
LLM của bạn chỉ tốt như những gì nó truy xuất được
Trong nghiên cứu của tôi về phát hiện ảo giác trong hệ thống LLM đa tác nhân, những phát hiện nhất quán nhất không phải về kích thước mô hình, thiết kế kịp thời hoặc nhiệt độ suy luận. Đó là về việc thu hồi. Chất lượng truy xuất kém là yếu tố dự báo đáng tin cậy nhất về kết quả đầu ra bị suy giảm trên mọi cấu hình đường ống mà tôi đã nghiên cứu. Bằng chứng từ các quy trình thử nghiệm của chúng tôi là rõ ràng: khi quá trình truy xuất bị hỏng, mô hình ngôn ngữ sẽ không bù đắp được. Nó ngoại suy. Nó lấp đầy những khoảng trống bằng nội dung nghe có vẻ hợp lý nhưng thực tế lại không có cơ sở và làm như vậy với cùng một sự trôi chảy và đồng đều.
Trong nghiên cứu của tôi về phát hiện ảo giác trong hệ thống LLM đa tác nhân, những phát hiện nhất quán nhất không phải về kích thước mô hình, thiết kế kịp thời hoặc nhiệt độ suy luận. Đó là về việc thu hồi. Chất lượng truy xuất kém là yếu tố dự báo đáng tin cậy nhất về kết quả đầu ra bị suy giảm trên mọi cấu hình đường ống mà tôi đã nghiên cứu.
Bằng chứng từ các quy trình thử nghiệm của chúng tôi là rõ ràng: khi quá trình truy xuất bị hỏng, mô hình ngôn ngữ sẽ không bù đắp được. Nó ngoại suy. Nó lấp đầy những khoảng trống bằng nội dung nghe có vẻ hợp lý nhưng thực tế lại không có căn cứ và làm như vậy với sự trôi chảy và tự tin tương tự như khi áp dụng cho các kết quả đầu ra chính xác. Kết quả là một chế độ lỗi vừa mang tính hệ thống vừa đặc biệt khó phát hiện nếu không có cơ sở hạ tầng đánh giá chuyên dụng.
Bài đăng này dựa trên nghiên cứu đó để đưa ra phân tích có cấu trúc, trực tiếp với người thực hành về chất lượng truy xuất: nó là gì, tại sao nó quan trọng hơn hầu hết các nhóm nhận ra, nó thất bại như thế nào trong thực tế và những gì có thể làm để cải thiện nó. Cho dù bạn đang xây dựng quy trình RAG sản xuất hay thiết kế hệ thống đa tác nhân, các nguyên tắc ở đây đều áp dụng trực tiếp vào độ tin cậy của những gì LLM của bạn cuối cùng tạo ra.
Tìm hiểu lớp truy xuất trong hệ thống RAG
Thế hệ tăng cường truy xuất (RAG) giải quyết một trong những hạn chế cơ bản của các mô hình ngôn ngữ lớn: không có khả năng truy cập thông tin vượt quá giới hạn đào tạo hoặc bên ngoài phân phối đào tạo của họ. Trong kiến trúc RAG, một kho lưu trữ kiến thức bên ngoài, điển hình là cơ sở dữ liệu vectơ, được truy vấn tại thời điểm suy luận để cung cấp cho mô hình bối cảnh liên quan trước khi bắt đầu tạo.
