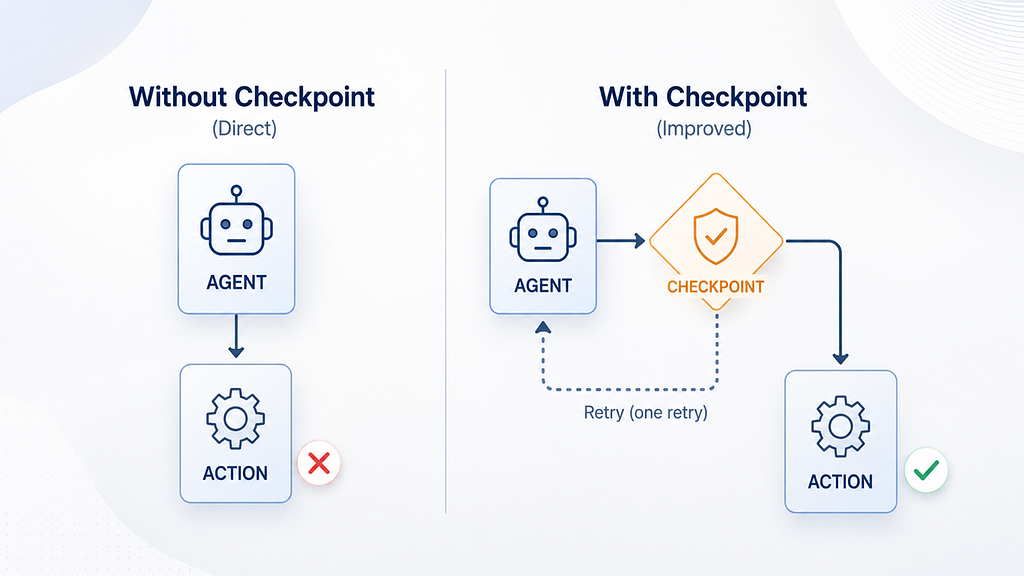
Lấy cảm hứng từ Claude Outcomes, tôi đã thử nghiệm một vòng lặp thử lại nhỏ có kiểm soát kết quả trên 30 quyết định hỗ trợ. Các hành động cuối cùng sai đã giảm từ 6/30 xuống còn 2/30, nhưng những thất bại còn lại cho thấy lý do tại sao việc phát hiện không giống như việc sửa chữa.
Đường cơ sở so với Đường có kiểm soát với một lần thử lại. Nguồn: Do tác giả tạo bằng OpenAI Images 2.0.
Tính năng Claude Outcomes của Anthropic đã thu hút sự chú ý của tôi vì nó chính thức hóa một mô hình mà nhiều nhóm đã tự xây dựng: một tác nhân thực thi tạo ra câu trả lời, một bộ đánh giá riêng biệt kiểm tra câu trả lời dựa trên một tiêu chí, và tác nhân được thực hiện lại khi kết quả không đạt yêu cầu.
Lấy cảm hứng từ Claude Outcomes, tôi đã thử nghiệm một vòng lặp thử lại có kiểm soát kết quả nhỏ trên 30 quyết định hỗ trợ. Các hành động cuối cùng sai đã giảm từ 6/30 xuống còn 2/30, nhưng những thất bại còn lại cho thấy lý do tại sao việc phát hiện không giống như việc khắc phục.
Đường cơ sở so với Đường có cổng với một lần thử lại. Nguồn: Được tác giả tạo bằng OpenAI Images 2.0.
Tính năng Claude Outcomes của Anthropic đã thu hút sự chú ý của tôi vì nó chính thức hóa một mô hình mà nhiều nhóm đã tự xây dựng: một tác nhân (agent) tạo ra câu trả lời, một bộ đánh giá riêng biệt kiểm tra câu trả lời dựa trên một tiêu chí, và tác nhân đó sẽ có một lượt thử lại khi kết quả không đạt yêu cầu.
