Hầu hết các tác nhân tìm kiếm (search agents) được huấn luyện như các chính sách (policies) trên một bản ghi đang phát triển. Mô hình quyết định cách tìm kiếm. Nó cũng phải ghi nhớ những gì đã thấy, bằng chứng nào quan trọng và những tuyên bố nào đã được kiểm tra. Một nhóm các nhà nghiên cứu từ Đại học Illinois Urbana-Champaign, UC Berkeley và Chroma cho rằng điều này đòi hỏi quá nhiều. Học tăng cường (Reinforcement learning) cuối cùng tối ưu hóa cả quyết định tìm kiếm và việc ghi chép thường xuyên cùng một lúc.
Giải pháp của họ là Harness-1, một tác nhân phụ truy xuất (retrieval subagent) 20B được xây dựng trên gpt-oss-20b. Nó được huấn luyện bằng học tăng cường bên trong một bộ khung tìm kiếm có trạng thái (stateful search harness). Bộ khung này đảm nhiệm việc ghi chép.
Hầu hết các tác nhân tìm kiếm được huấn luyện như các chính sách trên một bản ghi đang phát triển. Mô hình quyết định cách tìm kiếm. Nó cũng phải ghi nhớ những gì đã thấy, bằng chứng nào quan trọng và những tuyên bố nào đã được kiểm tra. Một nhóm các nhà nghiên cứu từ Đại học Illinois Urbana-Champaign, UC Berkeley và Chroma lập luận rằng điều này đòi hỏi quá nhiều. Học tăng cường cuối cùng tối ưu hóa cả quyết định tìm kiếm và việc ghi sổ định kỳ cùng một lúc.
Giải pháp của họ là Harness-1, một tác nhân phụ truy xuất 20B được xây dựng trên gpt-oss-20b. Nó được huấn luyện bằng học tăng cường bên trong một bộ điều khiển tìm kiếm có trạng thái. Bộ điều khiển này giữ việc ghi sổ. Chính sách giữ các quyết định ngữ nghĩa. Mã nguồn và mã bộ điều khiển được phát hành công khai.
https://arxiv.org/pdf/2606.02373
Harness-1 thực sự là gì
Harness-1 tạo ra một tập hợp các tài liệu được xếp hạng cho một mô hình trả lời hạ nguồn. Nó không tự trả lời câu hỏi. Nó chạy bên trong một bộ điều khiển máy trạng thái tập trung vào một WORKINGMEMORY (bộ nhớ làm việc) cho mỗi phiên.
Mỗi lượt hoạt động như một vòng lặp. Bộ điều khiển hiển thị trạng thái tìm kiếm nhỏ gọn cùng với các hành động gần đây. Mô hình phát ra một hành động có cấu trúc. Bộ điều khiển thực thi nó, cập nhật trạng thái và hiển thị quan sát tiếp theo.
Bộ điều khiển có trạng thái: Những gì di chuyển ra khỏi chính sách
Nhóm nghiên cứu gọi nguyên tắc của họ là giảm tải nhận thức có trạng thái. Chính sách quyết định những gì cần tìm kiếm, quản lý và xác minh, và khi nào dừng lại. Bộ điều khiển duy trì trạng thái có thể phục hồi xung quanh các quyết định đó.
Trạng thái đó bao gồm một số phần. Một nhóm ứng viên chứa các tài liệu được nén, loại bỏ trùng lặp. Một tập hợp được quản lý gắn thẻ mức độ quan trọng là đầu ra cuối cùng, giới hạn ở 30 tài liệu. Các thẻ có bốn giá trị: very_high (rất cao), high (cao), fair (khá) hoặc low (thấp). Một kho lưu trữ toàn văn giữ mọi đoạn được truy xuất bên ngoài lời nhắc.
Một biểu đồ bằng chứng bổ sung cấu trúc. Một bộ trích xuất regex quét từng đoạn để tìm danh từ riêng, năm và ngày. Bộ điều khiển sau đó hiển thị các thực thể thường xuyên, tài liệu cầu nối và các thực thể đơn lẻ. Tài liệu cầu nối chứa hai hoặc nhiều thực thể thường xuyên. Các thực thể đơn lẻ xuất hiện trong một tài liệu và gợi ý các đầu mối tiếp theo.
Chính sách hoạt động thông qua tám công cụ. Đó là fan_out_search (tìm kiếm mở rộng), search_corpus (tìm kiếm kho ngữ liệu), grep_corpus (tìm kiếm kho ngữ liệu bằng grep), read_document (đọc tài liệu), review_docs (xem xét tài liệu), curate (quản lý), verify (xác minh) và end_search (kết thúc tìm kiếm). Kết quả tìm kiếm được nén bằng sentence-BM25, giữ lại bốn câu hàng đầu. Loại bỏ trùng lặp hai cấp loại bỏ các bản lặp bằng ID đoạn và dấu vân tay nội dung.
