Ahead of AI· Sebastian Raschka, PhD· 4/4/2026models
Trong bài viết này, tôi muốn đề cập đến thiết kế tổng thể của tác nhân mã hóa và khai thác tác nhân: chúng là gì, chúng hoạt động như thế nào và các phần khác nhau khớp với nhau như thế nào trong thực tế. Độc giả của các cuốn sách Xây dựng mô hình ngôn ngữ lớn (Từ đầu) và Xây dựng mô hình lý luận lớn (Từ đầu) của tôi thường hỏi về các tác nhân, vì vậy tôi nghĩ sẽ rất hữu ích nếu viết một tài liệu tham khảo mà tôi có thể chỉ ra.
Tổng quát hơn, các tác nhân đã trở thành một chủ đề quan trọng vì phần lớn tiến bộ gần đây trong các hệ thống LLM thực tế không chỉ là về các mô hình tốt hơn mà còn về cách chúng ta sử dụng chúng. Trong nhiều ứng dụng thực tế, surroun
Trong bài viết này, tôi muốn đề cập đến thiết kế tổng thể của tác nhân mã hóa và khai thác tác nhân: chúng là gì, chúng hoạt động như thế nào và các phần khác nhau khớp với nhau như thế nào trong thực tế. Độc giả của các cuốn sách Xây dựng mô hình ngôn ngữ lớn (Từ đầu) và Xây dựng mô hình lý luận lớn (Từ đầu) của tôi thường hỏi về các tác nhân, vì vậy tôi nghĩ sẽ rất hữu ích nếu viết một tài liệu tham khảo mà tôi có thể chỉ ra.
Tổng quát hơn, các tác nhân đã trở thành một chủ đề quan trọng vì phần lớn tiến bộ gần đây trong các hệ thống LLM thực tế không chỉ là về các mô hình tốt hơn mà còn về cách chúng ta sử dụng chúng. Trong nhiều ứng dụng trong thế giới thực, hệ thống xung quanh, chẳng hạn như sử dụng công cụ, quản lý bối cảnh và bộ nhớ, đóng vai trò quan trọng như chính mô hình đó. Điều này cũng giúp giải thích tại sao các hệ thống như Claude Code hoặc Codex có thể có khả năng hoạt động tốt hơn đáng kể so với các mô hình tương tự được sử dụng trong giao diện trò chuyện đơn giản.
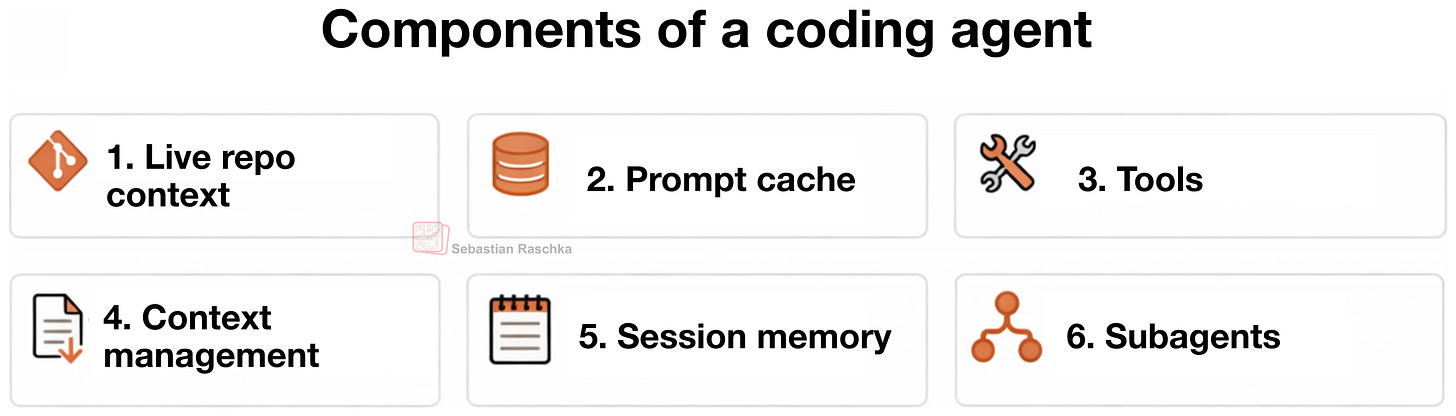
Trong bài viết này, tôi trình bày sáu khối xây dựng chính của một tác nhân mã hóa.
