Hướng dẫn thực hành xây dựng nền tảng dữ liệu hoạt động hiệu quả trong môi trường sản xuất
Tồn tại một khoảng cách đáng kể giữa cách thức trình bày về dữ liệu trong các buổi nói chuyện và cách dữ liệu thực sự vận hành trong các công ty. Các slide hội nghị thường thể hiện các quy trình (pipeline) sạch sẽ, tuyến tính. Tuy nhiên, thực tế sản xuất lại phức tạp hơn: ba nhóm khác nhau cùng gọi đến một chủ đề Kafka với các lược đồ (schema) khác nhau, một mô hình dbt không có chủ sở hữu đã âm thầm kết nối sai bảng chiều (dimension table) trong sáu tháng, và một tính năng "được hỗ trợ bởi AI" hóa ra chỉ là một lệnh gọi API GPT-4 duy nhất không có logic thử lại (retry logic), không có giám sát, và không có giải pháp khi cửa sổ ngữ cảnh (context window) đầy.
Hướng dẫn thực hành xây dựng nền tảng dữ liệu hoạt động hiệu quả trong môi trường sản xuất
Có một khoảng cách đáng kể giữa cách hầu hết các buổi nói chuyện về dữ liệu được trình bày và cách dữ liệu thực sự luân chuyển trong các công ty. Các slide hội nghị thường thể hiện các đường ống (pipeline) sạch sẽ, tuyến tính. Thực tế sản xuất lại phức tạp hơn: ba nhóm khác nhau gọi cùng một chủ đề Kafka với các lược đồ (schema) khác nhau, một mô hình dbt không ai sở hữu đã âm thầm kết nối sai bảng thứ nguyên (dimension table) trong sáu tháng, và một tính năng "được hỗ trợ bởi AI" hóa ra chỉ là một lệnh gọi API GPT-4 duy nhất không có logic thử lại, không giám sát và không biết điều gì sẽ xảy ra khi cửa sổ ngữ cảnh (context window) đầy.
Vì vậy, tôi xin phác thảo một nền tảng dữ liệu hiện đại thực sự trông như thế nào, một nền tảng có thể xử lý khối lượng công việc AI, thực thi quản trị mà không yêu cầu một đội ngũ tuân thủ toàn thời gian, và thực sự có thể được triển khai bởi một nhóm bốn người thay vì bốn mươi người.
Tại sao ngăn xếp cũ không hoạt động hiệu quả với khối lượng công việc AI
Ngăn xếp truyền thống tập trung vào kho dữ liệu (warehouse-centric stack), ví dụ như Redshift hoặc BigQuery là trung tâm với một số DAG Airflow cung cấp dữ liệu, được thiết kế dựa trên một hợp đồng khá đơn giản. Dữ liệu có cấu trúc đi vào, các truy vấn SQL đi ra, các bảng điều khiển BI (BI dashboards) cập nhật qua đêm. Điều đó đã từng ổn.
AI thay đổi hợp đồng một cách cơ bản. Đường ống LLM của bạn có thể cần:
Văn bản thô, phi cấu trúc nằm trong S3 cùng với dữ liệu quan hệ sạch
Các nhúng (embeddings) được tính toán từ các bảng 50 triệu hàng trong thời gian thực
Các vector đặc trưng (feature vectors) được tạo ra trong mili giây cho một điểm cuối phục vụ mô hình
Toàn bộ dòng dữ liệu (data lineage) được theo dõi để một cuộc kiểm toán quy định có thể truy vết chính xác những hàng dữ liệu huấn luyện nào đã tạo ra một dự đoán cụ thể
Không có điều nào trong số này phù hợp một cách rõ ràng với mô hình cũ. Kho dữ liệu giả định cấu trúc. Hồ dữ liệu (data lake) có cấu trúc nhưng không có giao dịch. Cả hai đều không được xây dựng để phục vụ một cơ sở dữ liệu vector với độ trễ 10ms.
Kiến trúc Lakehouse, Delta Lake, Apache Iceberg hoặc Apache Hudi nằm trên bộ lưu trữ đối tượng (object storage), là câu trả lời trung thực cho vấn đề này. Nó mang lại cho bạn sự linh hoạt của một hồ dữ liệu với đủ tính toàn vẹn giao dịch để tin cậy dữ liệu của bạn. Nhưng đó chỉ là một phần của câu trả lời.
