Cohere đã phát hành Command A+: một mô hình MoE (Mixture of Experts) thưa thớt 218B dành cho các quy trình công việc tác nhân, có thể chạy trên tối thiểu hai GPU H100.
Cohere vừa phát hành Command A+, một mô hình mã nguồn mở hướng đến các quy trình tác nhân (agentic workflows) của doanh nghiệp. Có sẵn theo giấy phép Apache 2.0, Command A+ là một mô hình hỗn hợp chuyên gia (MoE) được xây dựng cho các tác vụ tác nhân hiệu suất cao với chi phí tính toán tối thiểu. Mô hình được tối ưu hóa cho suy luận, quy trình tác nhân, RAG (Retrieval Augmented Generation), xử lý tài liệu đa ngôn ngữ và đa phương thức. Nó hợp nhất các khả năng từ bốn mô hình trước đó — Command A, Command A Reasoning, Command A Vision và Command A Translate — thành một mô hình có khả năng mở rộng duy nhất.
Kiến trúc
Command A+ là một mô hình Transformer chỉ có bộ giải mã (decoder-only) dạng Hỗn hợp chuyên gia thưa thớt (Sparse Mixture-of-Experts).
Cohere vừa phát hành Command A+, một mô hình mã nguồn mở hướng tới các quy trình làm việc tác nhân (agentic workflows) của doanh nghiệp. Có sẵn theo giấy phép Apache 2.0, Command A+ là một mô hình hỗn hợp chuyên gia (MoE) được xây dựng cho các tác vụ tác nhân hiệu suất cao với chi phí tính toán tối thiểu. Mô hình được tối ưu hóa cho suy luận, quy trình làm việc tác nhân, RAG, xử lý tài liệu đa ngôn ngữ và đa phương thức. Nó hợp nhất các khả năng từ bốn mô hình trước đó — Command A, Command A Reasoning, Command A Vision và Command A Translate — thành một mô hình có khả năng mở rộng duy nhất.
Kiến trúc
Command A+ là một Transformer giải mã duy nhất (decoder-only) Hỗn hợp chuyên gia thưa thớt (Sparse Mixture-of-Experts) với tổng cộng 218 tỷ tham số và 25 tỷ tham số hoạt động. Nó có 128 chuyên gia, trong đó 8 chuyên gia hoạt động trên mỗi token, và một chuyên gia chia sẻ duy nhất được áp dụng cho tất cả các token. Trong một mô hình MoE, mỗi token chỉ được định tuyến qua một tập hợp con các mạng con chuyên gia thay vì toàn bộ tập hợp tham số, giữ cho tính toán hoạt động ở quy mô 25 tỷ tham số tại thời điểm suy luận.
Các lớp chú ý xen kẽ các lớp chú ý cửa sổ trượt với Nhúng vị trí quay (Rotational Positional Embeddings) và các lớp chú ý toàn cục không có nhúng vị trí theo tỷ lệ 3:1. Lớp MoE thưa thớt được huấn luyện theo cách không mất mát hoàn toàn và sử dụng bộ định tuyến lựa chọn token, với một sigmoid chuẩn hóa trên các logit chuyên gia top-k trên mỗi token.
Các phương thức đầu vào là văn bản, hình ảnh và sử dụng công cụ. Các phương thức đầu ra là văn bản, suy luận và sử dụng công cụ. Mô hình hỗ trợ độ dài ngữ cảnh đầu vào 128K và độ dài tạo tối đa 64K.
Yêu cầu phần cứng và lượng tử hóa
Ba biến thể lượng tử hóa có sẵn với yêu cầu GPU tối thiểu: BF16 (16-bit) yêu cầu 4 GPU B200 hoặc 8 GPU H100; FP8 (8-bit) yêu cầu 2 GPU B200 hoặc 4 GPU H100; W4A4 (4-bit) chạy trên một GPU B200 hoặc 2 GPU H100. Cả ba lượng tử hóa đều cho thấy sự khác biệt không đáng kể về chất lượng điểm chuẩn. Cohere khuyến nghị W4A4 cho hầu hết các triển khai.
Phương pháp lượng tử hóa W4A4
Cohere áp dụng lượng tử hóa NVFP4 W4A4, trọng số và kích hoạt 4-bit với chia tỷ lệ hai cấp, chỉ cho các chuyên gia MoE. Đường dẫn chú ý, bao gồm các phép chiếu Q/K/V/O, bộ nhớ đệm KV và tính toán chú ý, được giữ ở độ chính xác đầy đủ.
