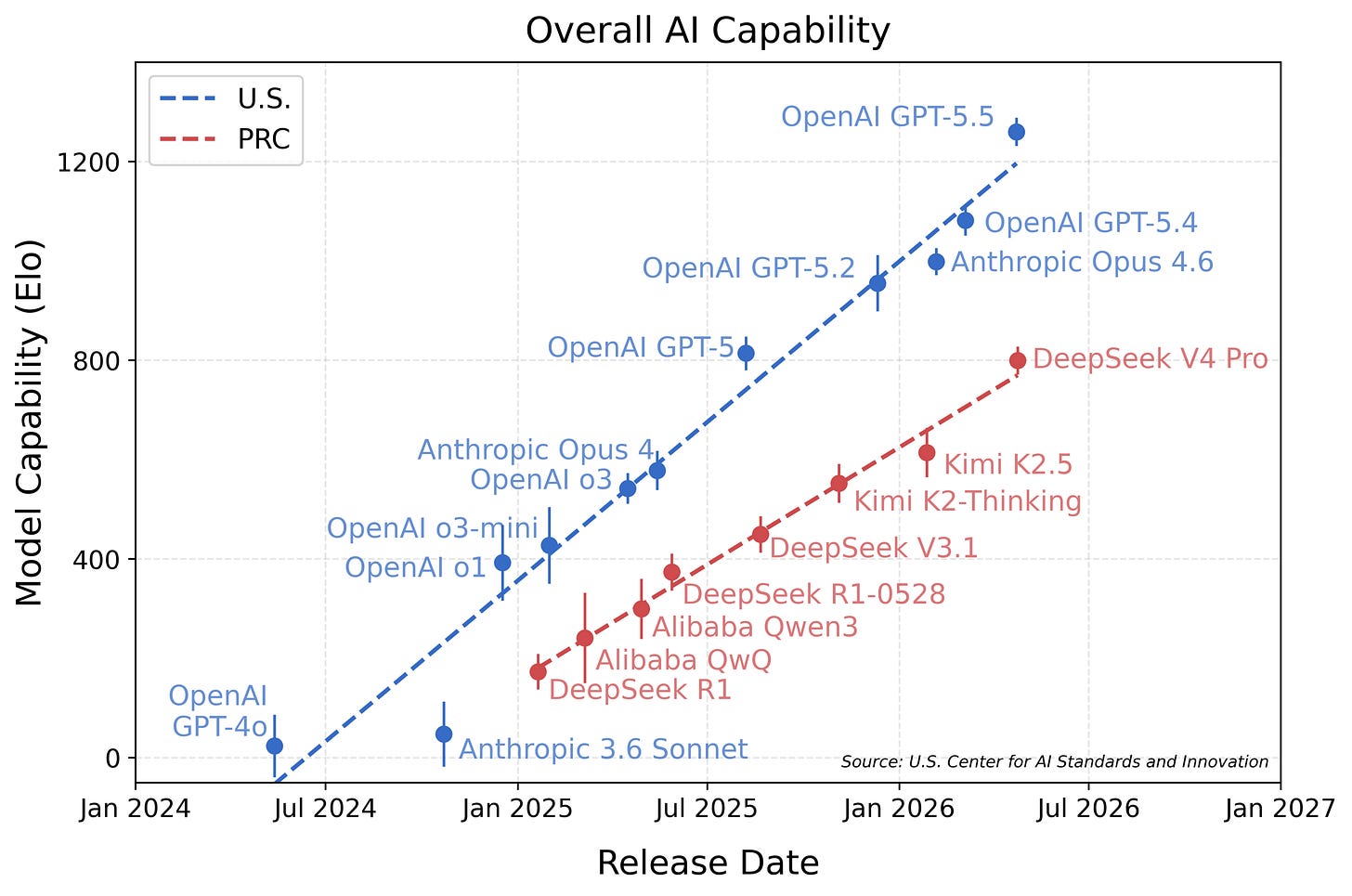
Tháng này thật đông đúc, với tất cả các phòng thí nghiệm biên giới mở, bao gồm cả DeepSeek, đều phát hành các mẫu mới. Điều thứ hai đã thúc đẩy sự đánh giá của Trung tâm Tiêu chuẩn và Đổi mới AI (CAISI), nơi đã đánh giá các mô hình mở và rủi ro của chúng trong quá khứ. Kết quả của họ là các mô hình mở tụt hậu so với biên giới của Mỹ, với khoảng cách ngày càng rộng hơn theo thời gian:
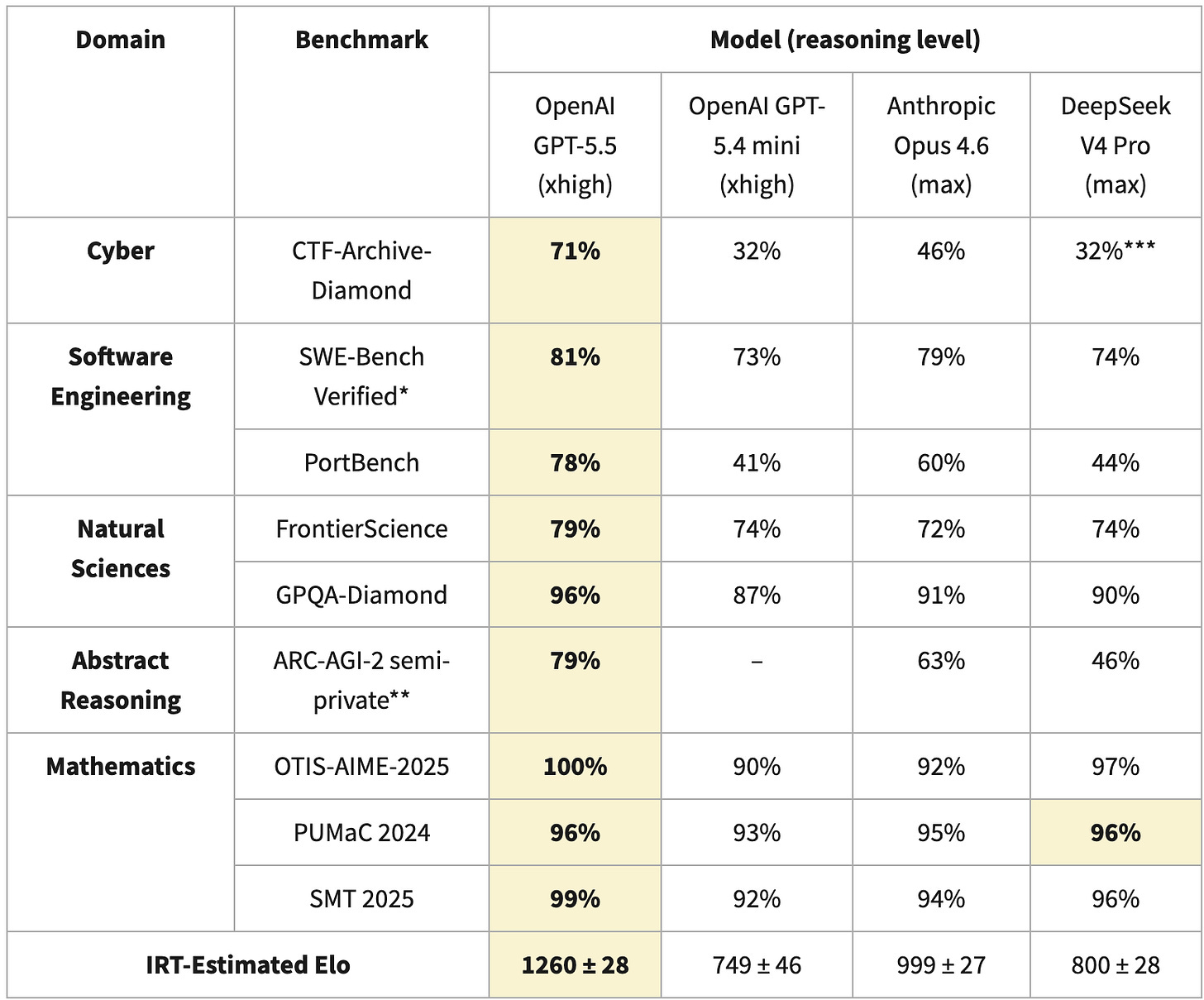
Đối với báo cáo, họ tính điểm Elo dựa trên Lý thuyết phản hồi mục, thường được sử dụng để so sánh các mô hình khác nhau, ngay cả khi chúng được kiểm tra trên một bộ điểm chuẩn khác. Đối với V4, CAISI đã sử dụng chín điểm chuẩn khác nhau:
Elo d khổng lồ
