Liquid AI vừa ra mắt LFM2.5-8B-A1B. Đây là một mô hình Mixture-of-Experts (MoE) chạy trên thiết bị, được xây dựng để gọi công cụ. Mô hình này có tổng cộng 8,3 tỷ tham số nhưng chỉ kích hoạt 1,5 tỷ tham số cho mỗi token. Mức độ thưa thớt này cho phép mô hình chạy trên phần cứng tiêu dùng.
Phiên bản này được phát hành sau LFM2-8B-A1B, mà nhóm Liquid AI đã công bố trước đó. LFM2.5 là một dòng mô hình lai mới dành cho việc triển khai trên thiết bị. Phiên bản này bổ sung cửa sổ ngữ cảnh 128K, khả năng suy luận và quá trình huấn luyện được mở rộng.
LFM2.5-8B-A1B là gì?
Mô hình sử dụng thiết kế MoE thưa thớt. Nó kích hoạt 1,5 tỷ trong tổng số 8,3 tỷ tham số cho mỗi lần chuyển tiếp. Điều này giúp mỗi gen
Liquid AI vừa ra mắt LFM2.5-8B-A1B, một mô hình Mixture-of-Experts (MoE) trên thiết bị, được xây dựng để gọi công cụ. Mô hình này có tổng cộng 8,3 tỷ tham số nhưng chỉ kích hoạt 1,5 tỷ tham số cho mỗi token. Sự thưa thớt này cho phép mô hình chạy trên phần cứng tiêu dùng.
Phiên bản này tiếp nối LFM2-8B-A1B, được nhóm Liquid AI công bố trước đó. LFM2.5 là một dòng mô hình lai mới dành cho việc triển khai trên thiết bị. Phiên bản này bổ sung cửa sổ ngữ cảnh 128K, khả năng suy luận và quá trình huấn luyện được mở rộng.
LFM2.5-8B-A1B là gì?
Mô hình sử dụng thiết kế MoE thưa thớt. Nó kích hoạt 1,5 tỷ trong tổng số 8,3 tỷ tham số cho mỗi lần chuyển tiếp. Điều này giúp việc tính toán mỗi token được tạo ra trở nên tiết kiệm.
Kiến trúc có 24 lớp. Mười tám lớp là khối tích chập LIV hai cổng; sáu lớp là GQA. Nó kết hợp MoE, GQA và các khối tích chập ngắn có cổng. Độ dài ngữ cảnh là 131.072 token. Mô hình hỗ trợ chín ngôn ngữ, bao gồm tiếng Ả Rập, tiếng Trung và tiếng Nhật.
Nhóm Liquid AI khuyến nghị sử dụng nhiệt độ 0,2, top_k là 80 và repetition_penalty là 1,05.
Không giống như phiên bản tiền nhiệm, LFM2.5-8B-A1B là một mô hình chỉ suy luận. Nó tạo ra một chuỗi suy nghĩ rõ ràng trước khi đưa ra câu trả lời cuối cùng. Nhóm Liquid AI đã chọn cách này vì các mô hình MoE chạy trong các cài đặt bị giới hạn về tính toán. Số lượng tham số hoạt động nhỏ hơn làm cho mỗi token suy luận trở nên không tốn kém.
Những thay đổi so với LFM2-8B-A1B
Liquid đã mở rộng cửa sổ ngữ cảnh từ 32.768 lên 128.000 token. Quá trình huấn luyện trước đã được mở rộng từ 12T lên 38T token. Từ vựng tăng gấp đôi từ 65.536 lên 128.000 token.
Từ vựng lớn hơn giúp mã hóa các tập lệnh không phải tiếng Latinh hiệu quả hơn. Nhóm Liquid AI báo cáo mức tăng nén mạnh nhất ở tiếng Hindi, tiếng Thái, tiếng Việt, tiếng Indonesia và tiếng Ả Rập. Phần còn lại của kiến trúc vẫn giữ nguyên như LFM2-8B-A1B.
Cách Liquid AI huấn luyện mô hình
Nhóm Liquid AI đã mở rộng bộ mã hóa tại chỗ thay vì huấn luyện lại từ đầu. Họ tiếp tục huấn luyện hợp nhất BPE từ các hợp nhất gốc trên một tập dữ liệu đa ngôn ngữ. Các hàng nhúng mới được khởi tạo dưới dạng giá trị trung bình của các phân tách phụ token của chúng. Sau đó, một quá trình thích ứng hai giai đoạn ngắn sẽ khôi phục chất lượng.
Việc mở rộng ngữ cảnh diễn ra trong hai giai đoạn. Giai đoạn giữa huấn luyện 2T token đạt 32K, tập trung vào suy luận, toán học và sử dụng công cụ. Việc tăng cơ sở RoPE θ, cộng với giai đoạn 400B token, đạt 128K.
