Giải mã suy đoán là một kỹ thuật nhằm tăng tốc suy luận mô hình ngôn ngữ lớn. Một mô hình nháp nhỏ, nhanh sẽ đề xuất một số token. Mô hình đích lớn sẽ xác minh chúng song song. Nếu được chấp nhận, quá trình suy luận sẽ nhanh hơn. Nếu bị từ chối, hệ thống sẽ quay lại trạng thái ban đầu một cách linh hoạt.
Nhóm EAGLE, nhóm vLLM và nhóm TorchSpec đã ra mắt dòng sản phẩm EAGLE bao gồm EAGLE 1, EAGLE 2 và EAGLE 3, trở thành một trong những dòng thuật toán giải mã suy đoán được áp dụng và triển khai thực tế rộng rãi nhất trên cả hệ thống nghiên cứu và sản xuất. Hôm nay, dòng sản phẩm đó nhận được một bản nâng cấp độ tin cậy có mục tiêu với sự ra mắt của
Giải mã suy đoán là một kỹ thuật nhằm tăng tốc suy luận mô hình ngôn ngữ lớn (LLM). Một mô hình nháp nhỏ, nhanh sẽ đề xuất một số mã thông báo. Mô hình đích lớn sẽ xác minh chúng song song. Nếu được chấp nhận, suy luận sẽ nhanh hơn. Nếu bị từ chối, hệ thống sẽ tự động quay về trạng thái ban đầu.
Nhóm EAGLE, Nhóm vLLM và Nhóm TorchSpec đã ra mắt dòng sản phẩm EAGLE bao gồm EAGLE 1, EAGLE 2 và EAGLE 3, trở thành một trong những dòng thuật toán giải mã suy đoán được áp dụng và triển khai rộng rãi nhất trong cả hệ thống nghiên cứu và sản xuất. Hôm nay, dòng sản phẩm này được nâng cấp độ tin cậy với việc giới thiệu EAGLE 3.1.
Những vấn đề đã xảy ra
Mặc dù giải mã suy đoán hoạt động tốt trong các cài đặt được kiểm soát, hiệu suất thường suy giảm trong các mẫu trò chuyện khác nhau, đầu vào ngữ cảnh dài hoặc lời nhắc hệ thống nằm ngoài phân phối.
Nhóm EAGLE đã truy tìm nguyên nhân của sự yếu kém này đến một hiện tượng gọi là trôi dạt chú ý: khi độ sâu suy đoán tăng lên, mô hình nháp dần chuyển sự chú ý khỏi các mã thông báo chìm và hướng tới các mã thông báo do chính nó tạo ra.
Nói một cách đơn giản hơn: mô hình nháp là một mô hình nhỏ dự đoán các mã thông báo trong tương lai. Khi suy đoán trở nên sâu hơn, nó bắt đầu chú ý đến các đầu ra trước đó của chính nó thay vì ngữ cảnh ban đầu. Điều này làm giảm độ dài chấp nhận và sự ổn định của đầu ra.
Hai vấn đề cơ bản đã được xác định. Thứ nhất, biểu diễn đầu vào hợp nhất ngày càng trở nên mất cân bằng khi các trạng thái ẩn lớp cao hơn chi phối đầu vào của mô hình nháp. Thứ hai, độ lớn trạng thái ẩn tăng lên qua các bước suy đoán do đường dẫn dư không được chuẩn hóa. Cùng với nhau, những hiệu ứng này làm cho mô hình nháp ngày càng kém ổn định ở độ sâu suy đoán sâu hơn.
