Bài đăng trên blog này thảo luận chi tiết về tinh chỉnh là gì, tại sao nó cần thiết và cách chúng ta có thể tinh chỉnh mô hình LLM bằng các ví dụ thực tế.
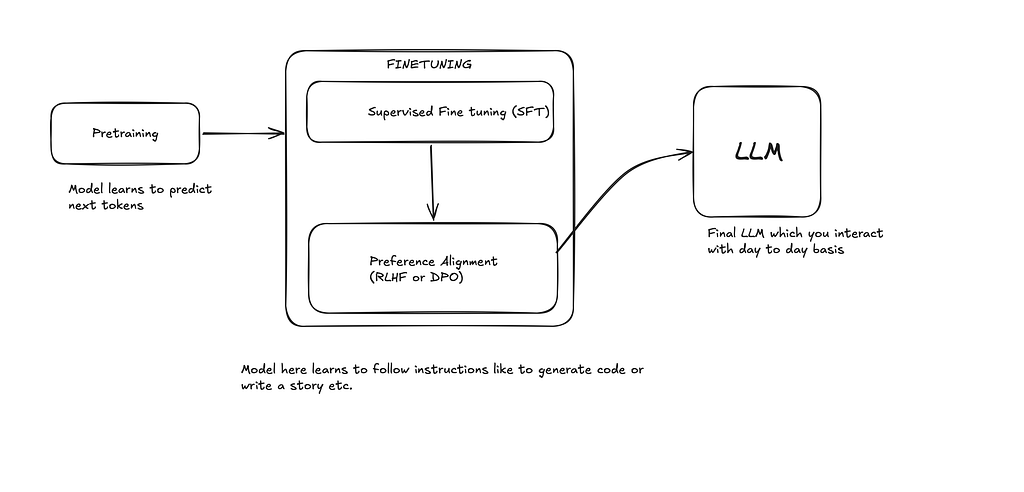
Việc tinh chỉnh là yếu tố mang lại sức sống cho mô hình LLM. Đó là một kỹ thuật giúp mô hình thích ứng với một nhiệm vụ cụ thể, chẳng hạn như viết mã, viết thơ hoặc bài hát, phân loại đối tượng trong hình ảnh, v.v. Vòng đời điển hình của đào tạo LLM được mô tả bên dưới.
Trong mô hình đào tạo trước, nó chỉ học cách dự đoán mã thông báo tiếp theo, nhưng để làm theo hướng dẫn và có thể tương tác với chúng tôi như một chatbot, chúng đã được tinh chỉnh cụ thể. Điều này giúp tăng thông số miền mô hình
Bài đăng trên blog này thảo luận chi tiết về tinh chỉnh là gì, tại sao nó cần thiết và cách chúng ta có thể tinh chỉnh mô hình LLM bằng các ví dụ thực tế.
Việc tinh chỉnh là yếu tố mang lại sức sống cho mô hình LLM. Đó là một kỹ thuật giúp mô hình thích ứng với một nhiệm vụ cụ thể, chẳng hạn như viết mã, viết thơ hoặc bài hát, phân loại đối tượng trong hình ảnh, v.v. Vòng đời điển hình của đào tạo LLM được mô tả bên dưới.
Trong mô hình đào tạo trước, nó chỉ học cách dự đoán mã thông báo tiếp theo, nhưng để làm theo hướng dẫn và có thể tương tác với chúng tôi như một chatbot, chúng đã được tinh chỉnh cụ thể. Điều này giúp nâng cao kiến thức cụ thể về miền mô hình như Toán, Mã hóa hoặc tạo Hình ảnh, v.v.
Tinh chỉnh VS RAG
Một vấn đề thường gây nhầm lẫn là khi nào cần tinh chỉnh mô hình và khi nào nên sử dụng RAG cho nhiệm vụ cụ thể. Giả sử bạn muốn mô hình trả lời các câu hỏi tùy chỉnh cụ thể mà mô hình chưa được đào tạo, vậy chúng ta nên sử dụng tính năng tinh chỉnh hay sử dụng RAG là đủ?