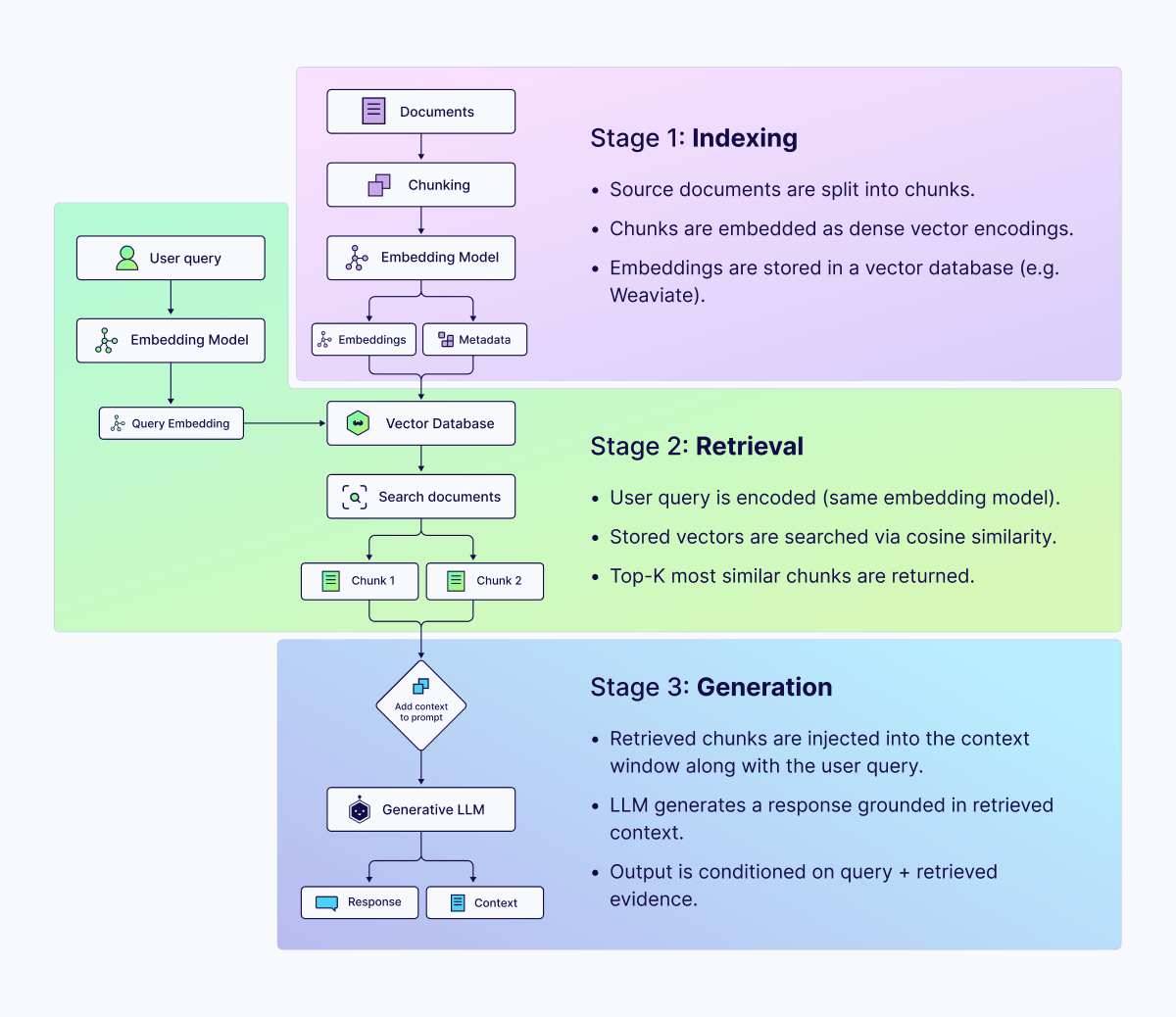
Đường ống hoạt động theo ba giai đoạn liên tiếp:
Lập chỉ mục: Tài liệu nguồn được phân đoạn thành các khối, được mã hóa dưới dạng biểu diễn vectơ dày đặc thông qua mô hình nhúng và được lưu trữ trong cơ sở dữ liệu vectơ.
Truy xuất: Tại thời điểm truy vấn, đầu vào của người dùng được mã hóa bằng cách sử dụng cùng một mô hình nhúng và được so sánh với các vectơ được lập chỉ mục bằng cách sử dụng thước đo độ tương tự, điển hình là độ tương tự cosine. Các phần giống nhau nhất trong top-k được trả về.
Tạo: Các khối được truy xuất sẽ được đưa vào cửa sổ ngữ cảnh của mô hình làm vật liệu nối đất. LLM tạo ra phản hồi dựa trên cả truy vấn và nội dung được truy xuất.
