Bạn nhập một tin nhắn vào Claude và một phản hồi xuất hiện trong vài giây. Điều này tạo cảm giác tức thời. Tuy nhiên, giữa thời điểm bạn nhấn Enter và từ đầu tiên được trả về, một chuỗi hoạt động chính xác và sâu sắc đáng ngạc nhiên đã diễn ra trên phần cứng chuyên dụng ở quy mô lớn. Thị trường suy luận AI toàn cầu được định giá 106,15 tỷ USD vào năm 2025 và dự kiến sẽ tăng lên 254,98 tỷ USD vào năm 2030 (MarketsandMarkets, 2025). Bài viết này sẽ đề cập đến những gì đang diễn ra bên trong thị trường đó – ở cấp độ của một yêu cầu đơn lẻ mà bạn gửi.
Chúng ta sẽ theo dõi lời nhắc của bạn từ văn bản thô đến các token được truyền tải, bao gồm quá trình token hóa,
Bạn nhập một tin nhắn vào Claude và một phản hồi xuất hiện trong vài giây. Điều này tạo cảm giác tức thì. Tuy nhiên, giữa thời điểm bạn nhấn Enter và từ đầu tiên được trả về, một chuỗi hoạt động chính xác và sâu sắc đáng ngạc nhiên đã diễn ra trên phần cứng chuyên dụng ở quy mô lớn. Thị trường suy luận AI toàn cầu được định giá 106,15 tỷ USD vào năm 2025 và dự kiến sẽ tăng lên 254,98 tỷ USD vào năm 2030 (MarketsandMarkets, 2025). Bài viết này đề cập đến những gì đang diễn ra bên trong thị trường đó – ở cấp độ một yêu cầu bạn gửi.
Chúng tôi sẽ theo dõi lời nhắc của bạn từ văn bản thô đến các token được truyền tải, bao gồm mã hóa token, cơ chế chú ý của transformer, thực thi GPU, phân tách prefill/decode và lý do chi phí năng lượng thay đổi đáng kể giữa các dòng mô hình. Không có sự mơ hồ. Không có hộp đen.
Những điểm chính cần lưu ý
Lời nhắc của bạn được chuyển đổi thành các token (khoảng 1 token cho mỗi 0,75 từ) trước khi mô hình "đọc" nó.
Suy luận chia thành hai giai đoạn: một giai đoạn prefill song song nhanh chóng, sau đó là giai đoạn decode tự hồi quy chậm hơn tạo ra từng token một.
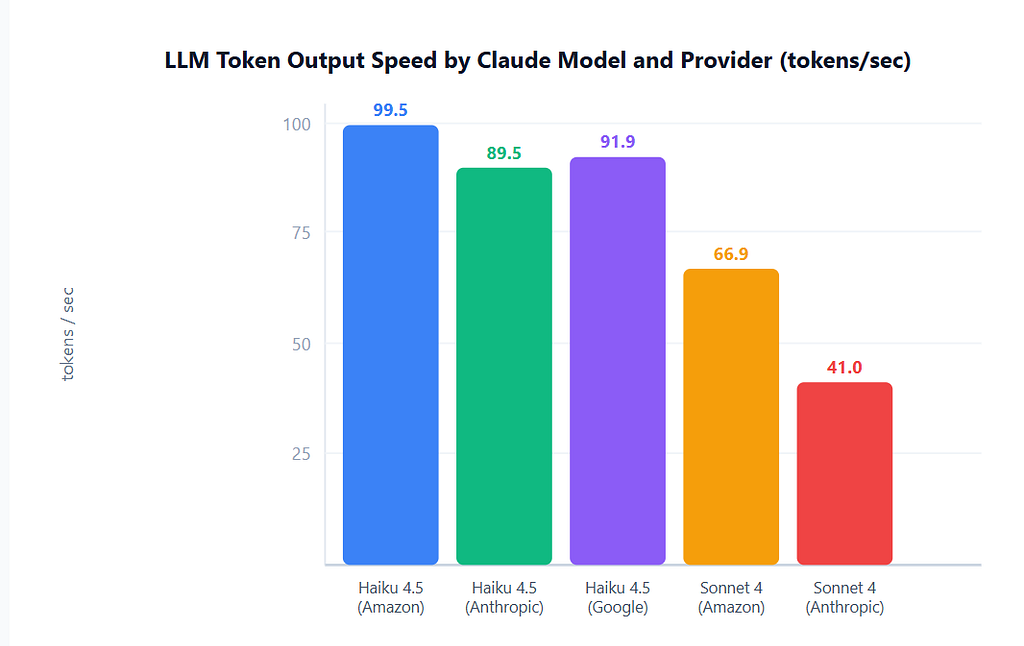
Claude 4.5 Haiku xuất ra tới 99,5 token/giây trên Amazon Bedrock, với thời gian phản hồi token đầu tiên thấp nhất là 0,58 giây (Artificial Analysis, 2025).
