
Hướng dẫn trực quan về các biến thể chú ý trong LLM hiện đại
Ban đầu tôi định viết về DeepSeek V4. Vì nó vẫn chưa được phát hành nên tôi đã dành thời gian để làm việc gì đó đã có trong danh sách của mình từ lâu, cụ thể là thu thập, sắp xếp và tinh chỉnh các kiến trúc LLM khác nhau mà tôi đã nghiên cứu trong vài năm qua. Vì vậy, trong hai tuần qua, tôi đã biến nỗ lực đó thành một phòng trưng bày kiến trúc LLM (với 45 mục vào thời điểm viết bài này), kết hợp tài liệu từ các bài viết trước đó với một số kiến trúc quan trọng mà tôi chưa ghi lại. Mỗi mục đi kèm với một thẻ mô hình trực quan và tôi dự định giữ lại thư viện
Ban đầu tôi định viết về DeepSeek V4. Vì nó vẫn chưa được phát hành nên tôi đã dành thời gian để làm việc gì đó đã có trong danh sách của mình từ lâu, cụ thể là thu thập, sắp xếp và tinh chỉnh các kiến trúc LLM khác nhau mà tôi đã nghiên cứu trong vài năm qua.
Vì vậy, trong hai tuần qua, tôi đã biến nỗ lực đó thành một phòng trưng bày kiến trúc LLM (với 45 mục vào thời điểm viết bài này), kết hợp tài liệu từ các bài viết trước đó với một số kiến trúc quan trọng mà tôi chưa ghi lại. Mỗi mục đều có một thẻ mô hình trực quan và tôi dự định sẽ cập nhật thư viện thường xuyên.
Bạn có thể tìm thấy phòng trưng bày tại đây: https://sebastianraschka.com/llm-architecture-gallery/
Hình 1: Tổng quan về thư viện kiến trúc LLM và các thẻ mô hình trực quan của nó.
Sau khi tôi chia sẻ phiên bản đầu tiên, một số độc giả cũng hỏi liệu có phiên bản áp phích hay không. Vì vậy, hiện đã có phiên bản poster thông qua Redbubble. Tôi đã đặt hàng kích thước Trung bình (26,9 x 23,4 in) để kiểm tra xem nó trông như thế nào khi in và kết quả là sắc nét và rõ ràng. Điều đó có nghĩa là, một số thành phần văn bản nhỏ nhất đã khá nhỏ ở kích thước đó, vì vậy tôi sẽ không đề xuất các phiên bản nhỏ hơn nếu bạn muốn mọi thứ đều có thể đọc được.
Hình 2: Phiên bản áp phích của phòng trưng bày kiến trúc với một số đối tượng ngẫu nhiên theo tỷ lệ.
Bên cạnh phòng trưng bày, tôi cũng đang nghiên cứu những phần giải thích ngắn gọn về một số khái niệm LLM cốt lõi.
Vì vậy, trong bài viết này, tôi nghĩ sẽ rất thú vị khi tóm tắt lại tất cả các biến thể đáng chú ý gần đây đã được phát triển và sử dụng trong các kiến trúc trọng lượng mở nổi bật trong những năm gần đây.
Mục tiêu của tôi là làm cho bộ sưu tập trở nên hữu ích với cả vai trò là tài liệu tham khảo và tài nguyên học tập nhẹ. Tôi hy vọng bạn thấy nó hữu ích và mang tính giáo dục!
1. Chú ý nhiều đầu (MHA)
Tính năng tự chú ý cho phép mỗi mã thông báo xem xét các mã thông báo hiển thị khác trong chuỗi, gán trọng số cho chúng và sử dụng các trọng số đó để xây dựng cách trình bày nhận biết ngữ cảnh mới của đầu vào.
Sự chú ý nhiều đầu (MHA) là phiên bản biến áp tiêu chuẩn của ý tưởng đó. Nó chạy song song một số đầu chú ý với các dự đoán đã học khác nhau, sau đó kết hợp kết quả đầu ra của chúng thành một bản trình bày phong phú hơn.
