Google DeepMind vừa phát hành Gemma 4 12B, một mô hình đa phương thức dày đặc loại bỏ hoàn toàn các bộ mã hóa truyền thống. Dữ liệu hình ảnh và âm thanh được đưa trực tiếp vào lõi LLM. Kết quả là một mô hình có thể chạy các quy trình tác nhân trên máy tính xách tay thông thường với 16 GB RAM. Mô hình này được phát hành theo giấy phép Apache 2.0.
Tổng quan và truy cập mô hình
Gemma 4 12B là một mô hình transformer chỉ có bộ giải mã với 12 tỷ tham số. Mô hình này xử lý văn bản, hình ảnh, âm thanh và video một cách tự nhiên. Không có bộ mã hóa hình ảnh hoặc âm thanh riêng biệt. Bộ giải mã sử dụng cấu trúc tương tự như mô hình Gemma 4 31B Dense. Mô hình này thu hẹp khoảng cách giữa các thiết bị biên.
Google DeepMind vừa phát hành Gemma 4 12B, một mô hình đa phương thức dày đặc loại bỏ hoàn toàn các bộ mã hóa truyền thống. Dữ liệu hình ảnh và âm thanh được đưa trực tiếp vào lõi LLM. Kết quả là một mô hình có thể chạy các quy trình tác nhân trên máy tính xách tay thông thường với 16 GB RAM. Mô hình này được phát hành theo giấy phép Apache 2.0.
Tổng quan & Truy cập Mô hình
Gemma 4 12B là một bộ biến đổi chỉ có bộ giải mã với 12 tỷ tham số. Mô hình này xử lý văn bản, hình ảnh, âm thanh và video một cách tự nhiên. Không có bộ mã hóa hình ảnh hoặc âm thanh riêng biệt. Bộ giải mã sử dụng cấu trúc tương tự như mô hình Gemma 4 31B Dense. Mô hình này thu hẹp khoảng cách giữa E4B thân thiện với biên và biến thể Mixture of Experts 26B lớn hơn.
Kiến trúc: Bộ biến đổi chỉ có bộ giải mã, thống nhất, không có bộ mã hóa.
Các phương thức: Đầu vào văn bản, hình ảnh, video và âm thanh gốc — Gemma cỡ trung đầu tiên có âm thanh.
Yêu cầu phần cứng: 16 GB VRAM hoặc bộ nhớ hợp nhất. Chạy trên máy tính xách tay GPU thông thường và máy Mac Apple Silicon.
Giấy phép: Apache 2.0. Các trọng số được mở và có thể tải xuống công khai.
Ngăn xếp suy luận: Tương thích với llama.cpp, MLX, vLLM, Ollama, SGLang, Unsloth và LM Studio.
Tải xuống: Hugging Face và Kaggle. Biến thể hướng dẫn là google/gemma-4-12B-it.
Tích hợp: Hugging Face Transformers, LiteRT-LM CLI và máy chủ API cục bộ tương thích OpenAI thông qua litert-lm serve.
Một mô hình dự thảo Multi-Token Prediction (MTP) chuyên dụng cũng được phát hành. Mô hình này giảm độ trễ suy luận trên phần cứng cục bộ.
Kiến trúc: Thiết kế không có bộ mã hóa
Mọi mô hình Gemma cỡ trung trước đây đều sử dụng các bộ mã hóa Transformer riêng biệt cho hình ảnh và âm thanh. Các bộ mã hóa đó làm tăng độ trễ và chi phí tham số. Các mô hình Gemma 4 cỡ trung có bộ mã hóa hình ảnh 550M tham số. Các mô hình E2B và E4B bao gồm bộ mã hóa âm thanh 300M tham số. Tất cả những điều đó đã được loại bỏ trong 12B.
Bộ nhúng hình ảnh (35M tham số): Hình ảnh thô được chia thành các mảng 48×48 pixel. Mỗi mảng được chiếu vào chiều ẩn của LLM bằng một phép nhân ma trận duy nhất. Không có lớp chú ý; mỗi mảng được xử lý độc lập. Vị trí không gian được đưa vào bằng cách sử dụng tra cứu tọa độ phân tích: một ma trận X đã học và một ma trận Y đã học. Đối với một mảng tại (x, y), mô hình tra cứu hai nhúng đã học và thêm chúng để tạo thành một vectơ vị trí. Điều này được thêm vào nhúng mảng, sau đó là chuẩn hóa. Đó là toàn bộ quy trình hình ảnh.