Hai bản sửa lỗi kiến trúc trong EAGLE 3.1
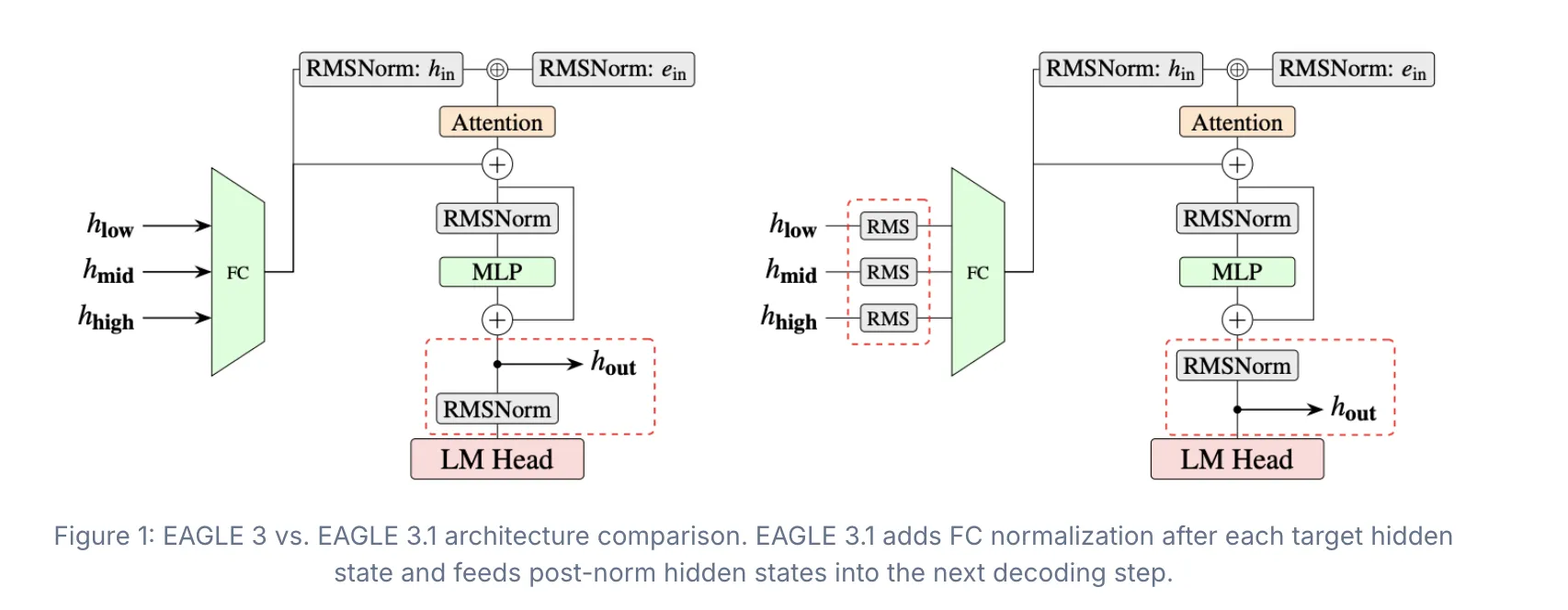
Để giải quyết vấn đề trôi dạt chú ý, EAGLE 3.1 đi kèm với hai cải tiến kiến trúc chính: chuẩn hóa FC sau mỗi trạng thái ẩn đích và trước lớp FC, và đưa các trạng thái ẩn sau chuẩn hóa vào bước giải mã tiếp theo.
Chuẩn hóa FC ổn định các trạng thái ẩn mà mô hình nháp nhận được từ mô hình đích. Nếu không có nó, độ lớn trạng thái ẩn sẽ tăng lên qua các bước, làm cho mô hình nháp ngày càng không đáng tin cậy. Áp dụng chuẩn hóa ở mỗi bước giúp giữ cho các đầu vào được giới hạn.
Thiết kế sau chuẩn hóa làm cho phương pháp hoạt động giống như việc gọi đệ quy mô hình nháp qua các bước giải mã, thay vì chỉ đơn giản là thêm các lớp bổ sung vào mô hình đích.
https://vllm.ai/blog/2026-05-26-eagle-3-1
Những cải tiến này mang lại gì
So với EAGLE 3, EAGLE 3.1 thể hiện: khả năng ngoại suy tốt hơn từ thời gian huấn luyện đến thời gian suy luận, khả năng chịu đựng ngữ cảnh dài mạnh mẽ hơn, khả năng phục hồi cao hơn đối với các biến thể mẫu trò chuyện và lời nhắc hệ thống, và độ dài chấp nhận ổn định hơn trong các môi trường phục vụ đa dạng.
Trong các tác vụ ngữ cảnh dài, EAGLE 3.1 đạt độ dài chấp nhận dài hơn gấp 2 lần so với EAGLE 3.
Cơ sở hạ tầng huấn luyện: TorchSpec
TorchSpec hiện cung cấp hỗ trợ huấn luyện hiệu quả cho EAGLE 3.1 và các thuật toán giải mã suy đoán trong tương lai. Bằng cách giảm chi phí huấn luyện và đơn giản hóa quy trình thử nghiệm, TorchSpec giúp tăng tốc lặp lại và khám phá cho nghiên cứu và triển khai giải mã suy đoán thế hệ tiếp theo.