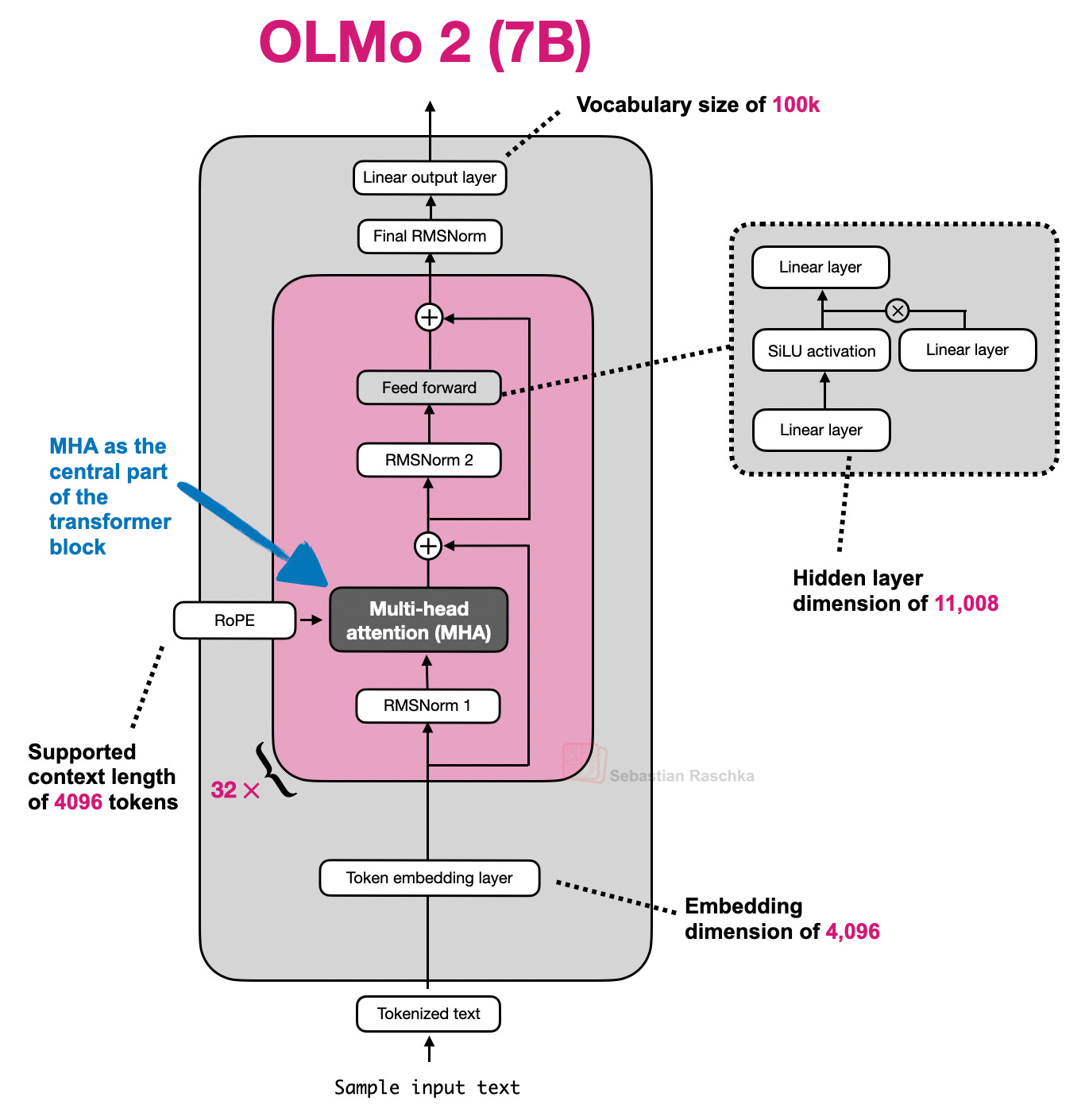
Hình 3: Olmo 2 là kiến trúc mẫu sử dụng MHA.
Các phần bên dưới bắt đầu bằng một chuyến tham quan ngắn gọn về việc giải thích sự chú ý đến bản thân để giải thích về MHA. Nó có ý nghĩa nhiều hơn như một bản tổng quan nhanh để tạo tiền đề cho các khái niệm chú ý có liên quan như chú ý truy vấn được nhóm, chú ý cửa sổ trượt, v.v. Nếu bạn quan tâm đến phạm vi bảo hiểm dài hơn, chi tiết hơn về bản thân, bạn có thể thích bài viết Hiểu và Mã hóa Tự chú ý, Chú ý nhiều đầu, Chú ý nhân quả và Chú ý chéo trong LLMs dài hơn của tôi.