Hai giai đoạn học tăng cường nhắm mục tiêu vào các chế độ lỗi đã biết. Một giai đoạn tối ưu hóa ưu tiên làm giảm "vòng lặp chết" trong các dấu vết suy luận dài. Nó phân phối lại khối xác suất về các lựa chọn thay thế hợp lý. Một phần thưởng định hình RL riêng biệt không khuyến khích các từ khởi động gây ra vòng lặp như "Wait…". Một giai đoạn RL khác sử dụng phần thưởng dựa trên avg@k để cắt giảm ảo giác. Mục tiêu là kiêng trả lời các truy vấn vượt quá kiến thức đáng tin cậy.
https://www.liquid.ai/blog/lfm2-5-8b-a1b
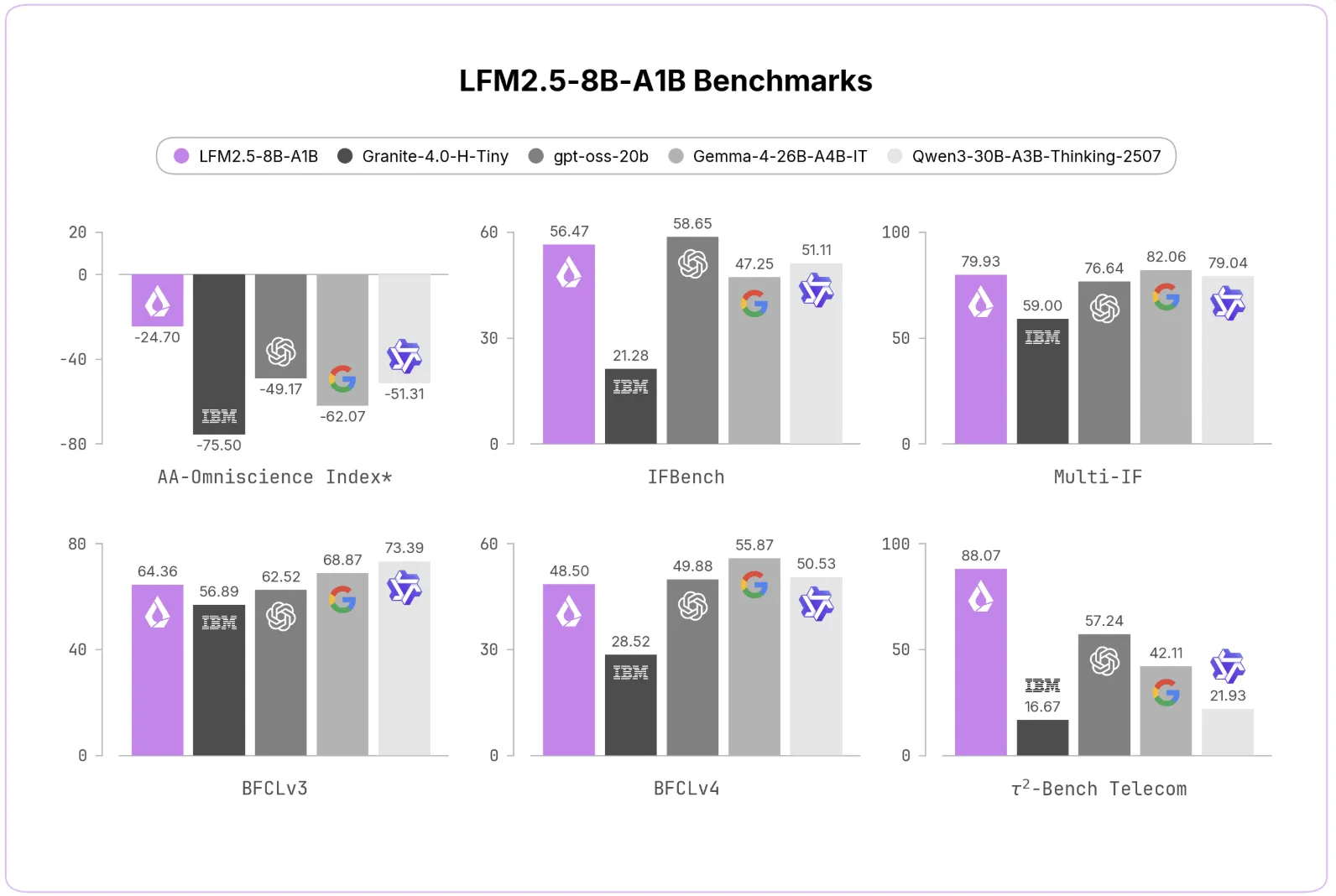
Trường hợp điểm chuẩn
LFM2.5-8B-A1B cải thiện so với phiên bản tiền nhiệm trên mọi phương diện. Tỷ lệ không ảo giác AA-Omniscience tăng từ 7,46 lên 63,47. IFEval tăng từ 79,44 lên 91,84. MATH500 tăng từ 74,80 lên 88,76. Tau² Telecom tăng từ 13,60 lên 88,07.
Nhóm Liquid AI đã so sánh mô hình với các lựa chọn thay thế dày đặc và MoE. Về việc tuân thủ hướng dẫn, nó phù hợp với Gemma-4-26B-A4B-IT trên IFEval. Nó làm được điều đó với một phần nhỏ số lượng tham số hoạt động. Trên Tau² Telecom, nó đạt 88,07, vượt xa các mô hình lớn hơn nhiều.