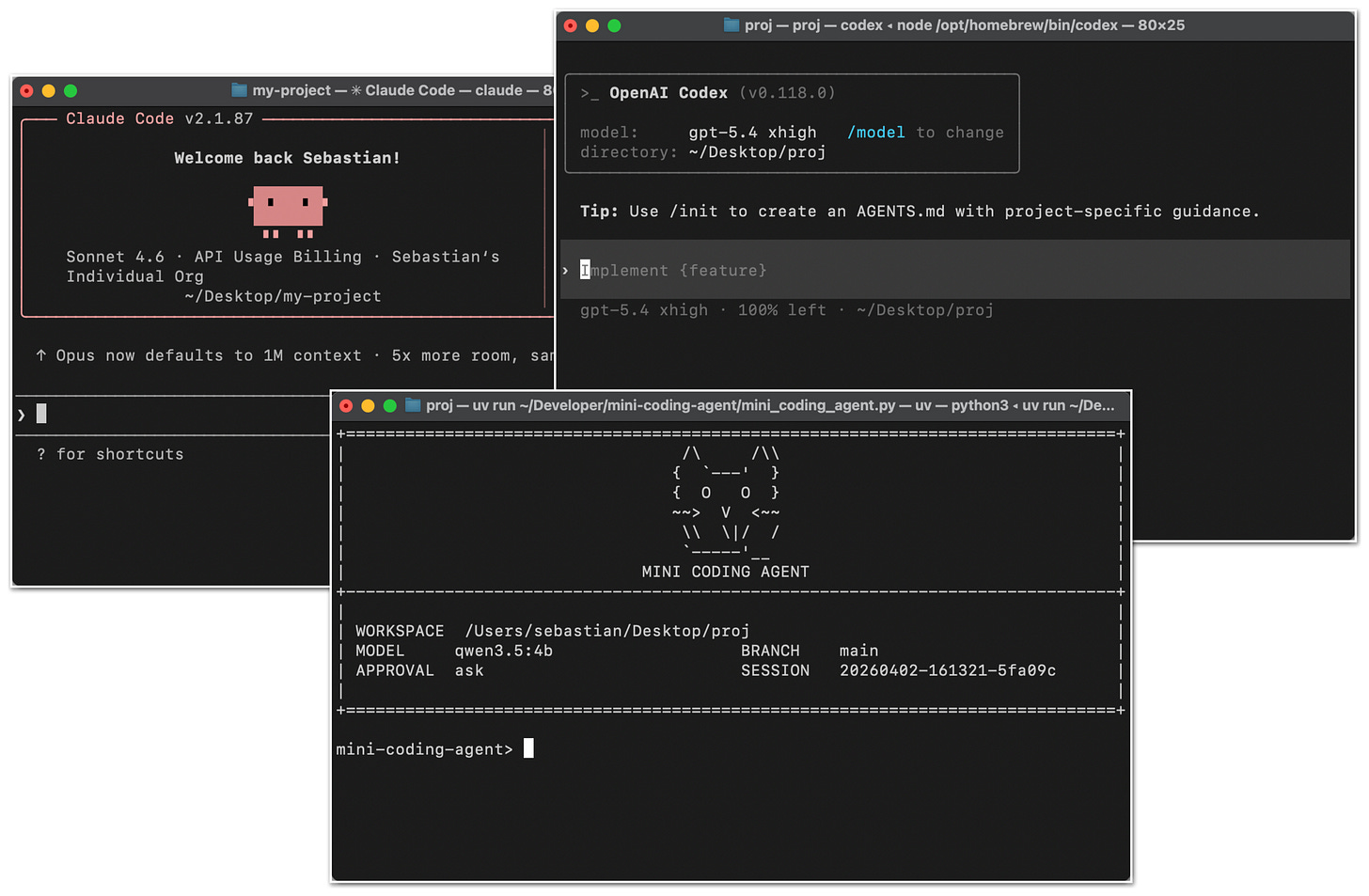
Claude Code, Codex CLI và các tác nhân mã hóa khác
Bạn có thể quen thuộc với Claude Code hoặc Codex CLI, nhưng chỉ để bắt đầu, về cơ bản, chúng là các công cụ mã hóa tác nhân bao bọc LLM trong một lớp ứng dụng, được gọi là khai thác tác nhân, để thuận tiện hơn và hoạt động tốt hơn cho các tác vụ mã hóa.
Hình 1: Claude Code CLI, Codex CLI và Tác nhân mã hóa mini của tôi.