KIẾN TRÚC MẪU
GPT-2, OLMo 2 7B và OLMo 3 7B
1.2 Những mẩu tin lịch sử và lý do tại sao sự chú ý được phát minh
Sự chú ý có trước máy biến áp và MHA. Nền tảng trực tiếp của nó là RNN bộ mã hóa-giải mã để dịch.
Trong các hệ thống cũ hơn đó, bộ mã hóa RNN sẽ đọc mã thông báo câu nguồn theo mã thông báo và nén nó thành một chuỗi các trạng thái ẩn hoặc trong phiên bản đơn giản nhất thành một trạng thái cuối cùng. Sau đó, bộ giải mã RNN phải tạo ra câu đích từ bản tóm tắt hạn chế đó. Điều này hiệu quả với các trường hợp ngắn và đơn giản, nhưng nó tạo ra một nút thắt rõ ràng khi thông tin liên quan cho từ đầu ra tiếp theo nằm ở một nơi khác trong câu đầu vào.
Nói tóm lại, hạn chế là trạng thái ẩn không thể lưu trữ vô số thông tin hoặc ngữ cảnh và đôi khi sẽ rất hữu ích nếu chỉ tham khảo lại chuỗi đầu vào đầy đủ.
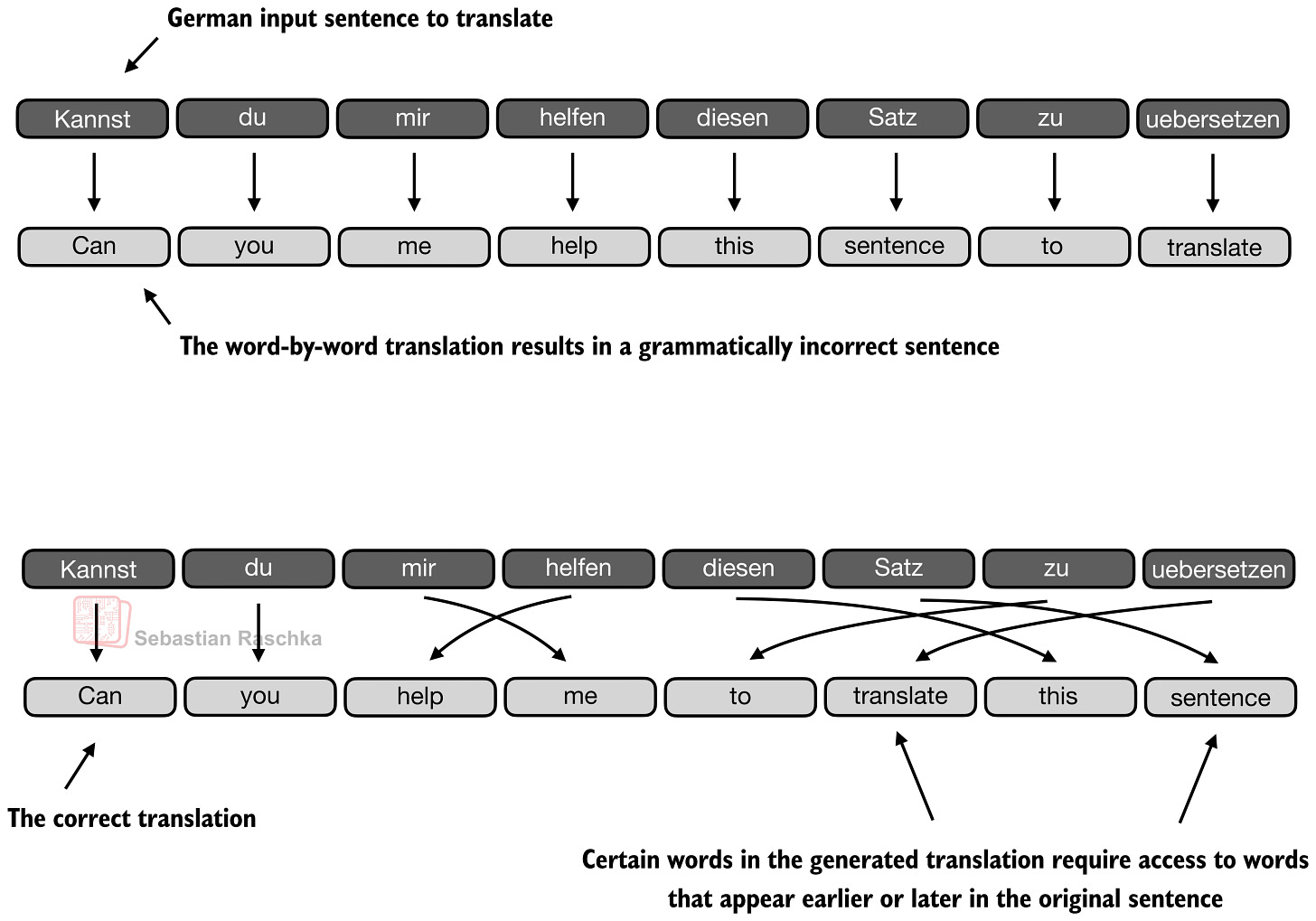
Ví dụ dịch dưới đây cho thấy một trong những hạn chế của ý tưởng này. Ví dụ: một câu có thể giữ lại nhiều lựa chọn từ hợp lý cục bộ nhưng vẫn không thể dịch được khi mô hình xử lý vấn đề quá giống với việc ánh xạ từng từ. (Bảng trên cùng hiển thị một ví dụ phóng đại trong đó chúng tôi dịch từng câu một; rõ ràng là ngữ pháp trong câu kết quả là sai.) Trên thực tế, từ tiếp theo đúng phụ thuộc vào cấu trúc cấp độ câu và các từ nguồn trước đó quan trọng ở bước đó. Tất nhiên, điều này vẫn có thể được dịch tốt bằng RNN, nhưng nó sẽ gặp khó khăn với các chuỗi dài hơn hoặc các nhiệm vụ truy xuất kiến thức vì trạng thái ẩn chỉ có thể lưu trữ rất nhiều thông tin như đã đề cập trước đó.
Hình 4: Bản dịch có thể thất bại ngay cả khi nhiều lựa chọn từ riêng lẻ có vẻ hợp lý vì cấu trúc cấp độ câu vẫn quan trọng (LLM nguồn gốc từ đầu).
