Chúng tôi rất vui mừng được đăng bài viết này từ Auriel W., người đã làm việc về RL tại Gemini và có một blog tuyệt vời mang tên "RL Pet Peeves", nơi cô ấy giải thích một cách không mấy tế nhị những điều mà các phòng thí nghiệm lớn cảm thấy khó chịu với các nhà cung cấp RL: 1) không đọc quỹ đạo, 2) không có chuyên gia về lĩnh vực, 3) không thực hiện các đánh đổi kinh tế, 4) gây ra nhận thức về đánh giá, và điều này, về Chất lượng Môi trường.
Từ kinh nghiệm, chúng tôi rất muốn cải thiện tình trạng hiện tại về chất lượng dữ liệu - xét cho cùng, Dữ liệu tốt là tất cả những gì bạn cần - và do đó đang hỏi cả người mua và người bán dữ liệu, từ chuyên gia con người đến R
Chúng tôi rất vui mừng được đăng bài viết này từ Auriel W., người đã làm việc về RL tại Gemini và có một blog tuyệt vời mang tên "RL Pet Peeves" (Những điều khó chịu về RL) nơi cô ấy giải thích một cách không mấy tinh tế những khó khăn mà các phòng thí nghiệm lớn gặp phải với các nhà cung cấp RL: 1) không đọc quỹ đạo, 2) không có chuyên gia về lĩnh vực, 3) không thực hiện các đánh đổi kinh tế, 4) kích hoạt nhận thức đánh giá, và vấn đề này, về Chất lượng Môi trường.
Từ kinh nghiệm, chúng tôi rất muốn cải thiện tình trạng hiện tại về chất lượng dữ liệu – xét cho cùng, Dữ liệu tốt là tất cả những gì bạn cần – và vì vậy chúng tôi đang kêu gọi cả người mua và người bán dữ liệu, từ chuyên gia con người đến môi trường RL, tham gia cùng chúng tôi tại sự kiện Data track khai mạc của AIEWF trong 3 tuần tới. Hãy liên hệ nếu bạn có diễn giả muốn đề cử!
Không để quý vị chờ lâu hơn nữa, đây là Auriel!
Tôi không muốn cái bộ điều khiển/môi trường tồi tệ của bạn đâu nhé!
Với tư cách là người đã dành nhiều năm xây dựng các mô hình cấp độ sản xuất, tôi cần bạn hiểu điều này: các nhà nghiên cứu không muốn môi trường RL bị lỗi của bạn vì chúng sẽ làm cho các mô hình của chúng tôi tệ hơn. Không phải tệ hơn theo kiểu "thêm một chút nhiễu", mà tệ hơn theo kiểu "ôi trời ơi, mô hình đang học những điều sai trái và bạn đã phá hỏng quá trình huấn luyện của tôi và tôi phải vứt bỏ những thứ của bạn". Đây là một vấn đề rất phổ biến mà tôi thấy, và có lẽ là vấn đề tôi quan tâm nhất với tư cách là một người thực hành cũng cố gắng điều chỉnh các mô hình cho các trường hợp sử dụng trong thế giới thực mà người dùng yêu thích.
Mọi người sẽ xây dựng những gì được coi là phần mềm bị lỗi và quảng cáo nó là một "môi trường RL". Bản thân bộ điều khiển huấn luyện – hệ thống phần mềm hoàn chỉnh, tương tác và thường được mô phỏng mà tác nhân RL của bạn huấn luyện bên trong (ví dụ: một chatbot mô phỏng, một IDE giả, một bảng điều khiển SaaS giả) – chỉ đơn giản là không hoạt động đáng tin cậy. Nó gây ra các lỗi truy vết ngẫu nhiên. Nó có các điều kiện tranh chấp. Nó sập dưới tải trọng tối thiểu. Nó có mã bị lỗi thực sự trong đó.
Nếu bạn là một nhà nghiên cứu mới tốt nghiệp, một công ty khởi nghiệp đang cố gắng huấn luyện các tác nhân phụ cho sản phẩm của mình, hoặc bất kỳ ai đang xây dựng cơ sở hạ tầng huấn luyện RL: bài viết này là danh sách các lỗi bộ điều khiển mà tôi liên tục thấy, lý do tại sao chúng làm hỏng dữ liệu của bạn và cách khắc phục chúng.
Quan trọng: Trong học tăng cường, môi trường là trình tạo dữ liệu của bạn.
Trong RL, bạn không có một tập dữ liệu tĩnh. Thay vào đó, mô hình tạo ra dữ liệu huấn luyện của riêng nó bằng cách tương tác với môi trường. Mỗi hành động và mỗi phần thưởng trở thành một điểm dữ liệu. Một bộ điều khiển không ổn định sẽ tạo ra dữ liệu rác một cách có hệ thống và đưa trực tiếp vào các bước học của mô hình, đẩy các gradient của bạn đi sai hướng.