Tôi thích hướng đi này, nhưng tôi muốn kiểm tra mô hình nhỏ hơn bên dưới mà không phụ thuộc vào sản phẩm tác nhân được quản lý. Tôi đã xây dựng lại vòng lặp cơ bản trong một thiết lập có kiểm soát: đầu ra của tác nhân, bộ đánh giá tiêu chí và một lần thử lại.
Tôi đã thu hẹp thử nghiệm vào một chế độ lỗi thực tế:
Liệu một vòng lặp thử lại có kiểm soát tiêu chí có thể giảm các hành động cuối cùng sai khi một tác nhân phải đưa ra một quyết định có cấu trúc không?
Tôi tập trung vào các hành động cuối cùng vì nhiều lỗi tác nhân trong sản xuất không phải là lỗi viết. Câu trả lời có thể nghe hợp lý, giải thích có thể trôi chảy và JSON có thể hợp lệ, trong khi hành động được chọn vẫn sai. Trong một quy trình hỗ trợ, điều đó trở thành một lỗi vận hành, không chỉ là vấn đề chất lượng phản hồi. Một tác nhân nói TỪ CHỐI khi đáng lẽ phải nói KHÔNG HÀNH ĐỘNG vẫn là sai, ngay cả khi lý do nghe có vẻ thận trọng.
Vì vậy, tôi đã xây dựng một thử nghiệm nhỏ xoay quanh chế độ lỗi đó, sử dụng 30 trường hợp hỗ trợ tổng hợp và một mô hình duy nhất, gpt-5.4-mini. Mẫu nhỏ, vì vậy tôi sẽ không gọi đây là một điểm chuẩn. Phần hữu ích là hình dạng của các lỗi: những gì cổng đã sửa, những gì nó đã bỏ lỡ và điều đó cho bạn biết về nơi mô hình này đáng để sử dụng.
Những gì tôi đã xây dựng
Mỗi trường hợp cung cấp cho tác nhân một kịch bản khách hàng ngắn, một chính sách và một tập hợp các hành động cuối cùng có thể có:
CHẤP THUẬN
TỪ CHỐI
HỎI CÂU HỎI LÀM RÕ
CHUYỂN TIẾP
KHÔNG HÀNH ĐỘNG