Để khắc phục các khoảng trống chất lượng còn lại, Cohere sử dụng Lượng tử hóa nhận biết chưng cất (QAD) trong giai đoạn sau huấn luyện: mô hình học sinh lượng tử hóa được huấn luyện để khớp với phân phối đầu ra của mô hình giáo viên độ chính xác đầy đủ, sử dụng các toán tử lượng tử hóa giả trong quá trình chuyển tiếp và các ước tính thẳng qua trong quá trình chuyển ngược.
https://cohere.com/blog/command-a-plus
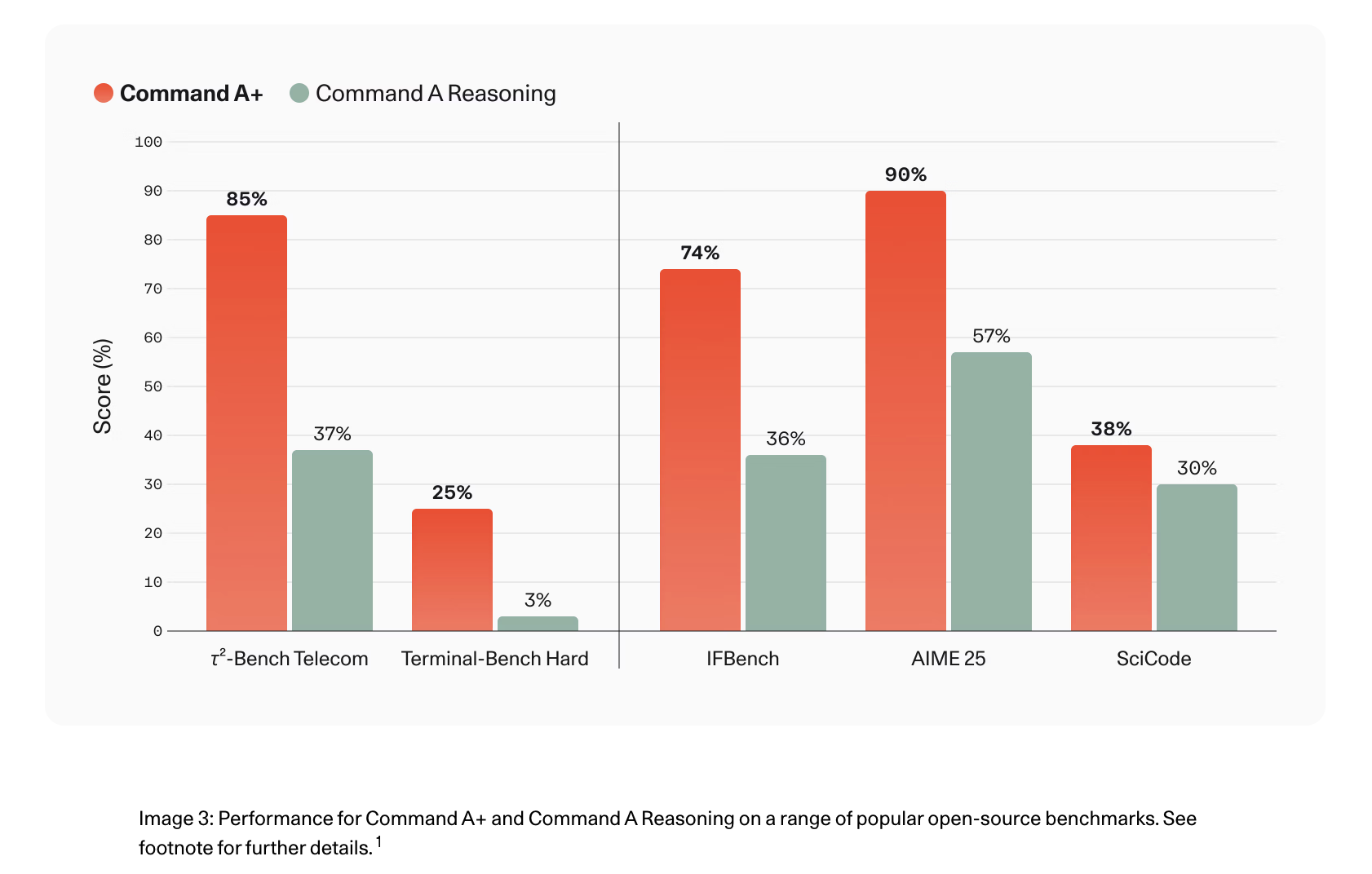
Hiệu suất so với các mô hình Command A trước đây
Trên τ²-Bench Telecom, điểm số đã cải thiện từ 37% lên 85% so với Command A Reasoning, và hiệu suất mã hóa tác nhân Terminal-Bench Hard đạt 25% từ 3%.
Trong các đánh giá nền tảng nội bộ của North, tất cả đều được chấm điểm bằng kỹ thuật LLM-as-a-judge, độ chính xác của Trả lời câu hỏi tác nhân (Agentic Question Answering) đã cải thiện 20% so với Command A Reasoning. Agentic QA đo lường mức độ mô hình trả lời tốt các câu hỏi của doanh nghiệp bằng cách sử dụng hệ thống tệp đám mây được kết nối MCP. Chất lượng phân tích bảng tính đã cải thiện 32%, và Chất lượng sử dụng bộ nhớ — đo lường mức độ một tác nhân tận dụng thông tin từ một phiên trước đó để trả lời các câu hỏi trong một phiên tiếp theo — đạt 54% với Command A+ so với 39% với Command A Reasoning.