Phần thưởng avg@k giúp giảm đáng kể tỷ lệ ảo giác. Độ chính xác vẫn hợp lý đối với kích thước của mô hình. Trên các điểm chuẩn tác nhân, nó vẫn cạnh tranh với các mô hình lớn hơn.
Bảng so sánh LFM2-8B-A1B và LFM2.5-8B-A1B
| Tiêu chí | LFM2-8B-A1B | LFM2.5-8B-A1B | Thay đổi |
|---|---|---|---|
| Tỷ lệ không ảo giác AA-Omniscience | 7,46 | 63,47 | +56,01 |
| IFEval | 79,44 | 91,84 | +12,40 |
| MATH500 | 74,80 | 88,76 | +13,96 |
| Tau² Telecom | 13,60 | 88,07 | +74,47 |
**Vận hành: CPU, GPU và Công cụ**
Mô hình được hỗ trợ ngay lập tức trên toàn bộ hệ sinh thái suy luận. Các framework bao gồm llama.cpp, MLX, vLLM và SGLang. ONNX và nền tảng biên LEAP của Liquid cũng được hỗ trợ.
Trên CPU, mô hình giải mã 253 token/giây trên M5 Max. Tốc độ đạt 146 token/giây trên Ryzen AI Max+ 395. Mô hình duy trì mức sử dụng bộ nhớ dưới 6 GB. Trên điện thoại, tốc độ khoảng 30 token/giây.
Trên một GPU NVIDIA H100 SXM5, thông lượng đầu ra đạt 18.500 token mỗi giây. Con số này tương đương hơn 1,6 tỷ token mỗi ngày ở mức đồng thời cao.
Đối với việc sử dụng công cụ, LFM2.5 mặc định viết các lệnh gọi hàm theo phong cách Python. Chúng xuất hiện giữa các token đặc biệt <|tool_call_start|> và <|tool_call_end|>. Người dùng có thể ghi đè định dạng này sang JSON trong lời nhắc hệ thống.
**Điểm mạnh và những điều cần lưu ý**
**Điểm mạnh:**
* Chỉ kích hoạt 1,5 tỷ tham số, giúp suy luận tiết kiệm chi phí trên phần cứng biên.
* Điểm số cạnh tranh về khả năng tuân thủ hướng dẫn và tác nhân trong phân khúc kích thước của nó.
* Cửa sổ ngữ cảnh 128K và hỗ trợ chín ngôn ngữ.
* Mã nguồn mở theo giấy phép LFM1.0, với các điểm kiểm tra cơ sở và đã qua huấn luyện.
**Những điều cần lưu ý:**
* Khả năng kiến thức hạn chế do số lượng tham số hoạt động nhỏ.
* Không phù hợp cho lập trình chuyên sâu hoặc QA (hỏi đáp) chuyên sâu về kiến thức mà không có truy xuất.
* Đầu ra chỉ suy luận bổ sung các token chuỗi suy nghĩ vào mỗi lượt.
* Chỉ văn bản; biến thể này không có đầu vào hình ảnh hoặc âm thanh.
**Giải thích trực quan của Marktechpost**
**Hướng dẫn mô hình trên thiết bị**
**LFM2.5-8B-A1B**
Mô hình Mixture-of-Experts (MoE) trên thiết bị của Liquid AI, được xây dựng để gọi công cụ và tuân thủ hướng dẫn phức tạp trên phần cứng tiêu dùng.
* Tổng số tham số: 8,3 tỷ
* Tham số hoạt động: 1,5 tỷ
* Ngữ cảnh: 128K
* Chỉ suy luận
* Mã nguồn mở
Phát hành ngày 28/5/2026 · Liquid AI · Giấy phép LFM1.0
**Nó là gì**
Một MoE thưa thớt kích hoạt 1,5 tỷ trong số 8,3 tỷ tham số cho mỗi token.
* 24 lớp — 18 khối tích chập LIV cổng đôi cộng với 6 lớp GQA.
* Kết hợp MoE, GQA và các khối tích chập ngắn có cổng.
* Độ dài ngữ cảnh 131.072 token; bao gồm 9 ngôn ngữ.
* Chỉ suy luận: tạo ra một chuỗi suy nghĩ rõ ràng trước khi trả lời.
* Các tham số khuyến nghị: nhiệt độ 0,2, top_k 80, repetition_penalty 1,05.
**Những thay đổi so với LFM2-8B-A1B**
Ngữ cảnh lớn hơn, huấn luyện nhiều hơn, từ vựng rộng hơn.
* **Cửa sổ ngữ cảnh:** 32.768 → 128.000. Xử lý các tài liệu dài hơn và suy luận lâu hơn.
* **Token tiền huấn luyện:** 12T → 38T. Tiền huấn luyện mở rộng cộng với RL quy mô lớn.
* **Kích thước từ vựng:** 65.536 → 1.
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.