Tháng này thật đông đúc, với tất cả các phòng thí nghiệm biên giới mở, bao gồm cả DeepSeek, đều phát hành các mẫu mới. Điều thứ hai đã thúc đẩy sự đánh giá của Trung tâm Tiêu chuẩn và Đổi mới AI (CAISI), nơi đã đánh giá các mô hình mở và rủi ro của chúng trong quá khứ. Kết quả của họ là các mô hình mở tụt hậu so với biên giới của Mỹ, với khoảng cách ngày càng rộng hơn theo thời gian:
Đối với báo cáo, họ tính điểm Elo dựa trên Lý thuyết phản hồi mục, thường được sử dụng để so sánh các mô hình khác nhau, ngay cả khi chúng được kiểm tra trên một bộ điểm chuẩn khác. Đối với V4, CAISI đã sử dụng chín điểm chuẩn khác nhau:
Sự khác biệt lớn về Elo được giải thích là do điểm kém của DeepSeek V4 trong CTF-Archive-Diamond (chỉ được chạy với một tập hợp con của điểm chuẩn và được ngoại suy bằng IRT cho V4), PortBench (điểm chuẩn riêng của CAISI) và ARC-AGI-2 (với phương pháp tính điểm khác với bảng xếp hạng công khai). Sự khác biệt trong các điểm chuẩn này có tác động rất lớn đến Elo tổng thể, điều này có thể làm trầm trọng thêm sự khác biệt về khả năng.
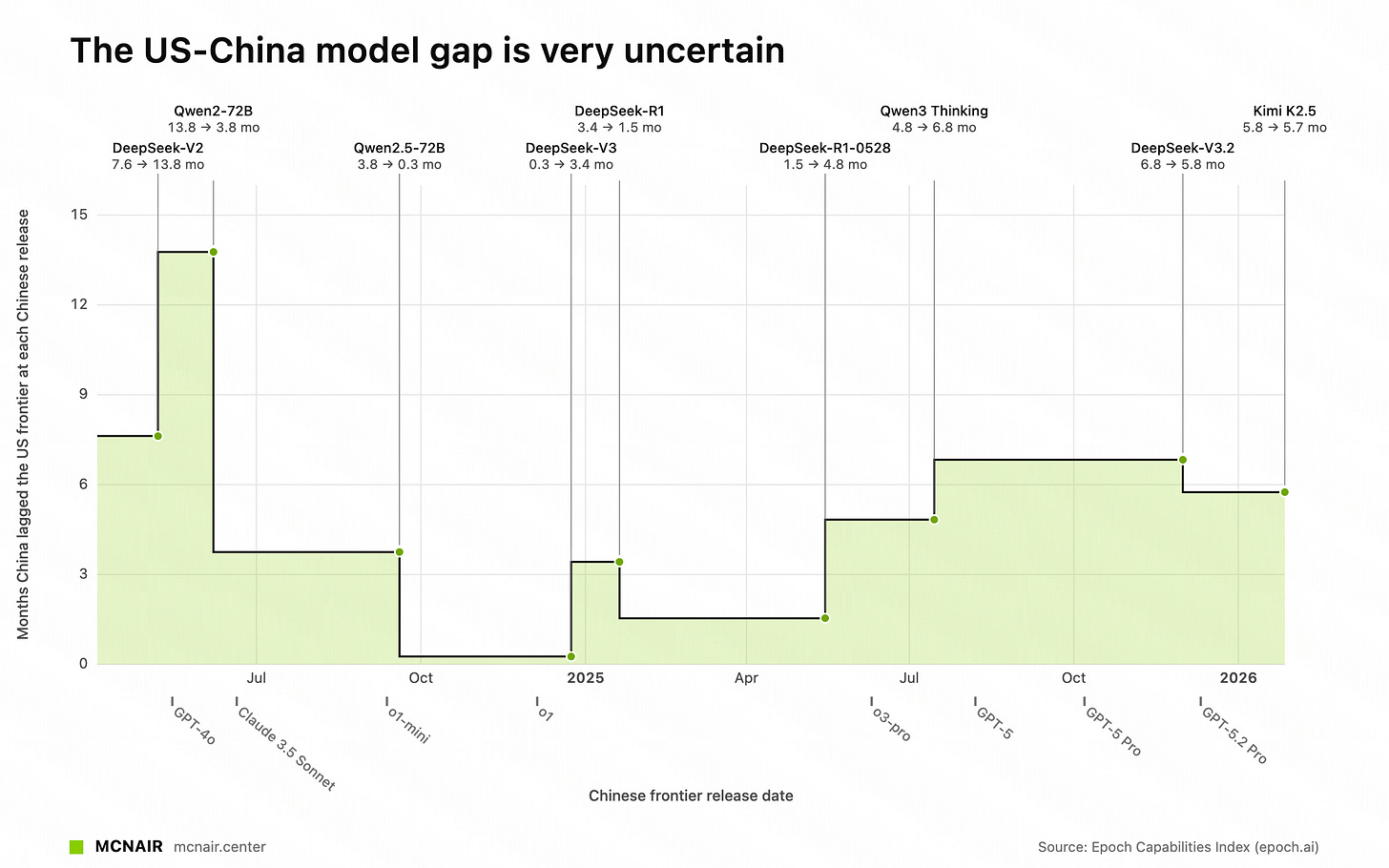
Khi sử dụng ECI của Epoch AI, vốn cũng sử dụng IRT trên một loạt các điểm chuẩn khác nhau, chúng tôi thấy rằng khoảng cách gần như nằm trong khoảng từ 3-7 tháng kể từ R1:
Khoảng cách mở<>đóng trong ECI (từ https://mcnair.center/china/)
Tuy nhiên, cả CAISI và ECI đều vẽ ra một bức tranh chưa hoàn chỉnh vì cả hai đều sử dụng các thiết lập được tiêu chuẩn hóa (và đơn giản) để so sánh khả năng của các mô hình. Cụ thể hơn: Các tác vụ mã hóa được đánh giá bằng cách sử dụng quyền truy cập vào bash và vòng lặp for với ngân sách mã thông báo cố định, không phải bằng các khai thác như Mã Claude hoặc OpenCode, những mô hình được đào tạo! Các thiết lập này dẫn đến điểm chuẩn cho rằng hiện không thể chuyển ứng dụng sang ngôn ngữ khác, trong khi Bun đã được chuyển từ Zig sang Rust với 1 triệu LOC thay đổi1.
Do đó, chúng tôi lập luận rằng việc so sánh biên giới giữa các mô hình mở và đóng cũng sẽ cần phát huy khả năng của tất cả các mô hình tốt hơn, có nghĩa là việc sử dụng các dây nịt ưu tiên cũng như lời nhắc dành riêng cho từng mô hình.