Các mô hình suy luận như o3 sử dụng năng lượng nhiều hơn tới 73 lần so với các mô hình nhẹ do các token chuỗi suy nghĩ ẩn.
Lượng tử hóa FP8 có thể giảm độ trễ suy luận 8,5% và tăng thông lượng 33% so với FP16.
Mã hóa token là gì và tại sao nó diễn ra trước tiên?
Trước khi một LLM đọc bất kỳ ký tự nào trong lời nhắc của bạn, nó sẽ chuyển đổi văn bản thô thành các token. Theo Anyscale (2024), một token tương đương khoảng 4 ký tự hoặc 0,75 từ trong tiếng Anh, nghĩa là một tài liệu 750 từ tương ứng với khoảng 1.000 token. Bước này là bắt buộc: lớp nhúng của mô hình chỉ chấp nhận ID số, không phải chuỗi. (Anyscale, 2024)
Cách bộ mã hóa token chia văn bản
Claude sử dụng bộ mã hóa token mã hóa cặp byte (BPE). Nó bắt đầu từ các ký tự riêng lẻ và hợp nhất các cặp liền kề thường xuyên nhất cho đến khi đạt đến kích thước từ vựng cố định, thường là 50.000 đến 200.000 token duy nhất. Các từ thông dụng như "the" trở thành các token đơn lẻ. Các từ hiếm như "tokenization" có thể chia thành hai hoặc ba. Mã đặc biệt dày đặc: một hàm Python đơn lẻ có thể tăng lên gấp 3 lần số token so với văn xuôi tương đương.
Tại sao điều này lại quan trọng trong thực tế? Hóa đơn API của bạn được tính theo token. Một lời nhắc được viết với sự dài dòng không cần thiết có thể tốn kém hơn 40–60% so với một lời nhắc tương đương ngắn gọn, chính xác. Đây không phải là một mối lo ngại nhỏ khi bạn thực hiện hàng nghìn yêu cầu mỗi ngày.
Từ ID token đến vector nhúng
Mỗi ID token được tra cứu trong một ma trận nhúng, một bảng khổng lồ trong đó mỗi mục từ vựng ánh xạ tới một vector gồm vài nghìn số dấu phẩy động. Đối với một mô hình 7B tham số, riêng lớp nhúng đó yêu cầu khoảng 14 GB bộ nhớ GPU để phục vụ (Anyscale, 2024). Các vector này mã hóa các mối quan hệ ngữ nghĩa: các token có ý nghĩa tương tự tập hợp gần nhau trong không gian đa chiều này.
Trong tiếng Anh, một token tương đương khoảng 4 ký tự hoặc 0,75 từ. Một tài liệu 750 từ tương đương khoảng 1.000 token, và một mô hình 7B tham số yêu cầu khoảng 14 GB bộ nhớ GPU để phục vụ các nhúng đó ở độ chính xác đầy đủ. (Anyscale, 2024) Tốc độ xuất token thay đổi đáng kể tùy theo nhà cung cấp và kích thước mô hình. Haiku trên Amazon Bedrock dẫn đầu với 99,5 token/giây. Nguồn: Artificial Analysis (2025). Cơ chế chú ý thực sự hoạt động như thế nào?