Command A+ là mô hình suy luận đa phương thức đầu tiên của Cohere. Nó đạt 63% trên MMMU Pro và 75,1% trên MMMU, so với 65,3% của Command A Vision trên MMMU. Điểm MathVista đã cải thiện từ 73,5% lên 80,6%, và suy luận CharXiv đã cải thiện từ 46,9% lên 52,7%.
Command A+ mở rộng phạm vi hỗ trợ đa ngôn ngữ từ 23 lên 48 ngôn ngữ, với những cải tiến trong dịch máy và suy luận đa ngôn ngữ.
Command A+ đạt 37 điểm trên Chỉ số Trí tuệ Phân tích Nhân tạo (Artificial Analysis Intelligence Index), vượt trội so với các mô hình mã nguồn mở hàng đầu khác.
https://cohere.com/blog/command-a-plus
https://cohere.com/blog/command-a-plus
Tốc độ và Độ trễ
Ở cùng mức lượng tử hóa và mức độ đồng thời, Command A+ mang lại số lượng mã thông báo đầu ra mỗi giây (Output Tokens per Second - TOPS) cao hơn tới 63% và giảm thời gian đến mã thông báo đầu tiên (Time To First Token - TTFT) tới 17% so với Command A Reasoning. Lượng tử hóa W4A4 góp phần tăng thêm 47% tốc độ và giảm 13% độ trễ. Giải mã suy đoán, được tối ưu hóa đặc biệt cho kiến trúc MoE (Mixture of Experts), mang lại tốc độ suy luận tăng thêm 1,5–1,6 lần cho cả đầu vào văn bản và đa phương thức.
Bộ mã hóa (Tokenizer)
Command A+ là mô hình đầu tiên sử dụng bộ mã hóa mới nhất của Cohere, giảm số lượng mã thông báo cần thiết để tạo ra cùng một phản hồi. Hiệu quả mã hóa được cải thiện 20% đối với tiếng Ả Rập, 16% đối với tiếng Hàn và 18% đối với tiếng Nhật.
Bắt đầu
Mô hình được hỗ trợ bởi vLLM và Transformers. Việc sử dụng công cụ được xử lý thông qua các mẫu trò chuyện trong Transformers bằng cách sử dụng lược đồ JSON cho các mô tả công cụ. Khi tính năng suy luận được bật, mô hình sẽ tạo ra các dấu vết suy nghĩ giữa các thẻ <|START_THINKING|> và <|END_THINKING|> trước khi đưa ra câu trả lời cuối cùng.
Biến thể W4A4 yêu cầu vLLM ≥0.21.0 và cohere_melody>=0.9.0 để phân tích phản hồi chính xác. Cohere khuyến nghị các tham số lấy mẫu sau: temperature=0.9, top_p=0.95 và repetition_penalty=1.04.
Những điểm chính
Command A+ có tổng cộng 218 tỷ / 25 tỷ tham số hoạt động trong kiến trúc Sparse MoE, được phát hành theo giấy phép Apache 2.0.
W4A4 áp dụng lượng tử hóa NVFP4 chỉ cho các chuyên gia MoE với QAD sau huấn luyện, chạy trên 2× H100.
τ²-Bench Telecom cải thiện từ 37% lên 85%; Terminal-Bench Hard từ 3% lên 25% so với Command A Reasoning.
TOPS tăng tới 63% và TTFT giảm tới 17% so với Command A Reasoning ở mức lượng tử hóa tương ứng.
Command A+ là mô hình suy luận đa phương thức đầu tiên của Cohere, mở rộng hỗ trợ ngôn ngữ từ 23 lên 48 ngôn ngữ.
Xem chi tiết về Trọng số mô hình và chi tiết kỹ thuật. Ngoài ra, hãy theo dõi chúng tôi trên Twitter và đừng quên tham gia Cộng đồng ML SubReddit hơn 150 nghìn thành viên của chúng tôi và Đăng ký nhận Bản tin của chúng tôi. Bạn có dùng Telegram không? Giờ đây bạn cũng có thể tham gia cùng chúng tôi trên Telegram.
Cần hợp tác với chúng tôi để quảng bá Kho lưu trữ GitHub HOẶC Trang Hugging Face HOẶC Phát hành sản phẩm HOẶC Hội thảo trên web, v.v.? Hãy liên hệ với chúng tôi.
Bài viết Cohere phát hành Command A+: Một mô hình 218B
Nguồn tin: MarkTechPost — Tác giả: Michal Sutter. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.