Kiến trúc Medallion: Không chỉ có Bronze và Gold
Bạn có thể đã thấy sơ đồ medallion trước đây. Bronze là dữ liệu thô, Silver là dữ liệu đã được làm sạch, Gold là dữ liệu sẵn sàng cho kinh doanh. Đủ đơn giản. Nhưng có một vài điều mà mọi người thường bỏ qua.
Tầng thứ tư, mà tôi gọi là tầng Platinum hoặc tầng AI-native, là phần mà hầu hết các nhóm bỏ lỡ. Một khi dữ liệu của bạn đã sạch và sẵn sàng cho kinh doanh trong tầng Gold, vẫn còn công việc phải làm để làm cho nó sẵn sàng cho AI. Các nhúng cần được tính toán và lưu trữ ở một nơi nhanh chóng. Các tập dữ liệu tinh chỉnh (fine-tuning datasets) cần được quản lý, lập phiên bản và theo dõi. Các vector đặc trưng cho các mô hình ML thời gian thực cần được vật chất hóa trước (pre-materialised) để điểm cuối phục vụ của bạn không phải tính toán chúng tại thời điểm truy vấn.
Một điều tôi muốn phản đối ở đây: nhiều nhóm coi tầng thứ tư này là tùy chọn, một thứ để thêm vào sau. Trên thực tế, nếu bạn không thiết kế cho nó ngay từ đầu, việc trang bị thêm nó vào một cấu trúc bảng Iceberg hiện có là thực sự khó khăn. Bạn sẽ kết thúc với các bảng nhúng không được liên kết với các hàng nguồn của chúng trong biểu đồ dòng dữ liệu, điều này khiến việc kiểm toán gần như không thể.
Thời gian thực so với Xử lý hàng loạt: Cuộc tranh luận Lambda (hầu hết) đã kết thúc
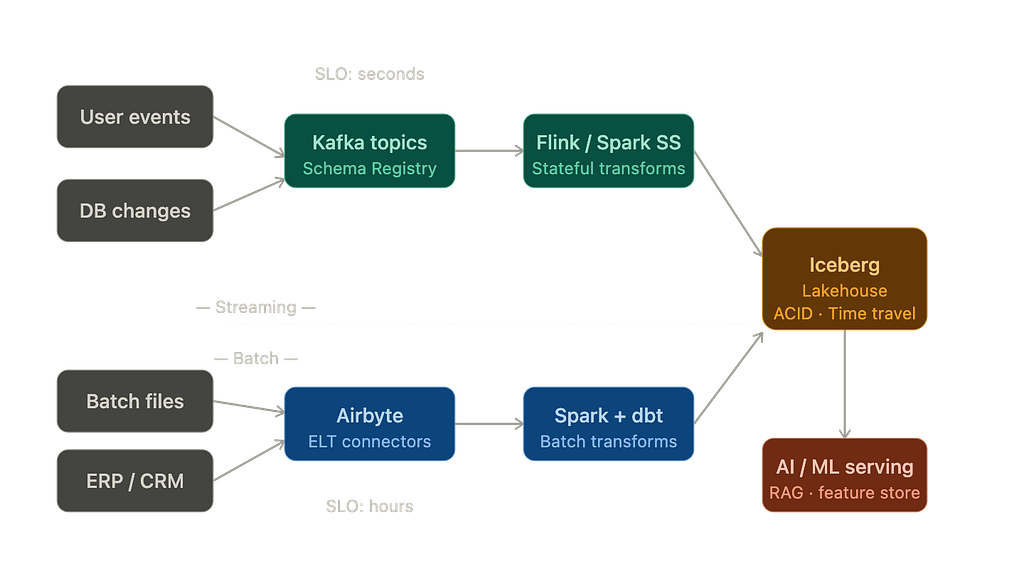
Trong nhiều năm, các kỹ sư dữ liệu đã tranh luận về kiến trúc Lambda so với kiến trúc Kappa. Lambda nói: chạy hai đường ống, một cho thời gian thực và một cho xử lý hàng loạt, sau đó hợp nhất các đầu ra. Kappa nói: chỉ cần sử dụng streaming cho mọi thứ.