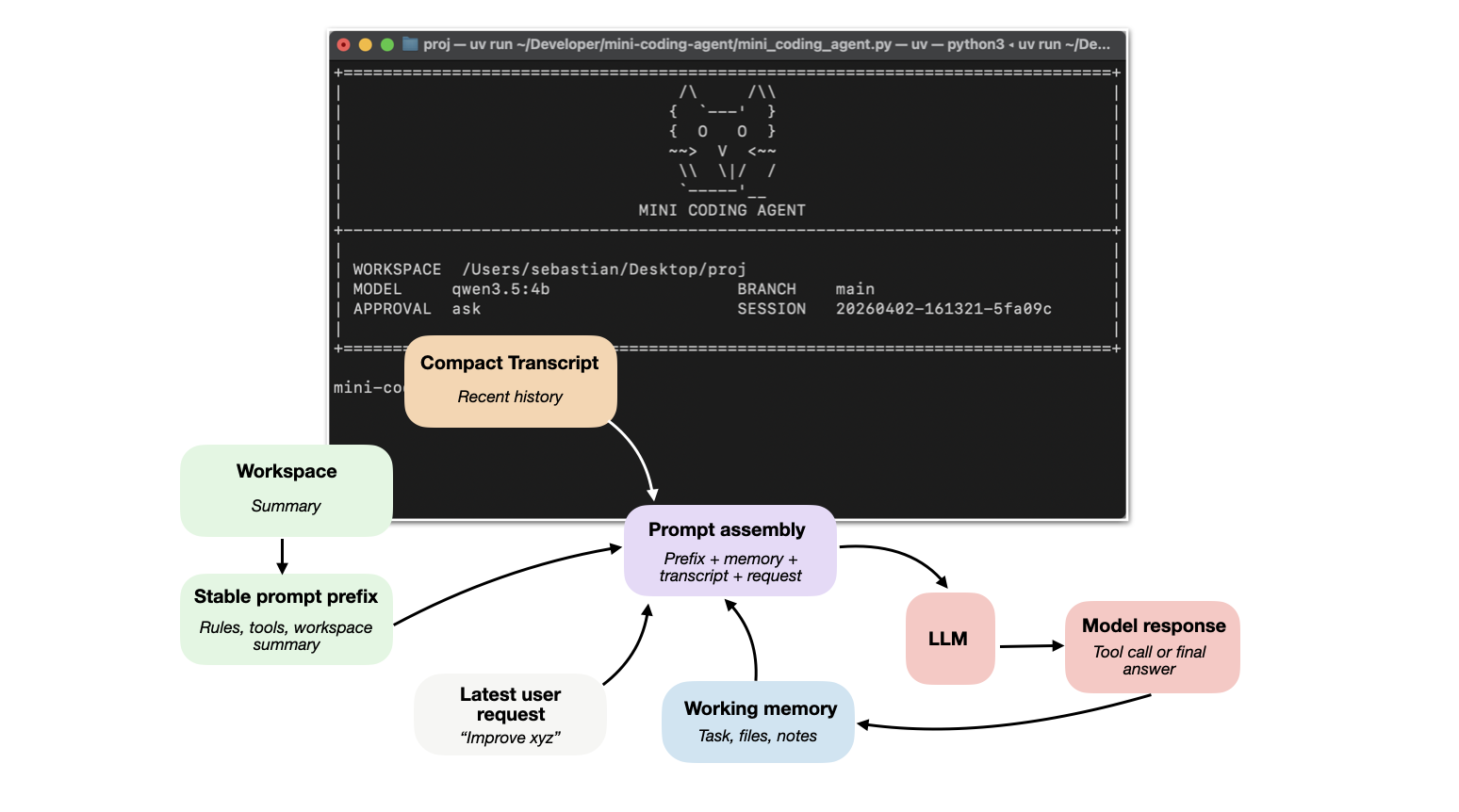
Tác nhân mã hóa được thiết kế cho công việc phần mềm trong đó các bộ phận đáng chú ý không chỉ là lựa chọn mô hình mà còn là hệ thống xung quanh, bao gồm bối cảnh kho lưu trữ, thiết kế công cụ, độ ổn định của bộ đệm nhanh, bộ nhớ và tính liên tục trong phiên dài.
Sự khác biệt đó quan trọng vì khi chúng ta nói về khả năng mã hóa của LLM, mọi người thường thu gọn mô hình, hành vi lý luận và sản phẩm tác nhân thành một. Nhưng trước khi đi vào chi tiết cụ thể về tác nhân mã hóa, hãy để tôi cung cấp ngắn gọn thêm một chút bối cảnh về sự khác biệt giữa các khái niệm rộng hơn, LLM, mô hình lý luận và tác nhân.
