹ sư AI
Lộ trình để trở thành kỹ sư AI vào năm 2025
Đường dẫn học tập thị giác máy tính
Lộ trình học tập toàn diện để thành thạo thị giác máy tính vào năm 2025
Đường dẫn học tập AI tạo sinh (Generative AI)
Lộ trình tốt nhất để học AI tạo sinh vào năm 2025
Lộ trình AI tạo sinh cho doanh nghiệp
Lộ trình GenAI cho doanh nghiệp
Lộ trình LLM
Các mô hình ngôn ngữ lớn được giải mã: Lộ trình dành cho người mới bắt đầu
Đường dẫn học tập kỹ sư nhắc lệnh (Prompt Engineer)
Lộ trình học tập để trở thành chuyên gia kỹ thuật nhắc lệnh
Trang chủ
Cơ sở dữ liệu vector
Chọn đúng cơ sở dữ liệu vector cho RAG và các ứng dụng AI
Chọn đúng cơ sở dữ liệu vector cho RAG và các ứng dụng AI
Vipin Vashisth
Cập nhật lần cuối: 08/6/2026
22 phút đọc
Các ứng dụng AI hiện đại dựa vào việc hiểu ý nghĩa thay vì chỉ khớp từ khóa. Khi các mô hình ngôn ngữ lớn (LLM), tìm kiếm ngữ nghĩa và hệ thống RAG (Retrieval Augmented Generation) trở nên phổ biến, cơ sở dữ liệu vector đã nổi lên như một cơ sở hạ tầng quan trọng để lưu trữ và truy xuất các nhúng (embedding) có chiều cao ở quy mô lớn.
Việc chọn đúng cơ sở dữ liệu vector có thể có tác động lớn đến hiệu suất, khả năng mở rộng, chi phí và trải nghiệm của nhà phát triển. Trong bài viết này, chúng tôi sẽ so sánh sáu cơ sở dữ liệu vector hàng đầu như Pinecone, Weaviate, Qdrant, Milvus, pgvector và ChromaDB, để giúp bạn xác định lựa chọn phù hợp nhất cho trường hợp sử dụng của mình.
Mục lục
Tìm hiểu về cơ sở dữ liệu vector
Cách hoạt động của tìm kiếm vector
Tại sao cơ sở dữ liệu truyền thống gặp khó khăn với tìm kiếm ngữ nghĩa
So sánh nhanh
Tạo tập dữ liệu mẫu
So sánh hiệu suất
Kết luận
Tìm hiểu về cơ sở dữ liệu vector
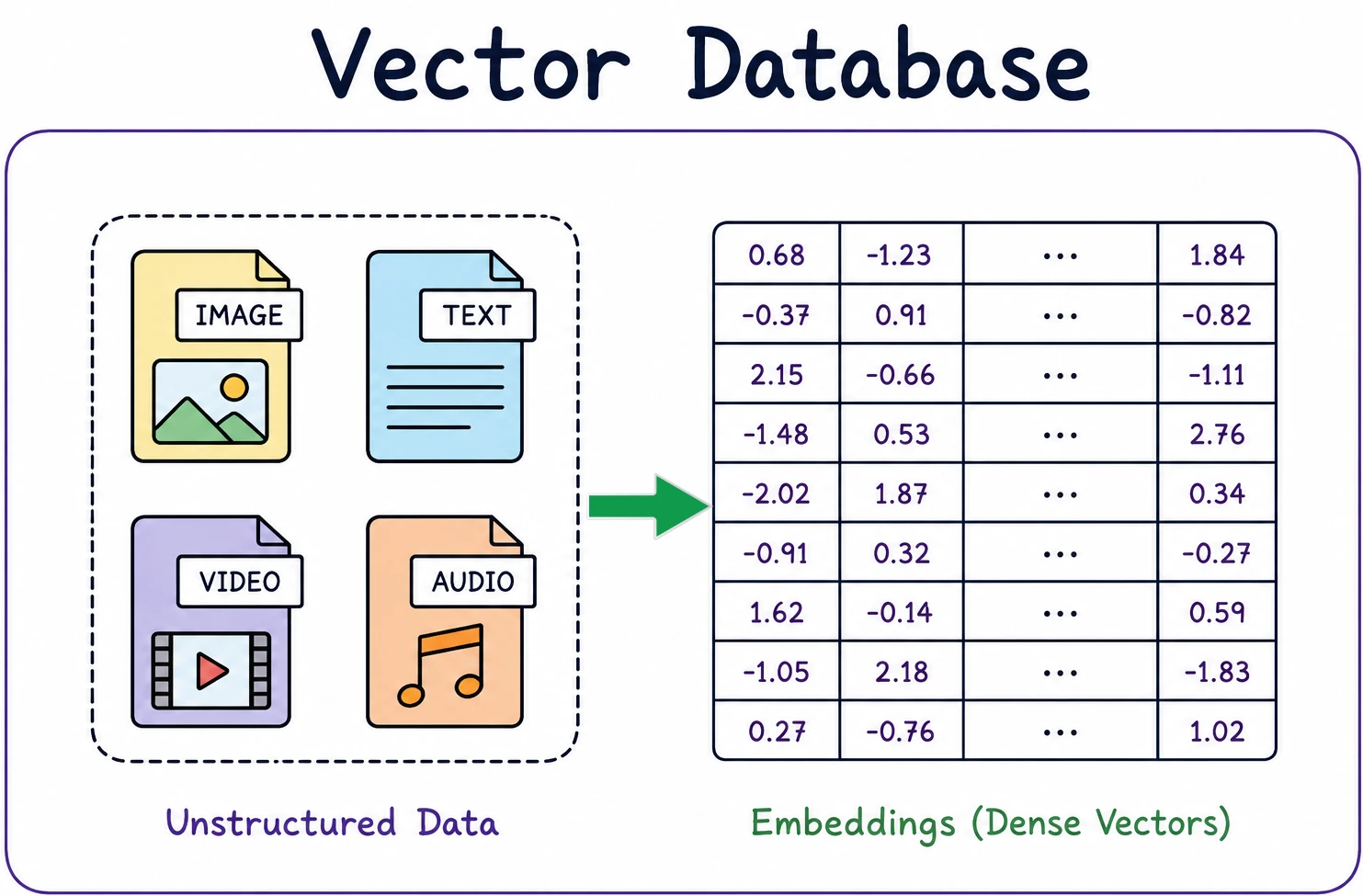
Trước khi xem xét các cơ sở dữ liệu cụ thể, bạn phải hiểu cơ sở dữ liệu vector là gì và tại sao chúng lại quan trọng. Cơ sở dữ liệu truyền thống lưu trữ các hàng và cột có cấu trúc. Mặt khác, cơ sở dữ liệu vector lưu trữ thứ gì đó trừu tượng hơn nhiều – các mẫu toán học về ý nghĩa, thường được gọi là nhúng (embedding).
Cơ sở dữ liệu vector là gì?
Cơ sở dữ liệu vector về cơ bản là một hệ thống lưu trữ chuyên biệt được xây dựng để lưu trữ và truy vấn dữ liệu vector đa chiều. Có thể hình dung một vector là một dãy số dài. Ví dụ, [0.12, -0.45, 0.78, …] mã hóa nội dung ngữ nghĩa của một phần thông tin nhất định. Một câu có thể được chuyển đổi thành một vector với 384 giá trị, hoặc đôi khi là 1536, tùy thuộc vào mô hình.