Cả hai phe đều đúng một phần. Lý tưởng "streaming cho mọi thứ" của Kappa gặp phải thực tế là xử lý hàng loạt vẫn rẻ hơn và đáng tin cậy hơn cho các tập dữ liệu lịch sử lớn.
Tuy nhiên, cách tiếp cận "đường ống kép" của Lambda tạo ra những vấn đề phức tạp trong đồng bộ hóa. Câu trả lời trung thực vào năm 2026 sẽ là một điều gì đó tương tự như sau:
Điểm mấu chốt trong kiến trúc này là Iceberg đóng vai trò là điểm hợp nhất. Flink có thể ghi các vi lô (micro-batches) vào một bảng Iceberg mỗi 30 giây. Spark có thể ghi đè toàn bộ các phân vùng của cùng một bảng trong một lần chạy lô hàng đêm. Cả hai thao tác ghi đều an toàn theo chuẩn ACID. Các ứng dụng tiêu thụ dữ liệu (downstream consumers), dù là công cụ BI hay tác nhân được hỗ trợ bởi LLM, luôn thấy một bản ghi nhất quán.
Các mục tiêu mức độ dịch vụ (SLO) về độ trễ cũng đáng được đề cập rõ ràng. Đường dẫn thời gian thực của bạn phải đáp ứng các yêu cầu về độ trễ được đo bằng giây. Đường dẫn lô hàng của bạn được đo bằng giờ. Hai đường ống này cần giám sát khác nhau, cảnh báo khác nhau và thường là các nhóm khác nhau quản lý. Tôi đã thấy các tổ chức gộp hai SLO này vào một ca trực và kết quả là không tốt.
Quản trị không phải là một tính năng, mà là một nền tảng
Đây là phần tôi muốn dành nhiều thời gian, bởi vì quản trị là điều thường được thiết kế sau cùng và hối tiếc đầu tiên.
Hầu hết các nhóm coi quản trị dữ liệu như một khoản thuế quy định. Bạn làm tối thiểu những gì cần thiết để vượt qua cuộc kiểm toán, bạn gắn một danh mục dữ liệu lên trên bất cứ thứ gì đã tồn tại, và bạn coi đó là xong. Điều đó hoạt động tốt cho đến khi đường ống huấn luyện LLM của bạn vô tình nhập dữ liệu PII lẽ ra phải được che giấu trong Silver. Hoặc cho đến khi các dự đoán của mô hình biến động bị thách thức trong một vụ kiện và bạn không thể tái tạo phiên bản nào của tính năng nào đã được sử dụng tại thời điểm suy luận.
Một vài điều đáng được đề cập rõ ràng ở đây.
Dòng dõi cấp cột (Column-level lineage) là không thể thiếu khi bạn làm AI. Dòng dõi cấp bảng, "bảng này được tạo ra từ ba bảng kia," là hữu ích. Nhưng nó không cho bạn biết cột cụ thể nào đã cung cấp dữ liệu cho một mô hình. Nếu một cơ quan quản lý hỏi tại sao mô hình chấm điểm tín dụng của bạn tạo ra một kết quả cụ thể, bạn cần truy ngược từ các tính năng đầu vào của mô hình đến các cột nguồn của chúng trong dữ liệu thô, bao gồm bất kỳ phép biến đổi nào đã xảy ra trên đường đi. OpenLineage là tiêu chuẩn mở ở đây, và cả Airflow và dbt đều có thể phát ra các sự kiện dòng dõi để điền vào các công cụ như Marquez hoặc DataHub.
Hợp đồng dữ liệu là yếu tố mở khóa thực sự. Ý tưởng khá đơn giản: trước khi một nhóm sản xuất thay đổi lược đồ hoặc SLA của một bảng, họ phải đàm phán thay đổi đó với tất cả các ứng dụng tiêu thụ dữ liệu. Trên thực tế, điều này có nghĩa là xác định một hợp đồng YAML (lược đồ Avro hoạt động tốt ở đây) chỉ định tên cột, kiểu dữ liệu, đảm bảo khả năng chấp nhận giá trị null và SLA về độ tươi mới dự kiến. Vi phạm hợp đồng, phá vỡ quá trình xây dựng. Các công cụ như
Nguồn tin: Medium Towards AI — Tác giả: Sunil kumar Reddy. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.