Một lựa chọn thiết kế giải quyết các vấn đề khởi động lạnh. Lần tìm kiếm thành công đầu tiên tự động gieo hạt tập hợp được quản lý với tám kết quả được xếp hạng lại ở mức độ quan trọng khá. Chính sách sau đó thúc đẩy các tài liệu mạnh và loại bỏ các tài liệu yếu. Điều này biến nhiệm vụ từ xây dựng từ đầu thành tinh chỉnh.
Nhóm nghiên cứu nêu ra ba yêu cầu đối với một bộ điều khiển có thể huấn luyện. Đó là quản lý khởi động nóng, hiển thị trạng thái dẫn xuất nhỏ gọn và các khuyến khích bảo toàn sự đa dạng. Harness-1 thực hiện cả ba.
Cách nó được huấn luyện
Huấn luyện chia theo cùng một dòng với bộ điều khiển. Tinh chỉnh có giám sát dạy mô hình vận hành giao diện. Học tăng cường cải thiện các quyết định tìm kiếm trên trạng thái được duy trì.
Một giáo viên duy nhất, GPT-5.4, chạy trực tiếp bên trong bộ điều khiển đầy đủ. Sau khi lọc, 899 quỹ đạo còn lại cho SFT. Mô hình sử dụng LoRA ở hạng 32 trong ba kỷ nguyên. Điểm kiểm tra bước 550 khởi tạo RL.
RL sử dụng CISPO trên chính sách với giới hạn 40 lượt và phần thưởng chỉ ở cuối. Nó chỉ huấn luyện trên các truy vấn SEC. Các nhóm có phần thưởng giống hệt nhau bị loại bỏ khỏi gradient. Huấn luyện được thực hiện trên Tinker.
Phần thưởng phân tách quá trình khám phá khỏi quá trình lựa chọn. Phần thưởng này cũng bổ sung một ưu đãi về sự đa dạng của công cụ. Nếu không có ưu đãi này, tác nhân sẽ lặp lại quá trình tìm kiếm. Khi đó, khả năng truy hồi được chọn lọc sẽ ổn định ở mức gần 0,53. Với ưu đãi này, sự đa dạng ổn định và khả năng truy hồi đạt khoảng 0,60.
Trường hợp chuẩn
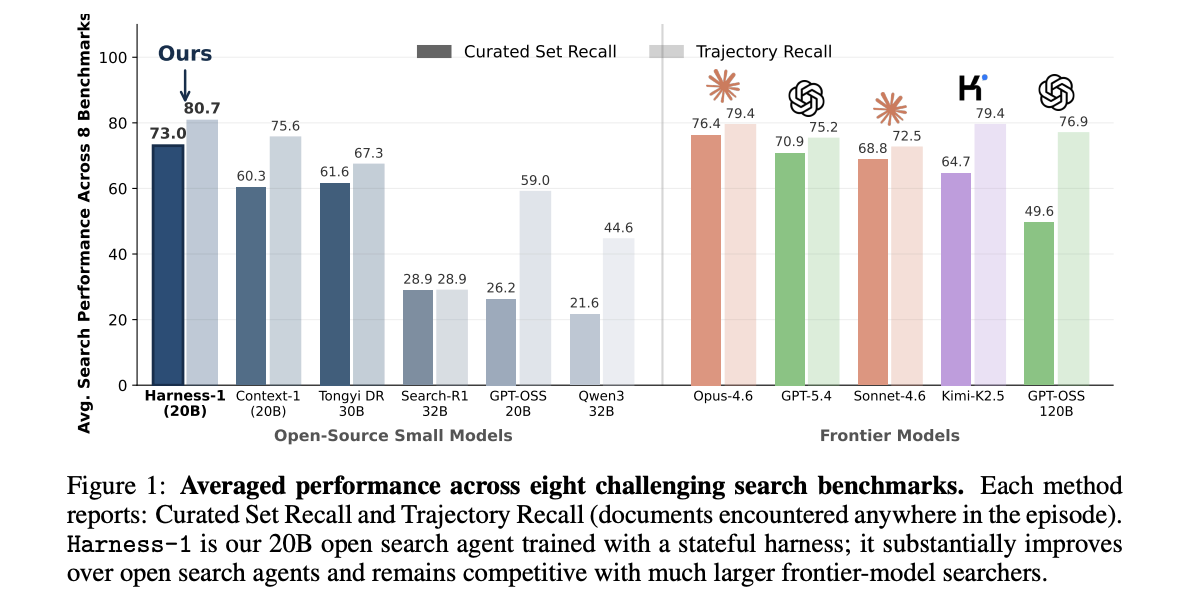
Harness-1 được đánh giá trên tám bộ dữ liệu chuẩn bao gồm web, tài chính, bằng sáng chế và QA đa bước. Thước đo chính là khả năng truy hồi được chọn lọc: mức độ bao phủ các tài liệu liên quan trong tập hợp cuối cùng. Khả năng truy hồi theo quỹ đạo tính toán bằng chứng gặp phải ở bất kỳ đâu trong một phiên.