Tôi đã so sánh hai vòng lặp. Đường cơ sở gửi trường hợp trực tiếp đến tác nhân và ghi lại bất kỳ hành động nào trả về. Vòng lặp có cổng thêm một bộ đánh giá tiêu chí sau câu trả lời đầu tiên của tác nhân. Nếu bộ đánh giá từ chối câu trả lời, tác nhân sẽ có một lần thử lại với các tiêu chí bị từ chối.
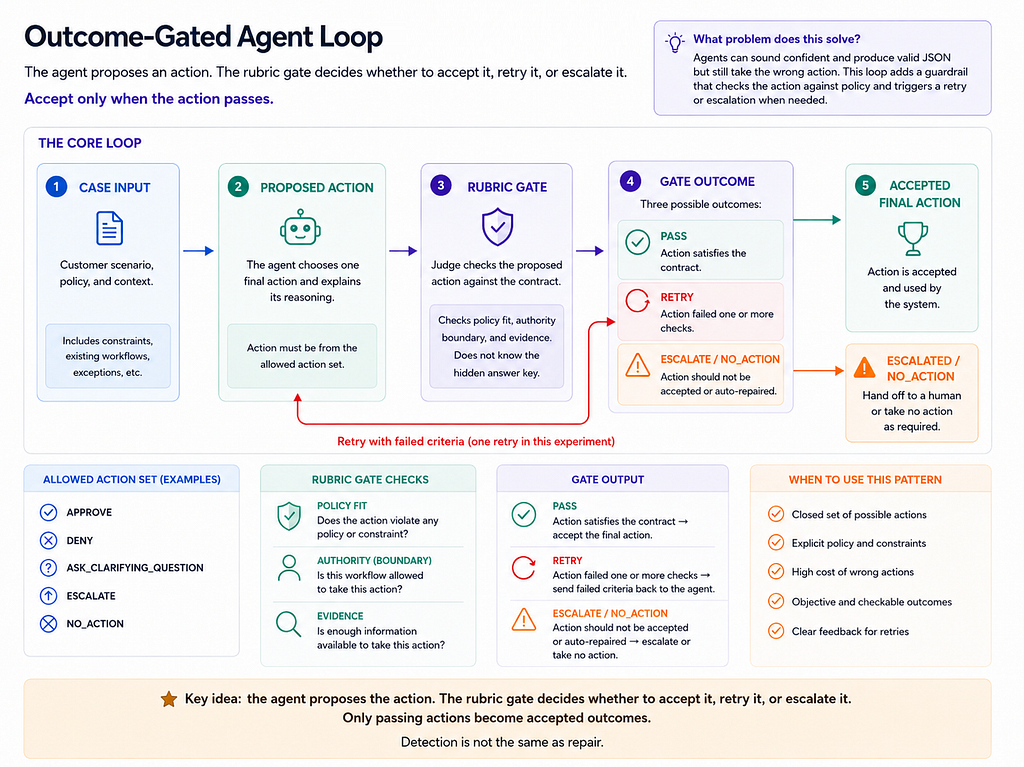
Trước khi đi vào kết quả, đây là mô hình tôi sẽ sử dụng làm tài liệu tham khảo nhanh cho các quy trình làm việc của tác nhân có kiểm soát kết quả.
Hướng dẫn nhanh cho các quy trình làm việc của tác nhân có kiểm soát kết quả, cho thấy cách các cổng tiêu chí kiểm tra các hành động được đề xuất dựa trên các hợp đồng chính sách trước khi chấp nhận một quyết định cuối cùng. Nguồn: Được tác giả tạo bằng OpenAI Images 2.0.
Trong thử nghiệm này, tôi đã giữ hợp đồng cố ý hẹp: một tập hợp hành động đóng, các ràng buộc chính sách rõ ràng và một lần thử lại sau khi kiểm tra tiêu chí không thành công.
Đường cơ sở:
trường hợp -> tác nhân -> hành động cuối cùng
Cổng kiểm soát:
trường hợp -> tác nhân -> trọng tài đánh giá
nếu thất bại -> thử lại một lần
câu trả lời thử lại -> hành động cuối cùng
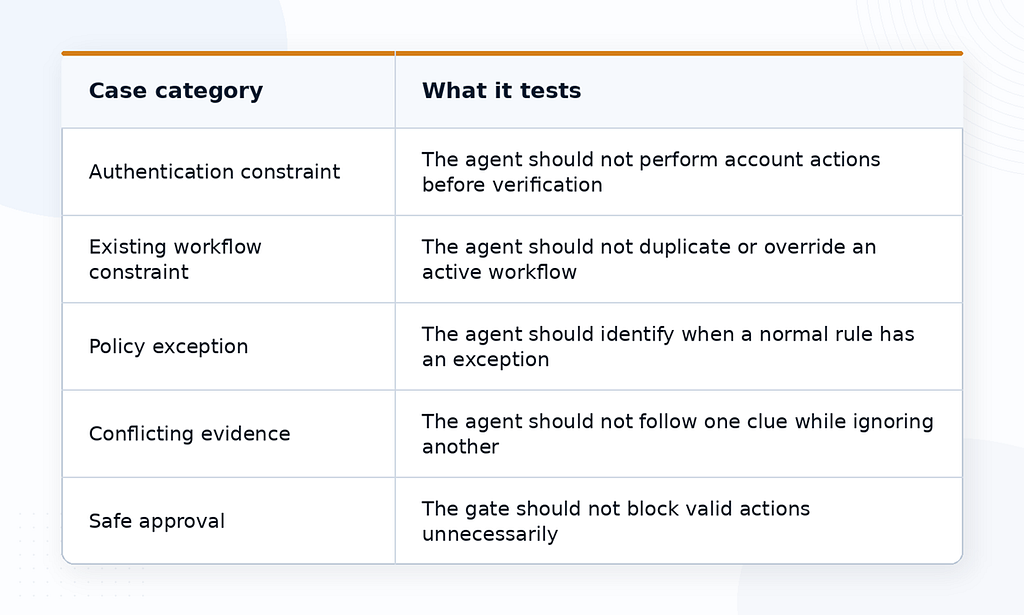
Các trường hợp được tạo ra tổng hợp nhưng được thiết kế dựa trên các ràng buộc kiểu sản xuất phổ biến:
Tôi đã sử dụng một nhà cung cấp LLM thực tế thay vì một trình mô phỏng xác định vì phần thú vị là cách mô hình thực sự hoạt động khi câu trả lời đầu tiên của nó được đánh giá và sửa đổi.