Hình tiếp theo cho thấy sự thay đổi đó trực tiếp hơn. Khi bộ giải mã đang tạo mã thông báo đầu ra, nó không được giới hạn ở một đường dẫn bộ nhớ nén. Nó sẽ có thể liên hệ trực tiếp với các mã thông báo đầu vào phù hợp hơn.
Hình 5: Sự chú ý phá vỡ nút cổ chai RNN bằng cách cho phép vị trí đầu ra hiện tại xem lại chuỗi đầu vào đầy đủ thay vì chỉ dựa vào một trạng thái nén (LLM nguồn gốc từ đầu).
Transformers giữ ý tưởng cốt lõi đó từ RNN đã được sửa đổi chú ý nói trên nhưng loại bỏ sự lặp lại. Trong bài viết cổ điển Sự chú ý là tất cả những gì bạn cần, sự chú ý trở thành cơ chế xử lý chuỗi chính (thay vì chỉ là một phần của bộ mã hóa-giải mã RNN.)
Trong máy biến áp, cơ chế đó được gọi là tự chú ý, trong đó mỗi mã thông báo trong chuỗi tính toán trọng số trên tất cả các mã thông báo khác và sử dụng chúng để trộn thông tin từ các mã thông báo đó thành một biểu diễn mới. Sự chú ý nhiều đầu là cùng một cơ chế chạy song song nhiều lần.
1.3 Ma trận chú ý đeo mặt nạ
Đối với một chuỗi các mã thông báo T, sự chú ý cần một hàng trọng số cho mỗi mã thông báo, vì vậy về tổng thể chúng ta có được ma trận T x T.
Mỗi hàng trả lời một câu hỏi đơn giản. Khi cập nhật mã thông báo này, mỗi mã thông báo hiển thị sẽ quan trọng đến mức nào? Trong LLM chỉ dành cho bộ giải mã, các vị trí trong tương lai bị che đi, đó là lý do tại sao phần trên bên phải của ma trận có màu xám trong hình bên dưới.
Tự chú ý về cơ bản là tìm hiểu các mẫu trọng số từ mã thông báo này đến mã thông báo khác, dưới lớp vỏ nhân quả và sau đó sử dụng chúng để xây dựng các biểu diễn mã thông báo nhận biết ngữ cảnh.

Nguồn tin: Ahead of AI — Tác giả: Sebastian Raschka, PhD. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.