| Loại mô hình | Khả năng truy hồi được chọn lọc trung bình | Khả năng truy hồi theo quỹ đạo trung bình |
|---|---|---|
| Harness-1 (20B) | Mở nhỏ | 0,730 | 0,807 |
| Tongyi DeepResearch 30B | Mở nhỏ | 0,616 | 0,673 |
| Context-1 (20B) | Mở nhỏ | 0,603 | 0,756 |
| Search-R1 (32B) | Mở nhỏ | 0,289 | 0,289 |
| GPT-OSS-20B | Mở nhỏ | 0,262 | 0,590 |
| Qwen3 (32B) | Mở nhỏ | 0,216 | 0,446 |
| Opus-4.6 | Tiên phong | 0,764 | 0,794 |
| GPT-5.4 | Tiên phong | 0,709 | 0,752 |
| Sonnet-4.6 | Tiên phong | 0,688 | 0,725 |
| Kimi-K2.5 | Tiên phong | 0,647 | 0,794 |
| GPT-OSS-120B | Tiên phong | 0,496 | 0,769 |
Trung bình trên tám bộ dữ liệu chuẩn, từ Hình 1 của bài báo. Các mô hình tiên phong được chạy dưới dạng bộ truy xuất zero-shot (truy xuất không cần huấn luyện) trong hệ thống Harness Context-1.
Harness-1 đạt khả năng truy hồi được chọn lọc trung bình 0,730. Con số này vượt trội so với tác nhân phụ mở tiếp theo, Tongyi DeepResearch 30B, 11,4 điểm. Trong số các công cụ tìm kiếm tiên phong được thử nghiệm, chỉ có Opus-4.6 đạt điểm trung bình cao hơn.
Mô hình chuyển giao là tín hiệu rõ ràng nhất của cơ chế. SFT (Supervised Fine-Tuning - Tinh chỉnh có giám sát) sử dụng bốn nhóm bộ dữ liệu chuẩn; RL (Reinforcement Learning - Học tăng cường) chỉ sử dụng SEC. Trên các tác vụ thuộc nhóm nguồn đó, Harness-1 đã tăng 7,9 điểm so với đường cơ sở mở gần nhất. Trên bốn bộ dữ liệu chuẩn được giữ lại, nó đã tăng 17,0 điểm. Đây là mức tăng gấp 2,2 lần trên các tác vụ xa nhất so với dữ liệu huấn luyện.
Các thử nghiệm cắt bỏ hỗ trợ cho tuyên bố về hệ thống Harness. Việc vô hiệu hóa tất cả các cơ chế của hệ thống Harness làm giảm khả năng truy hồi 12,2% tương đối trên BrowseComp+. Chính sách đã được huấn luyện tiếp tục tìm kiếm nhưng không thể xếp hạng những gì nó thấy.
https://arxiv.org/pdf/2606.02373
Các trường hợp sử dụng
Phương pháp này nhắm đến việc truy xuất tìm kiếm bằng chứng, nơi các tài liệu hỗ trợ một câu trả lời. Một số quy trình làm việc phù hợp với hình thức này.
Một là xem xét tài liệu và bằng sáng chế. Biểu đồ bằng chứng và tập hợp được chọn lọc giúp tổ chức nhiều nguồn. Một trường hợp khác là phân tích hồ sơ tài chính. Nghiên cứu điển hình về SEC đã khôi phục chính xác ngày chuyển giao điều hành trên nhiều báo cáo 8-K.
Thứ ba là kiểm tra thực tế đa bước. Các công cụ fan_out_search và verify giải quyết các thực thể mơ hồ trước khi cam kết. Thứ tư là RAG (Retrieval-Augmented Generation - Tạo sinh tăng cường truy xuất) mô-đun. Tập hợp được chọn lọc cung cấp dữ liệu cho một bộ tạo sinh cố định, và các tập hợp tốt hơn mang lại độ chính xác câu trả lời cao hơn.
Điểm mạnh và điểm yếu
Điểm mạnh
Khả năng truy hồi được chọn lọc trung bình cao nhất trong số các mô hình mở được thử nghiệm, và chỉ đứng sau Opus-4.6 nói chung.
Mức tăng được duy trì trên các bộ dữ liệu chuẩn được giữ lại, cho thấy hoạt động tìm kiếm tổng quát theo miền.
Nguồn tin: MarkTechPost — Tác giả: Asif Razzaq. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.