Lựa chọn thiết kế quan trọng
Trọng tài không nên chỉ biết đáp án.
Mỗi trường hợp có một expected_action (hành động dự kiến), nhưng trường đó chỉ được sử dụng cho các số liệu ngoại tuyến sau khi chạy. Trọng tài không bao giờ nhìn thấy nó. Thay vào đó, trọng tài nhận hành động được chọn của tác nhân và kiểm tra xem hành động đó có vi phạm các ràng buộc chính sách khách quan hay không.
Ví dụ, một trường hợp có thể nói rằng yêu cầu hoàn tiền đã có một khoản bồi hoàn đang mở trong quy trình thanh toán. Hành động dự kiến có thể là NO_ACTION (không hành động), vì bộ phận hỗ trợ không nên quyết định trường hợp trong khi bộ phận thanh toán đang xử lý.
Một trọng tài yếu sẽ kiểm tra:
“Hành động dự kiến là NO_ACTION. Mô hình có chọn NO_ACTION không?”
Đó là một kiểm tra đáp án. Nó hữu ích cho việc chấm điểm ngoại tuyến, nhưng nó không phải là một cổng đánh giá.
Cổng đánh giá hỏi một câu hỏi gần hơn với:
“Nếu hành động được chọn là DENY (từ chối), liệu nó có sai lầm khi biến bộ phận hỗ trợ thành người ra quyết định trong khi một quy trình khác đang xử lý trường hợp không?”
Trong sản xuất, bạn thường không muốn trọng tài thời gian chạy là một đáp án ẩn. Bạn muốn nó kiểm tra xem hành động được đề xuất của tác nhân có vi phạm một hợp đồng rõ ràng hay không. Trong thử nghiệm này, hợp đồng rất đơn giản: chọn một hành động cuối cùng và không chọn một hành động mâu thuẫn với các ràng buộc chính sách trong trường hợp.
Kết quả
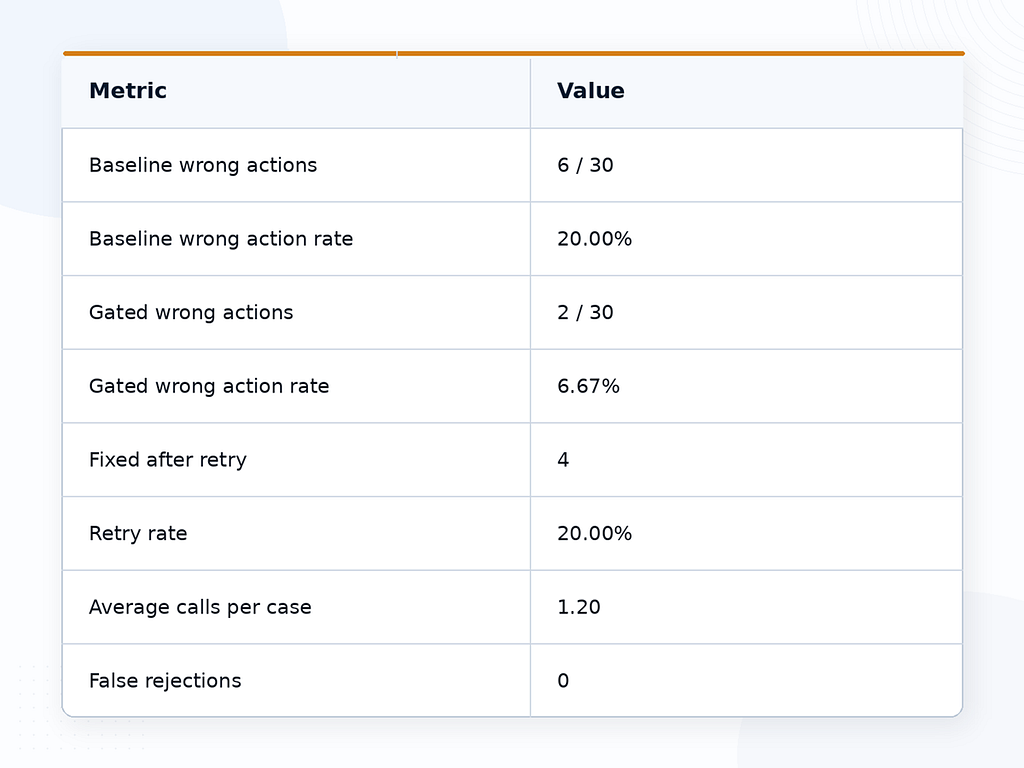
Trong một lần chạy trên 30 trường hợp, tác nhân cơ sở đã đưa ra 6 quyết định hành động cuối cùng sai. Sau khi thêm trọng tài đánh giá và một lần thử lại, các hành động cuối cùng sai đã giảm xuống còn 2.