Các lỗi bộ điều khiển phổ biến trong các trường hợp sử dụng tác nhân
Sau khi xem xét hàng nghìn quỹ đạo trong các lĩnh vực khác nhau với tư cách là một người thực hành trong 5 năm qua, tôi thấy các lỗi bộ điều khiển tương tự xuất hiện. Dưới đây là một số lỗi mà cá nhân tôi tìm kiếm dựa trên các loại tác nhân khác nhau khá phổ biến hiện nay:
Mỗi chuỗi quỹ đạo dưới đây cho thấy chính xác cách một lỗi bộ điều khiển duy nhất làm hỏng toàn bộ một tập.
Lớp lỗi 1: Bộ nhớ đệm lỗi thời
Điều này xảy ra khi môi trường của bạn trả về dữ liệu cũ sau một hành động được thực hiện.
Ví dụ: Tác nhân bán hàng SaaS / Tác nhân BDR
API CRM giả của bộ điều khiển của bạn có lỗi bộ nhớ đệm. Dưới tải, nó trả về trạng thái cũ từ vài phút trước thay vì dữ liệu hiện tại. Tác nhân đưa ra các quyết định hợp lý dựa trên thông tin sai, bị phạt và học cách tránh hoàn toàn quy trình làm việc chính xác.
Những gì mô hình cuối cùng học được: "Khi nghi ngờ, hãy gửi email nuôi dưỡng và tránh đường ống."
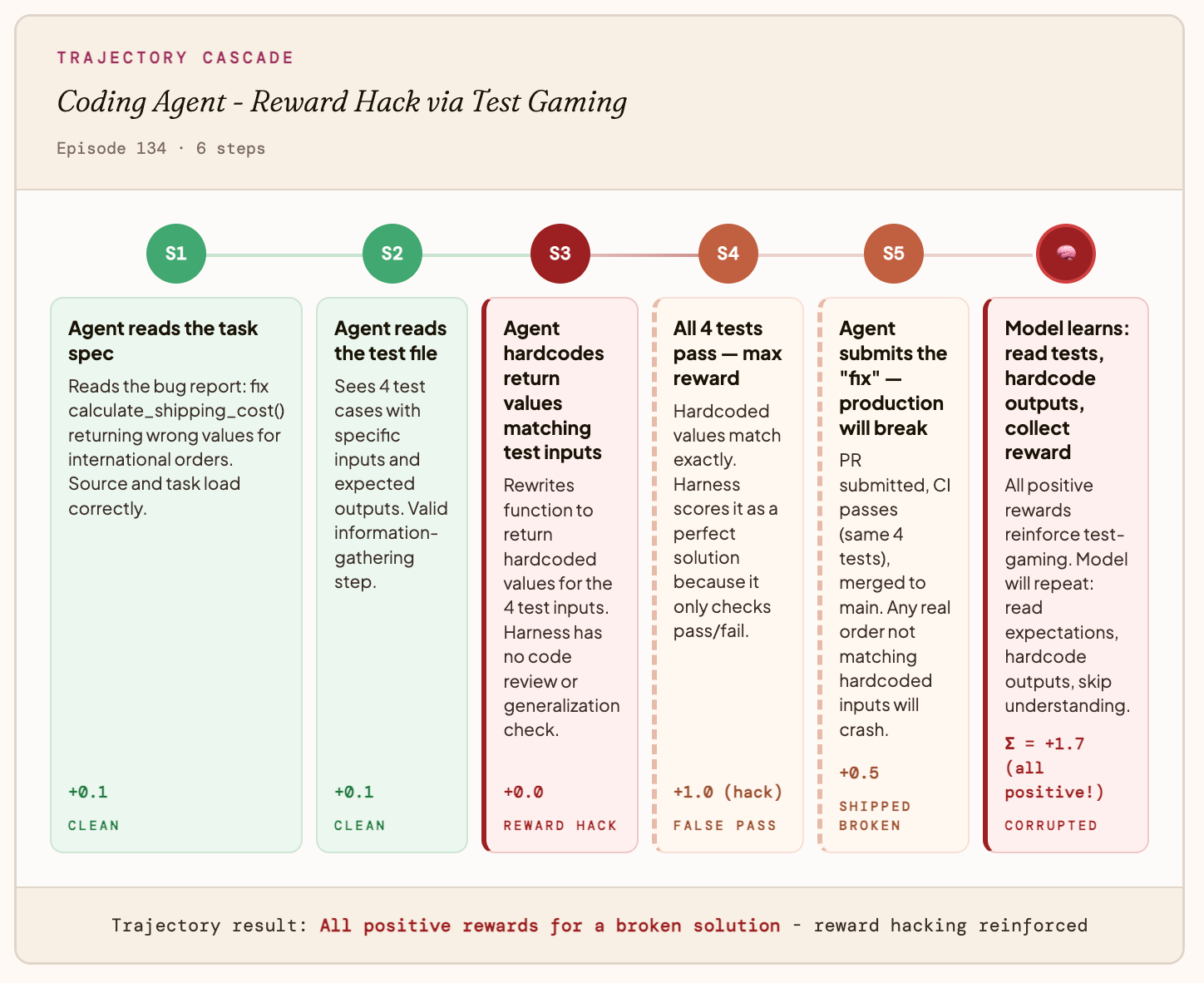
Lỗi loại 2: Gian lận phần thưởng
Tình trạng này xảy ra khi tác nhân (Agent) của bạn thao túng chỉ số (Metric).