Dựa trên TorchSpec và vLLM, nhóm nghiên cứu cũng đã huấn luyện và công khai một mô hình nháp EAGLE 3.1 cho Kimi K2.6, có sẵn trên HuggingFace. Mô hình này đóng vai trò là một ví dụ về việc triển khai EAGLE 3.1 với hỗ trợ huấn luyện TorchSpec và phục vụ vLLM trên một mô hình phục vụ thực tế.
Tích hợp vLLM: Theo cấu hình và tương thích ngược.
EAGLE 3.1 được tích hợp vào vLLM dưới dạng một tiện ích mở rộng cấu hình của triển khai EAGLE 3 hiện có. Việc tích hợp này bao gồm hỗ trợ chuẩn hóa FC, phản hồi trạng thái ẩn sau chuẩn hóa và loại bỏ các giả định được mã hóa cứng liên quan đến các trạng thái ẩn mục tiêu.
Khả năng tương thích ngược với các điểm kiểm tra EAGLE 3 hiện có được bảo toàn hoàn toàn. Các mô hình nháp EAGLE 3.1 có thể được cắm trực tiếp thông qua cùng một đường dẫn mã giải mã suy đoán.
Sao chép mã đã sao chép Sử dụng trình duyệt khác
vllm serve nvidia/Kimi-K2.6-NVFP4 \
--trust-remote-code \
--tensor-parallel-size 4 \
--tool-call-parser kimi_k2 \
--enable-auto-tool-choice \
--reasoning-parser kimi_k2 \
--attention-backend tokenspeed_mla \
--speculative-config '{"model":"lightseekorg/kimi-k2.6-eagle3.1-mla","method":"eagle3","num_speculative_tokens":3}' \
--language-model-only
Kết quả đánh giá trên Kimi K2.6
Nhóm nghiên cứu đã đánh giá mô hình nháp Kimi K2.6 EAGLE 3.1 trên Kimi-K2.6-NVFP4 với vLLM (TP=4, GB200, không phân tách) trên bộ dữ liệu mã hóa SPEED-Bench. EAGLE 3.1 mang lại thông lượng đầu ra trên mỗi người dùng cao hơn 2,03 lần ở mức đồng thời 1. Tốc độ tăng vẫn đáng kể khi mức độ đồng thời tăng lên: 1,71 lần ở C=4 và 1,66 lần ở C=16.
Giải thích trực quan của Marktechpost
01 / 07
vLLM · ngày 26/5/2026
Giới thiệu EAGLE 3.1
Nhóm EAGLE, nhóm vLLM và nhóm TorchSpec đã cùng phát hành EAGLE 3.1 — một bản sửa lỗi có mục tiêu cho sự bất ổn định của giải mã suy đoán trong việc phục vụ LLM sản xuất.
#giải mã suy đoán
#vLLM
#suy luận LLM
#hiệu suất
02 / 07
Bối cảnh
Giải mã suy đoán là gì?
Một kỹ thuật để tăng tốc suy luận LLM bằng cách sử dụng hai mô hình hoạt động cùng nhau.
Một mô hình nháp nhỏ, nhanh chóng đề xuất một số mã thông báo trước
Mô hình mục tiêu lớn xác minh tất cả các mã thông báo được đề xuất trong một lần
Các mã thông báo được chấp nhận được giữ lại — các mã thông báo bị từ chối sẽ được xử lý một cách linh hoạt
Kết quả: thông lượng đầu ra cao hơn mà không thay đổi chất lượng đầu ra
03 / 07
Vấn đề
Trôi lệch chú ý trong EAGLE 3
Hiệu suất của EAGLE 3 suy giảm trong các triển khai thực tế trong ba điều kiện:
Các mẫu trò chuyện khác nhau
Đầu vào ngữ cảnh dài
Các lời nhắc hệ thống ngoài phân phối
Nguyên nhân gốc rễ: trôi lệch chú ý — khi độ sâu suy đoán tăng lên, người soạn thảo chuyển sự chú ý khỏi các mã thông báo chìm sang các mã thông báo do chính nó tạo ra.
04 / 07
Nguyên nhân gốc rễ
Hai vấn đề cơ bản
Biểu diễn đầu vào hợp nhất ngày càng trở nên mất cân bằng — các trạng thái ẩn lớp cao hơn chiếm ưu thế trong đầu vào của người soạn thảo
Độ lớn trạng thái ẩn tăng lên qua các bước suy đoán do đường dẫn dư không được chuẩn hóa
Cùng với nhau, những điều này làm cho người soạn thảo ngày càng ít ổn định hơn
Nguồn tin: MarkTechPost — Tác giả: Michal Sutter. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.