Cơ chế chú ý của transformer là cốt lõi kiến trúc giúp các LLM có khả năng vượt trội đáng kể so với các mô hình chuỗi cũ hơn. Nó cho phép mọi token trong y
FlashAttention 4 đạt thông lượng cao nhất 1.613 TFLOPs/s trên GPU NVIDIA B200 với mức sử dụng phần cứng 71%, mang lại tốc độ nhanh hơn tới 2,7 lần so với các nhân dựa trên Triton trước đây (Lambda AI, 2026). Tốc độ này rất quan trọng khi xử lý hàng trăm nghìn token mỗi giây cho hàng nghìn người dùng.
Truy vấn (Queries), Khóa (Keys) và Giá trị (Values) – Không cần tính toán
Hãy hình dung mỗi token như một người trong phòng. Khi một token muốn "hiểu" ngữ cảnh của nó, nó sẽ phát đi một truy vấn: "tôi cần thông tin gì?". Mọi token khác sẽ giơ lên một khóa – một tín hiệu mô tả nội dung mà nó chứa. Nếu truy vấn và khóa khớp tốt, token đó sẽ thu thập giá trị của token kia – thông tin thực tế mà nó mang. Quá trình này diễn ra song song trên mọi cặp token trong chuỗi, sau đó trên nhiều "đầu" (heads) cùng lúc.
Mỗi đầu chú ý (attention head) học các loại mối quan hệ khác nhau trong quá trình huấn luyện. Một đầu có thể chuyên theo dõi các tham chiếu đại từ. Một đầu khác có thể liên kết động từ với chủ ngữ của chúng qua khoảng cách dài. Cùng với nhau, các đầu này mang lại cho mô hình một cái nhìn phong phú, đa chiều về cấu trúc của lời nhắc (prompt) của bạn.
Bộ nhớ đệm KV (KV Cache) và lý do tồn tại
Việc tính toán lại sự chú ý cho mọi token đã được tạo trước đó ở mỗi bước giải mã mới sẽ cực kỳ chậm. Bộ nhớ đệm khóa-giá trị lưu trữ các tensor K và V đã được tính toán cho tất cả các token lời nhắc sau giai đoạn tiền xử lý (prefill). Trong quá trình giải mã (decode), chỉ token mới được tạo ra cần tính toán mới. Bộ nhớ đệm là yếu tố giúp các phản hồi trực tuyến (streaming responses) có cảm giác nhanh chóng – nhưng nó cũng tiêu thụ đáng kể bộ nhớ GPU, đặc biệt đối với các ngữ cảnh dài và kích thước lô (batch sizes) lớn.
FlashAttention-4 đạt thông lượng cao nhất 1.613 TFLOPs/s trên GPU NVIDIA B200 với mức sử dụng phần cứng 71%, mang lại tốc độ nhanh hơn tới 2,7 lần so với các nhân chú ý dựa trên Triton. Điều này trực tiếp giảm chi phí tính toán khi xử lý các lời nhắc có ngữ cảnh dài. Tiền xử lý (Prefill) so với Giải mã (Decode): Hai giai đoạn của suy luận LLM
Mỗi yêu cầu suy luận có hai giai đoạn riêng biệt, và chúng có các đặc điểm hiệu suất rất khác nhau. Giai đoạn tiền xử lý xử lý toàn bộ lời nhắc của bạn trong một lần chuyển tiếp – nó bị giới hạn bởi tính toán và hưởng lợi từ tính song song. Giai đoạn giải mã tạo ra một token tại một thời điểm và bị giới hạn bởi băng thông bộ nhớ. Claude 4.5 Haiku đạt thời gian đến token đầu tiên (TTFT) thấp tới 0,58 giây trên Google Vertex AI, phản ánh việc thực thi tiền xử lý nhanh chóng (Artificial Analysis, 2025).
Điều gì xảy ra trong quá trình tiền xử lý
Trong quá trình tiền xử lý, mô hình đọc toàn bộ lời nhắc của bạn cùng lúc. Tất cả các token được xử lý trong một lần.
Nguồn tin: Medium Towards AI — Tác giả: Muhammed Mukthar. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.