Về mối quan hệ giữa LLM, mô hình lý luận và tác nhân
LLM là mô hình token tiếp theo cốt lõi. Một mô hình lý luận vẫn là một LLM, nhưng thường là một mô hình đã được đào tạo và/hoặc được nhắc dành nhiều thời gian suy luận hơn để tính toán, xác minh hoặc tìm kiếm các câu trả lời của ứng viên.
Tác nhân là một lớp ở trên cùng, có thể hiểu là một vòng điều khiển xung quanh mô hình. Thông thường, với một mục tiêu nhất định, lớp tác nhân (hoặc khai thác) sẽ quyết định nội dung cần kiểm tra tiếp theo, công cụ nào sẽ gọi, cách cập nhật trạng thái của nó và khi nào nên dừng, v.v.
Một cách đại khái, chúng ta có thể nghĩ về mối quan hệ như thế này: LLM là động cơ, mô hình lý luận là động cơ được tăng cường (mạnh hơn nhưng sử dụng đắt hơn) và bộ khai thác tác nhân giúp chúng ta xây dựng mô hình. Sự tương tự này không hoàn hảo, bởi vì chúng ta cũng có thể sử dụng LLM thông thường và lý luận làm mô hình độc lập (trong giao diện người dùng trò chuyện hoặc phiên Python), nhưng tôi hy vọng nó truyền tải được điểm chính.
Hình 2: Mối quan hệ giữa LLM thông thường, LLM lý luận (hoặc mô hình lý luận) và LLM được bao bọc trong một khai thác tác nhân.
Nói cách khác, tác nhân là hệ thống liên tục gọi mô hình bên trong một môi trường.
Vì vậy, tóm lại, chúng ta có thể tóm tắt nó như thế này:
LLM: mô hình thô
Mô hình lý luận: LLM được tối ưu hóa để đưa ra các dấu vết lý luận trung gian và để xác minh chính nó nhiều hơn
Tác nhân: một vòng lặp sử dụng mô hình cùng với các công cụ, bộ nhớ và phản hồi về môi trường
Khai thác tác nhân: khung phần mềm xung quanh một tác nhân quản lý bối cảnh, việc sử dụng công cụ, lời nhắc, trạng thái và luồng điều khiển
Khai thác mã hóa: trường hợp đặc biệt của khai thác tác nhân; tức là khai thác theo nhiệm vụ cụ thể cho công nghệ phần mềm để quản lý bối cảnh mã, công cụ, thực thi và phản hồi lặp lại
Như đã liệt kê ở trên, trong bối cảnh tác nhân và công cụ mã hóa, chúng ta cũng có hai thuật ngữ phổ biến khai thác tác nhân và khai thác mã hóa (tác nhân). Khai thác mã hóa là khung phần mềm xung quanh một mô hình giúp nó viết và chỉnh sửa mã một cách hiệu quả. Và việc khai thác tác nhân rộng hơn một chút và không dành riêng cho việc mã hóa (ví dụ: hãy nghĩ đến OpenClaw). Codex và Claude Code có thể được coi là khai thác mã hóa.
Dù sao đi nữa, LLM tốt hơn cung cấp nền tảng tốt hơn cho mô hình lý luận (bao gồm đào tạo bổ sung) và khai thác sẽ tận dụng được nhiều hơn mô hình lý luận này.
Chắc chắn, LLM và mô hình lý luận cũng có khả năng tự giải quyết các nhiệm vụ mã hóa (không cần dây nịt), nhưng công việc mã hóa chỉ một phần là về việc tạo mã thông báo tiếp theo. Phần lớn trong số đó là về điều hướng repo, tìm kiếm, tra cứu chức năng, ứng dụng khác biệt, thực hiện kiểm tra, kiểm tra lỗi và lưu giữ tất cả thông tin liên quan trong ngữ cảnh. (Các lập trình viên có thể biết rằng đây là công việc trí óc vất vả, đó là lý do tại sao chúng ta không muốn bị gián đoạn trong các buổi viết mã :)).