Chiếu sóng âm thanh: Âm thanh thô 16 kHz được cắt thành các khung 40 ms. Mỗi khung chứa 640 giá trị. Các giá trị đó được chiếu tuyến tính vào cùng một không gian nhúng với các mã thông báo văn bản. Không có trích xuất tính năng và không có lớp conformer. Rotary Position Embedding (RoPE) hiện có của LLM xử lý chuỗi thời gian 1-D. Bộ mã hóa âm thanh trong E2B và E4B đã sử dụng 12 lớp conformer. Tất cả những điều đó đã được loại bỏ.
Tầm quan trọng: Không gian trọng số thống nhất có nghĩa là không còn phải điều chỉnh riêng các bộ mã hóa cố định. Điều chỉnh tinh chỉnh tiếp theo với LoRA hoặc điều chỉnh đầy đủ cập nhật xử lý hình ảnh, âm thanh và văn bản trong một lần. Hugging Face Transformers và Unsloth đã hỗ trợ điều này.
Thiết kế không có bộ mã hóa làm giảm độ trễ đa phương thức. Lõi LLM bắt đầu xử lý ngay lập tức. Không có bộ mã hóa nào phải hoàn thành trước.
Khả năng & Hiệu suất
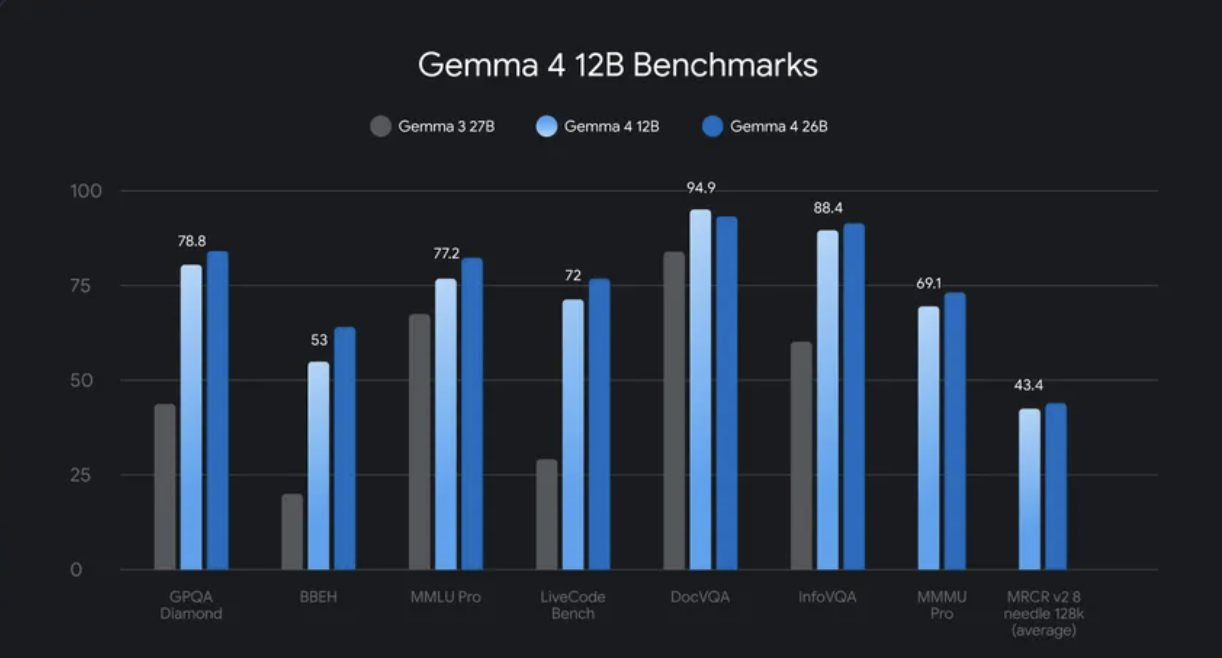
Nhóm Google DeepMind chưa công bố đầy đủ kết quả điểm chuẩn trong các tài liệu ra mắt ban đầu. Các ghi chú phát hành chính thức cho biết mô hình 12B hoạt động gần bằng mô hình 26B MoE trên các điểm chuẩn tiêu chuẩn, với tổng dung lượng bộ nhớ ít hơn một nửa.