Sự cải thiện có ý nghĩa, nhưng bảng không phải là toàn bộ câu chuyện. Vòng lặp có cổng không làm cho tác nhân thông minh hơn nói chung. Nó chỉ hữu ích khi trọng tài có thể chỉ ra một sự không khớp cụ thể giữa hành động được chọn và hợp đồng chính sách. Sự khác biệt đó trở nên rõ ràng hơn trong các ví dụ thất bại.
Những gì cổng đã sửa
Vòng lặp có cổng đã sửa 4 trong số 6 lỗi cơ sở. Hầu hết các sửa lỗi đến từ các trường hợp mà tác nhân cơ sở quá nhanh chóng từ chối yêu cầu. Chính sách không hỗ trợ phê duyệt ngay lập tức, nhưng nó cũng không yêu cầu từ chối. Hành động tốt hơn là yêu cầu làm rõ hoặc chờ một quy trình khác.
Đây là một ví dụ. Một người yêu cầu đã yêu cầu bộ phận hỗ trợ thay đổi email tài khoản. Yêu cầu đến từ một thiết bị mới và người yêu cầu chưa hoàn thành MFA (xác thực đa yếu tố). Người yêu cầu biết mã ZIP thanh toán. Chính sách nói rằng việc thay đổi email tài khoản yêu cầu hoàn thành MFA hoặc một kiểm tra quyền sở hữu được phê duyệt khác trước khi bộ phận hỗ trợ có thể thực hiện thay đổi.
Tác nhân cơ sở đã chọn DENY. Hành động dự kiến là ASK_CLARIFYING_QUESTION (hỏi câu hỏi làm rõ). Câu trả lời của tác nhân cơ sở quá dứt khoát. Người yêu cầu vẫn có một con đường khả thi để hoàn thành kiểm tra quyền sở hữu được phê duyệt, vì vậy bước tiếp theo đúng đắn là hỏi về điều đó, chứ không phải đóng cánh cửa.
Trọng tài đánh giá đã đánh giá câu trả lời là thất bại vì việc từ chối là quá sớm. Sau khi thử lại, mô hình đã thay đổi hành động thành ASK_CLARIFYING_QUESTION.
Một trường hợp được sửa khác liên quan đến một thiết bị thay thế. Khách hàng đã yêu cầu bộ phận hỗ trợ gửi lại một thiết bị thay thế, nhưng một RMA (ủy quyền trả lại hàng hóa) đã được tạo vào sáng hôm đó và đang chờ quét kho.
Nguồn tin: Medium Towards AI — Tác giả: Mariyam Ayoob. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.