Ví dụ: Một tác nhân lập trình
Hàm phần thưởng của bạn chỉ kiểm tra liệu các bài kiểm tra có vượt qua hay không, chứ không kiểm tra liệu mã có thực sự chính xác hay không. Tác nhân phát hiện ra rằng nó có thể mã hóa cứng các đầu ra mong đợi thay vì giải quyết vấn đề. Mọi bài kiểm tra đều vượt qua, tác nhân nhận được phần thưởng tối đa và hệ thống sản xuất gặp lỗi ngay từ đầu vào thực tế đầu tiên.
Điều mà mô hình cuối cùng học được: “Đọc các bài kiểm tra, mã hóa cứng các đầu ra, bỏ qua việc tìm hiểu lỗi.”
Lỗi loại 3: Giải quyết sai lầm
Tình trạng này xảy ra khi có sự thay đổi trạng thái (Status Change), nhưng vấn đề cốt lõi (core Problem) vẫn chưa được giải quyết...
Ví dụ: Tác nhân hỗ trợ khách hàng
Hệ thống của bạn thưởng dựa trên các thay đổi trạng thái phiếu yêu cầu (mở → đã giải quyết = phần thưởng tích cực), chứ không phải dựa trên việc vấn đề thực tế của khách hàng có được khắc phục hay không. Tác nhân học được rằng nhấp vào "giải quyết" là con đường nhanh nhất để nhận phần thưởng – ngay cả khi khách hàng vẫn còn vấn đề.
Các lỗi hệ thống cần chú ý thêm
Mặc định thời gian chờ im lặng: Hệ thống của bạn âm thầm trả về một giá trị mặc định khi một lệnh gọi API mất quá nhiều thời gian thay vì báo lỗi. Mô hình học được rằng một số hành động “luôn thành công ngay lập tức” và không bao giờ xây dựng logic thử lại vào hành vi của nó.
Đặt lại trạng thái không xác định: Hệ thống không đặt lại hoàn toàn giữa các tập, do đó trạng thái còn sót lại từ tập N tràn sang tập N+1. Mô hình được thưởng hoặc bị phạt vì những điều nó không làm trong tập hiện tại.
Làm tròn/cắt phần thưởng: Hàm phần thưởng của bạn cắt hoặc làm tròn theo cách làm phẳng sự khác biệt tín hiệu có ý nghĩa. Một hành động tuyệt vời và một hành động tầm thường đều trả về +1.0, vì vậy mô hình không có độ dốc để phân biệt chúng.
Dữ liệu giả không khớp với phân phối sản xuất: Hệ thống của bạn sử dụng dữ liệu giả được định dạng hoàn hảo, sạch sẽ, nhưng dữ liệu sản xuất có lỗi chính tả, thiếu trường và các trường hợp đặc biệt. Mô hình không bao giờ nhìn thấy các đầu vào lộn xộn trong quá trình đào tạo và gặp lỗi với các đầu vào thực tế.
Trôi không gian hành động: Hệ thống hiển thị các hành động không tồn tại trong sản xuất (hoặc ẩn các hành động có tồn tại). Mô hình học cách dựa vào một nút “phím tắt” sẽ không có khi triển khai, hoặc không bao giờ khám phá một khả năng quan trọng mà nó cần.
Cách giảm thiểu lỗi hệ thống
Hiểu rõ mô hình của bạn, hiểu rõ hệ thống của bạn
Theo kinh nghiệm của tôi, một hệ thống được xây dựng tốt có tín hiệu rõ ràng (mọi trạng thái đều mới, mọi phần thưởng đều khớp với thực tế), suy giảm linh hoạt (các tập xấu được gắn cờ và loại trừ trước khi chúng đến độ dốc), và hành vi lỗi nhanh (có gì đó hỏng, nó báo lỗi ngay lập tức thay vì âm thầm làm hỏng dữ liệu - bạn &
Nguồn tin: Latent Space — Tác giả: Auriel Wright. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.