https://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/
Các khả năng được chứng minh của mô hình bao gồm:
Nhận dạng giọng nói tự động. Chuyển đổi âm thanh nguyên bản mà không cần quy trình ASR (nhận dạng giọng nói tự động) bên ngoài.
Suy luận tác nhân. Chạy các quy trình làm việc đa bước cục bộ, với hiệu suất tiếp cận mô hình MoE 26B.
Phân tách giọng nói. Phân biệt người nói trong đầu vào âm thanh.
Hiểu video. Xử lý các khung video cùng với âm thanh. Một bản demo đã phân tích một phân đoạn chính trong Google I/O dài 5 phút bằng cách sử dụng 313 khung hình ở tốc độ 1 FPS với ngân sách mã thông báo hình ảnh là 70 cho mỗi khung hình.
Lập trình. Xây dựng một ứng dụng xử lý hình ảnh Gradio bằng cách sử dụng tính năng tạo mã riêng, được phục vụ cục bộ với llama.cpp.
Quy trình làm việc tác nhân đa phương thức. Kho lưu trữ Gemma Skills chính thức tại github.com/google-gemma/gemma-skills cung cấp các khả năng tác nhân được xây dựng sẵn.
Trong ứng dụng Google AI Edge Eloquent của Google, việc chuyển sang Gemma 4 12B đã tạo ra một bước nhảy vọt về chất lượng tổng thể hơn 60%, với việc cải thiện khả năng tuân thủ hướng dẫn và phạm vi, theo báo cáo của Google.
Giải thích trực quan của Marktechpost
Phát hành ngày 3/6/2026
Gemma 4 12B
Mô hình đa phương thức hợp nhất, không bộ mã hóa của Google DeepMind
Một bộ biến đổi chỉ bộ giải mã 12 tỷ tham số loại bỏ các bộ mã hóa hình ảnh và âm thanh riêng biệt. Hình ảnh và âm thanh đi thẳng vào xương sống LLM. Nó chạy cục bộ trên máy tính xách tay 16 GB theo giấy phép Apache 2.0.
Không bộ mã hóa — không có bộ mã hóa hình ảnh hoặc âm thanh riêng biệt
Gemma cỡ trung đầu tiên có đầu vào âm thanh gốc; bổ sung video
Sẵn sàng cục bộ — 16 GB VRAM hoặc bộ nhớ hợp nhất
Tổng quan & Truy cập
Những gì được phát hành
Thông số kỹ thuật, trọng số và ngăn xếp suy luận
Kiến trúc — chỉ bộ giải mã, cấu trúc tương tự như Gemma 4 31B Dense
Các phương thức — văn bản, hình ảnh, video và âm thanh gốc
Phần cứng — 16 GB VRAM / bộ nhớ hợp nhất; máy tính xách tay GPU và Apple Silicon
Giấy phép — Apache 2.0; trọng số trên Hugging Face và Kaggle
Biến thể hướng dẫn — google/gemma-4-12B-it
Tốc độ — một bộ soạn thảo Multi-Token Prediction (MTP) chuyên dụng cũng được phát hành
Kiến trúc & Thị giác
Một bộ nhúng thị giác 35M
Thay thế bộ mã hóa thị giác 550M của các mô hình cỡ trung
Hình ảnh thô được chia thành các mảng 48x48 pixel
Mỗi mảng được chiếu vào chiều ẩn LLM bằng một phép nhân ma trận đơn
Không có lớp chú ý — mỗi mảng được xử lý độc lập
Vị trí thông qua tra cứu tọa độ X/Y được phân tích, sau đó chuẩn hóa
Đó là toàn bộ quy trình thị giác
Kiến trúc & Âm thanh
Chiếu sóng âm thanh trực tiếp
Không có lớp conformer, n
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.