Phần này được viết chủ yếu bởi Florian. Một động lực thú vị trong Interconnects là Florian tin tưởng nhiều hơn vào sự gần gũi của các mô hình biên giới mở với các lựa chọn thay thế khép kín trong hiệu suất thực sự. Nathan cho rằng các tiêu chuẩn cũng không hoàn hảo nhưng cho rằng các mô hình khép kín đang dẫn trước nhiều hơn. Chúng tôi sẽ tiếp tục giải thích điều này trong nội dung tương lai của chúng tôi.
Chia sẻ
Lựa chọn của chúng tôi
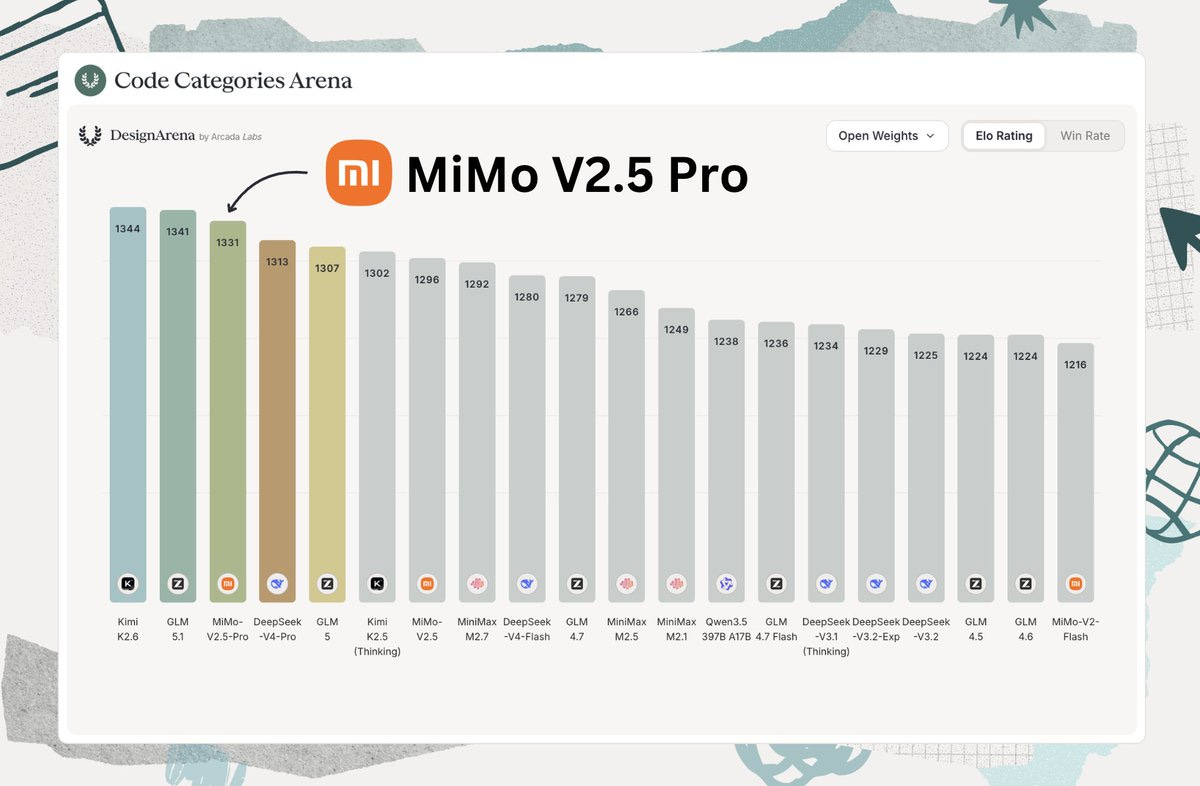
MiMo-V2.5-Pro của XiaomiMiMo: Độc giả Avid Artifacts biết rằng Xiaomi đã làm việc trên các mẫu máy mở được một thời gian; lần ra mắt của nó cách đây đúng một năm. Tiến độ phát hành của nó rất đáng chú ý, với 2.5 Pro (được phát hành theo Apache 2.0) sánh ngang với các mẫu hàng đầu khác như Kimi K2.6 và GLM-5.1 cả về điểm chuẩn và cách sử dụng trong thế giới thực.