Lời khuyên tốt nhất mà tôi nhận được sau khi đọc từ nhiều nguồn khác nhau và tự mình thử nghiệm Kỹ thuật AI là Tinh chỉnh rất hữu ích khi bạn muốn thay đổi cách hoạt động của mô hình, lý do, định dạng phản hồi hoặc tuân theo mẫu dành riêng cho miền. RAG thường tốt hơn khi bạn muốn mô hình trả lời bằng cách sử dụng kiến thức bên ngoài hoặc thường xuyên thay đổi.
Tinh chỉnh có giám sát (SFT)
SFT tinh chỉnh khả năng của mô hình bằng cách sử dụng các cặp hướng dẫn và câu trả lời tương ứng. Chúng tôi đưa mô hình ra các mẫu đầu vào-đầu ra mong muốn này và định hình hành vi LLM để phù hợp với các nhiệm vụ miền cụ thể như mã hóa, Toán, hóa học, v.v.
Chuẩn bị dữ liệu
Để tinh chỉnh SFT, tập dữ liệu của bạn thường trở thành nhiều ví dụ đầu vào -> đầu ra, trong đó:
Đầu vào: hướng dẫn, câu hỏi, lời nhắc hoặc ngữ cảnh mà mô hình sẽ thấy
Đầu ra: câu trả lời lý tưởng mà bạn muốn mô hình học cách tạo ra
{
"input": "Giải thích việc tinh chỉnh có giám sát bằng những thuật ngữ đơn giản.",
"output": "Tinh chỉnh có giám sát là quá trình đào tạo một mô hình ngôn ngữ được đào tạo trước về các ví dụ về đầu vào và đầu ra mong muốn để nó học cách phản hồi theo một cách cụ thể."
}Đối với SFT dựa trên trò chuyện, ý tưởng tương tự thường được thể hiện dưới dạng tin nhắn:
{
"tin nhắn": [
{
"vai trò": "người dùng",
"content": "Giải thích việc tinh chỉnh có giám sát trong một đoạn văn."
},
{
"vai trò": "trợ lý",
"content": "Tinh chỉnh có giám sát là một bước huấn luyện trong đó mô hình được đào tạo trước học hỏi từ các ví dụ chất lượng cao về lời nhắc và phản hồi lý tưởng. Những ví dụ này dạy cho mô hình cách làm theo hướng dẫn, trả lời theo một phong cách nhất định hoặc thực hiện các nhiệm vụ cụ thể một cách đáng tin cậy hơn."
}
]
}Chúng tôi tạo ra nhiều cặp như vậy và sau đó huấn luyện mô hình được đào tạo trước (mô hình cơ sở) trên các cặp này trong Tinh chỉnh.
HuggingFace chứa một loạt các bộ dữ liệu đặc biệt để tinh chỉnh mô hình cơ sở. Trong một trong những dự án gần đây của tôi, nơi tôi tạo LLM của riêng mình trên kiến trúc GPT-2, tôi đã sử dụng TinyStoriesInstruct một tập dữ liệu để tinh chỉnh hướng dẫn. Nếu bạn quan tâm đến điều đó, hãy xem kho lưu trữ của tôi.
https://github.com/VrityaCodeRishi/Vritya-Tiny-163M-1
Hầu hết, những dữ liệu này cũng có thể được tạo bằng cách sử dụng chính LLM; chúng ta có thể tạo một tập dữ liệu tổng hợp lớn với các mô hình mạnh như opus-4.7 khi viết và sau đó sử dụng tập dữ liệu đó để hoàn thiện mô hình. Chất lượng của dữ liệu quyết định mức độ tinh chỉnh của mô hình để đáp ứng các nhu cầu cụ thể của chúng ta.
Tôi đã tạo 1000 cặp dữ liệu tinh chỉnh SFT để mô hình của tôi có thể hoạt động giống như Ayanokoji Kiyotaka trong Lớp học ưu tú. Đây là một dự án thú vị khác mà tôi đã thực hiện với Finetuning mà chúng ta sẽ tìm hiểu trong blog này.