Thỏa thuận ngầm trong kiến trúc này là nội dung được truy xuất phải chính xác, cập nhật và thực sự phù hợp với truy vấn. Khi hợp đồng đó được giữ, hệ thống RAG hoạt động rất ấn tượng. Khi không, kiến trúc sẽ tạo ra một chế độ lỗi cụ thể và nguy hiểm: mô hình tạo ra kết quả đầu ra mạch lạc, tự tin dựa trên bối cảnh không chính xác hoặc không liên quan, không có cơ chế báo hiệu rằng đã xảy ra sự cố.
Thất bại trong việc truy xuất thúc đẩy ảo giác LLM như thế nào: Bằng chứng từ nghiên cứu
Nghiên cứu luận án của tôi điều tra việc phát hiện và giảm thiểu ảo giác trong đường ống LLM đa tác nhân. Một thành phần của công việc đó liên quan đến việc xây dựng phân loại các phương thức hư hỏng xuất hiện trên các quỹ đạo tác nhân và mô tả đặc điểm các điều kiện mà mỗi loại hư hỏng xảy ra. Các lỗi liên quan đến truy xuất luôn là một loại lỗi chiếm ưu thế, cả về tần suất và tác động tiếp theo đến chất lượng đầu ra.
Qua các đánh giá thử nghiệm của tôi về HaluEval, TruthfulQA và FaithDial, được thực hiện như một phần của nghiên cứu luận án của tôi, tôi nhận thấy rằng các lỗi ở lớp truy xuất luôn gây ra một tỷ lệ đáng kể các ảo giác, ngay cả trong các đường ống có các giai đoạn tạo được cấu hình tốt. Phát hiện này phù hợp với tài liệu rộng hơn: Các đánh giá điểm chuẩn HELM của Stanford và phân tích của Đại học McGill về kho dữ liệu FaithDial đều chứng minh rằng tính trung thực đối với bối cảnh được truy xuất, chứ không phải quy mô mô hình, là yếu tố dự báo chính về độ chính xác thực tế trong các nhiệm vụ tạo ra dựa trên kiến thức.
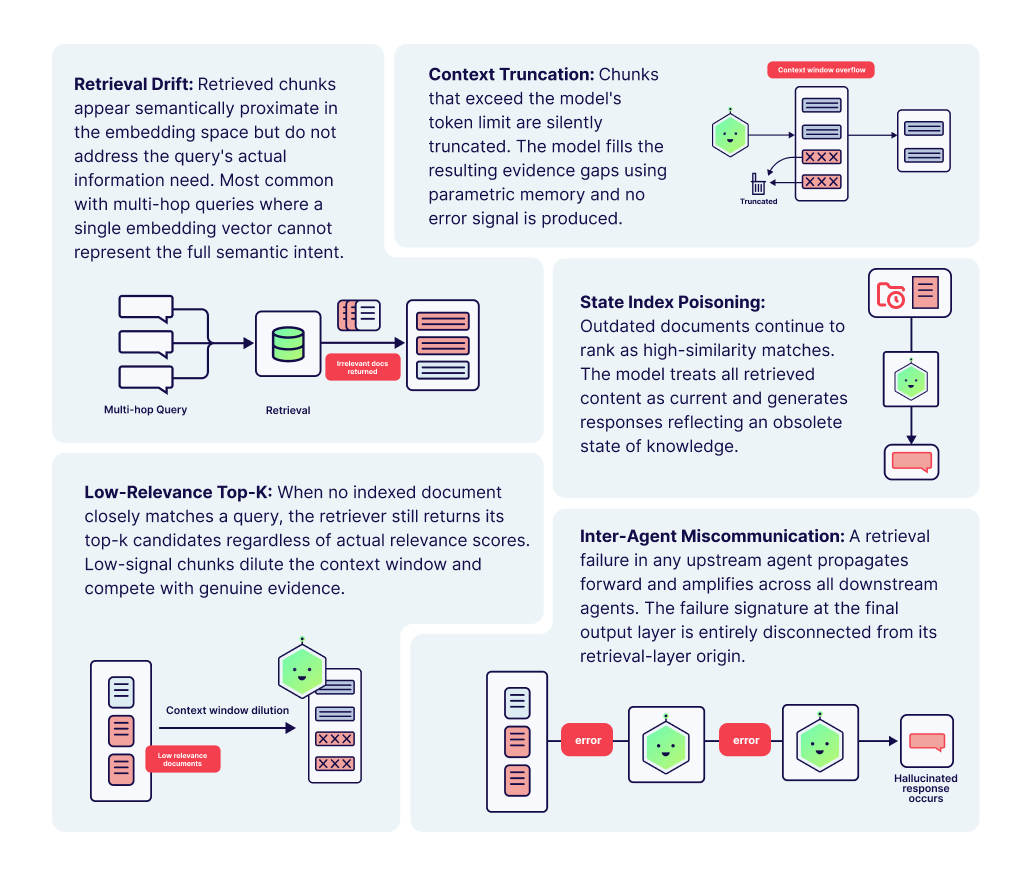
Năm chế độ lỗi truy xuất xuất hiện nhất quán nhất trong công việc thử nghiệm của chúng tôi:
Độ lệch truy xuất: Các đoạn được truy xuất gần giống về mặt ngữ nghĩa với truy vấn trong không gian nhúng nhưng không đủ ngữ cảnh để trả lời truy vấn đó. Phổ biến với các truy vấn nhiều bước nhảy, trong đó một lần nhúng đơn lẻ không thể thể hiện đầy đủ thông tin cần thiết.