gemma-4-26B-A4B-it của google (đăng đầy đủ trên Interconnects tại đây): Bản cập nhật được chờ đợi từ lâu cho dòng Gemma, có nhiều kích cỡ: mô hình dày đặc 4B, 9B và 31B, cũng như MoE 26B-A4B. Quan trọng hơn nữa, với Gemma 4, Google đã quyết định sử dụng Apache 2.0 làm giấy phép của mình, điều này loại bỏ những thách thức pháp lý và không chắc chắn xung quanh việc diễn giải các giấy phép tùy chỉnh.
Kimi-K2.6 của moonshotai: Bản cập nhật cho dòng Kimi, mang lại hiệu suất mạnh mẽ hơn trên toàn diện và khiến nó trở thành một trong những mẫu mở tốt nhất hiện nay. Họ cũng tập trung vào hiệu suất trong thời gian dài, cho thấy các mô hình mở có khả năng chạy hàng giờ để hoàn thành nhiệm vụ hoặc tối ưu hóa hiệu suất. Với trọng tâm của mọi người là xây dựng các hệ thống giống như nghiên cứu tự động, việc thấy các mô hình mở bắt kịp là điều quan trọng.
Laguna-XS.2 bên hồ bơi: Poolside AI đã phát hành các mẫu tập trung vào mã hóa công khai đầu tiên, bao gồm cả XS.2 trọng lượng mở. Kích thước của nó (33B-A3B) khiến nó trở nên hấp dẫn khi sử dụng tại địa phương, với hiệu suất ngang bằng với các mẫu khác trong phạm vi kích thước đó. Bài đăng trên blog đi kèm rất đáng đọc, cũng như đi sâu vào việc hack phần thưởng trong quá trình đánh giá mã hóa.
DeepSeek-V4-Flash của deepseek-ai: DeepSeek cuối cùng đã phát hành phiên bản kế nhiệm của dòng V3, được cập nhật liên tục trong nhiều tháng. Nó có hai kích cỡ: Pro, là mẫu 1.6T-A49B MoE và Flash, mẫu 284B-13B. Dựa trên kinh nghiệm của những người khác, mẫu thứ hai dường như là ngôi sao thực sự của chương trình vì hiệu suất của nó tương đối mạnh, trong khi Pro dường như phân phối dưới mức so với kích thước của nó. Báo cáo công nghệ đi sâu vào chi tiết, bao gồm cả những thay đổi về kiến trúc được sử dụng để đạt được hiệu suất theo ngữ cảnh dài tốt hơn và rẻ hơn.
Người mẫu
Mục đích chung
Qwen3.6-35B-A3B của Qwen: Bản cập nhật cho dòng Qwen 3.5 nhắm đến một trong những kích thước được sử dụng rộng rãi nhất.
LFM2.5-350M của LiquidAI: Với 28T mã thông báo cho 350M thông số, mô hình này có thể là mô hình được đào tạo quá mức nhất hiện có.
Tư duy ba chiều lớn của arcee-ai: Phiên bản lý luận của Trinity, một trong những mô hình mở tốt nhất của phương Tây. Nó đã đứng đầu bảng xếp hạng OpenRouter trong một thời gian và có thể cung cấp năng lượng cho các ứng dụng tác nhân như OpenClaw.
GLM-5.1 của zai-org: Bản cập nhật cho GLM-5, cải thiện điểm số trên diện rộng. Trọng tâm của bản cập nhật này là các nhiệm vụ dài hạn.
Đọc thêm
Nguồn tin: Interconnects Newsletter — Tác giả: Florian Brand. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.