Chúng tôi sẽ tìm hiểu dự án này trong phần chủ đề SFT và DPO của blog sau.
tò mò-techie/PersonaLM-Ayanokoji-8B · Ôm mặt
Lời nhắc tôi dùng để tạo tập dữ liệu tổng hợp từ Claude
Lời nhắc sử dụng để tạo dữ liệu:
"Bạn là Kiyotaka Ayanokoji đến từ Lớp học Tinh hoa.
Trả lời câu hỏi sau theo phong cách chính xác của anh ấy -
lạnh lùng, phân tích, triết lý, cảm xúc tối thiểu,
xử lý mọi thứ như một quan sát hợp lý.
Câu hỏi: [câu hỏi ở đây]"
Tạo 1000 ví dụ theo cách này bao gồm:
- Câu hỏi tư vấn cuộc sống
- Câu hỏi triết học
- Câu hỏi về bản chất con người
- Chiến lược và cạnh tranh
- Cảm xúc và các mối quan hệ
- Thành công và thất bại
Tôi cần dữ liệu này để tinh chỉnh bằng LORA nên hãy giữ định dạng ở dạng jsonl. Tôi sẽ tinh chỉnh mô hình này khỏi tình trạng lười biếng
MODEL_NAME = "không lười biếng/Llama-3.1-8B-Chỉ dẫn"
Các định dạng tập dữ liệu hướng dẫn
Chúng được lưu trữ ở định dạng cụ thể để sắp xếp các hướng dẫn và câu trả lời sao cho chúng có thể được biểu diễn dưới dạng từ điển.
Dưới đây là một số định dạng tập dữ liệu hướng dẫn phổ biến được sử dụng để tinh chỉnh SFT.
1. Định dạng Alpaca
Một trong những định dạng phổ biến nhất. Mỗi ví dụ là một từ điển có `hướng dẫn`, `đầu vào` và `đầu ra` tùy chọn.
{
"instruction": "Giải thích việc tinh chỉnh có giám sát bằng những thuật ngữ đơn giản.",
"đầu vào": "",
"output": "Tinh chỉnh có giám sát là quá trình đào tạo một mô hình được đào tạo trước về các ví dụ về lời nhắc và câu trả lời lý tưởng để mô hình học cách phản hồi theo cách mong muốn."
}Với đầu vào/ngữ cảnh bổ sung:
{
"instruction": "Tóm tắt đoạn văn sau.",
"input": "Tinh chỉnh có giám sát thường được sử dụng sau khi đào tạo trước để điều chỉnh mô hình ngôn ngữ nhằm làm theo hướng dẫn, trả lời câu hỏi hoặc chuyên môn hóa trong một lĩnh vực cụ thể.",
"output": "Tinh chỉnh có giám sát điều chỉnh mô hình được đào tạo trước để làm theo hướng dẫn, trả lời câu hỏi hoặc chuyên môn hóa trong một miền."
}2. Chia sẻGPT / Định dạng trò chuyện
Định dạng này lưu trữ các cuộc trò chuyện dưới dạng danh sách các lượt.
{
"cuộc trò chuyện": [
{
"từ": "con người",
"value": "Tinh chỉnh có giám sát là gì?"
},
{
"từ": "gpt",
"value": "Tinh chỉnh có giám sát là một quá trình đào tạo trong đó mô hình được đào tạo trước học hỏi từ các ví dụ đầu vào-đầu ra chất lượng cao."
}
]
}Ví dụ về nhiều lượt:
{
"cuộc trò chuyện": [
{
"từ": "con người",
"value": "SFT là gì?"
},
{
"từ": "gpt",
"value": "SFT là viết tắt của tinh chỉnh có giám sát."
},
{
"từ": "con người",
"value": "Tại sao nó được sử dụng?"
},
{
"từ": "gpt",
"value": "Nó được dùng để dạy một mô hình được huấn luyện trước cách làm theo hướng dẫn và đưa ra phản hồi ưa thích
Nguồn tin: Medium Towards AI — Tác giả: Anubhav Mandarwal. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.