Khi có hàng nghìn vector như vậy, không thể tìm kiếm thủ công từng vector mỗi lần. Cần một phương pháp hiệu quả để nhanh chóng truy xuất các vector tương tự nhất với một câu hỏi hoặc đầu vào nào đó. Đó chính là chức năng của cơ sở dữ liệu vector. Nó sắp xếp các vector để việc tra cứu lân cận gần nhất diễn ra cực kỳ nhanh chóng.
Embeddings là gì?
Embeddings là các biểu diễn số của dữ liệu được tạo ra bởi các mô hình học máy, một dạng đầu ra. Một mô hình embedding nhận văn bản, hình ảnh hoặc âm thanh đầu vào và sau đó xuất ra một mảng số thực có kích thước cố định. Những con số này phản ánh các mối quan hệ ngữ nghĩa. Ví dụ, "king" (vua) và "queen" (hoàng hậu) sẽ có các embedding gần nhau hơn so với "king" và "bicycle" (xe đạp).
Một số mô hình embedding được sử dụng rộng rãi nhất là:
OpenAI text-embedding-3-small: 1536 chiều, chất lượng tuyệt vời
sentence-transformers/all-MiniLM-L6-v2: 384 chiều, miễn phí và nhanh
Cohere embed-v3: 1024 chiều, hỗ trợ đa ngôn ngữ tốt
Google text-embedding-004: 768 chiều, mô hình đa năng mạnh mẽ
Mô hình embedding được chọn thực sự ảnh hưởng đến chất lượng tìm kiếm vector. Để có kết quả tốt nhất, luôn sử dụng cùng một mô hình cho việc lập chỉ mục và truy vấn, nếu không mọi thứ có thể bị sai lệch.
Cách thức hoạt động của tìm kiếm vector
Tìm kiếm vector về cơ bản là tìm kiếm các mục có ý nghĩa tương tự với một truy vấn. Người dùng nhập truy vấn, chuyển đổi nó thành một vector, sau đó yêu cầu cơ sở dữ liệu tìm kiếm các vector đã lưu trữ "gần" với nó. Cơ sở dữ liệu thường dựa vào các thuật toán lân cận gần nhất xấp xỉ (ANN) để có thể tìm thấy các kết quả phù hợp mà không cần quét từng vector một.
Ba phép đo độ tương tự chính hỗ trợ tìm kiếm vector là:
Độ tương tự Cosine: Độ tương tự Cosine xem xét góc giữa hai vector. Điểm 1 có nghĩa là chúng cùng hướng, gần như giống hệt nhau. 0 báo hiệu chúng không liên quan. -1 có nghĩa là chúng đối lập, gần như phủ định lẫn nhau.
cosine_similarity(A, B) = (A · B) / (||A|| × ||B||)
Khoảng cách Euclidean: Khoảng cách Euclidean đo lường t


Nguồn tin: Analytics Vidhya — Tác giả: Vipin Vashisth. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.