Cắt ngắn bối cảnh: Khi các đoạn được truy xuất quá lớn và tràn ra cửa sổ ngữ cảnh của mô hình, việc cắt bớt thông tin sẽ tự động xóa thông tin. Mô hình bù đắp bằng cách vẽ trên bộ nhớ tham số.
Ngộ độc chỉ mục cũ: Các tài liệu đã lỗi thời tiếp tục xuất hiện dưới dạng kết quả phù hợp với top-k. Mô hình không có cơ chế để phân biệt nội dung hợp lệ tạm thời với nội dung được truy xuất không hợp lệ.
Truy xuất Top-K có mức độ liên quan thấp: Khi không có tài liệu nào khớp chặt với truy vấn, trình truy xuất vẫn trả về kết quả top-k bất kể mức độ liên quan. Các đoạn tín hiệu thấp này làm loãng cửa sổ ngữ cảnh và mô hình sẽ kết hợp nhiễu vào quá trình tạo.
Thông tin sai lệch giữa các tác nhân: Trong quy trình nhiều tác nhân, lỗi truy xuất trong một tác nhân ngược dòng lan truyền và khuếch đại trên tất cả các tác nhân xuôi dòng, tạo ra sự suy giảm tổng hợp mà vẫn không thể nhìn thấy được ở lớp đầu ra.
Điều khiến những thất bại này có hậu quả đặc biệt là tính vô hình của chúng. Không giống như một mô hình chỉ đơn giản nói rằng nó không biết, một mô hình được tạo từ bối cảnh được truy xuất kém sẽ tạo ra kết quả đầu ra có định dạng tốt và tự tin. Việc phát hiện yêu cầu so sánh thực tế cơ bản hoặc lớp đánh giá chuyên dụng, cả hai lớp này đều không tồn tại theo mặc định trong hầu hết các hệ thống được triển khai.
Tại sao việc mở rộng mô hình không giải quyết được vấn đề truy xuất
Một phản ứng phổ biến và dễ hiểu đối với hiệu suất RAG kém là gán nó cho khả năng của mô hình và giải quyết nó bằng cách mở rộng quy mô: mô hình lớn hơn, tinh chỉnh tốt hơn hoặc nền tảng nâng cao hơn. Trực giác này là hợp lý nếu xét riêng lẻ nhưng sẽ chẩn đoán sai vấn đề khi chất lượng truy xuất là nguyên nhân cơ bản.
Hãy xem xét sự tương tự của một nhà phân tích có tay nghề cao đưa ra một báo cáo sai lệch. Chuyên môn của nhà phân tích không bảo vệ được chất lượng của nguồn nguyên liệu của họ; nó chỉ đơn giản làm cho họ hiệu quả hơn trong việc xây dựng những lập luận thuyết phục từ bất cứ điều gì họ được đưa ra. Một LLM có khả năng cao hơn, được truy xuất chất lượng thấp

Nguồn tin: Weaviate Blog. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.