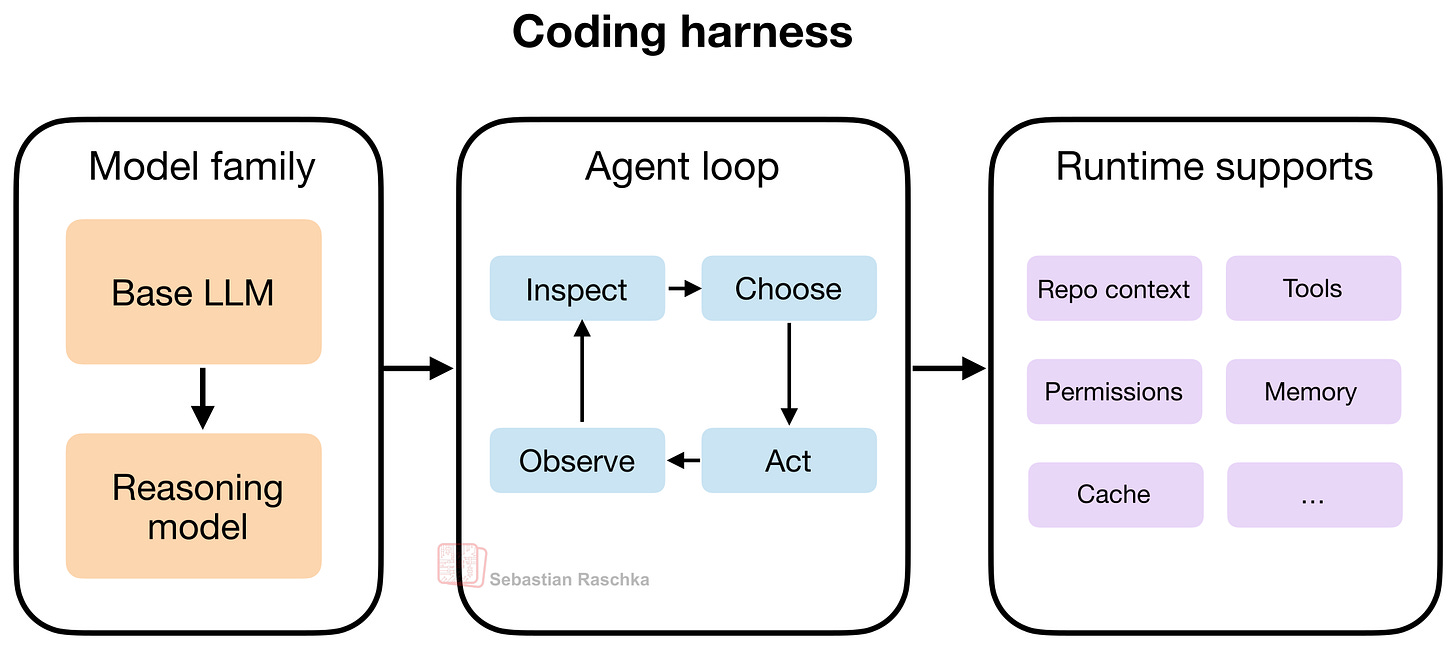
Hình 3. Khai thác mã hóa kết hợp ba lớp: họ mô hình, vòng lặp tác nhân và hỗ trợ thời gian chạy. Mô hình này cung cấp “động cơ”, vòng lặp tác nhân thúc đẩy việc giải quyết vấn đề lặp đi lặp lại và các hỗ trợ thời gian chạy cung cấp hệ thống ống nước. Trong vòng lặp, “quan sát” thu thập thông tin từ môi trường, “kiểm tra” phân tích thông tin đó, “chọn” chọn bước tiếp theo và “hành động” thực thi bước đó.
Điều đáng rút ra ở đây là việc khai thác mã hóa tốt có thể làm cho mô hình lý luận và phi lý luận trở nên mạnh mẽ hơn nhiều so với mô hình trong một hộp trò chuyện đơn giản vì nó giúp quản lý bối cảnh và hơn thế nữa.
Khai thác mã hóa
Như đã đề cập trong phần trước, khi chúng tôi nói khai thác, chúng tôi thường muốn nói đến lớp phần mềm xung quanh mô hình có chức năng tập hợp các lời nhắc, hiển thị công cụ, theo dõi trạng thái tệp, áp dụng các chỉnh sửa, chạy lệnh, quản lý quyền, lưu trữ các tiền tố ổn định, lưu trữ bộ nhớ, v.v.
Ngày nay, khi sử dụng LLM, lớp này định hình hầu hết trải nghiệm người dùng so với việc nhắc trực tiếp vào mô hình hoặc sử dụng giao diện người dùng trò chuyện trên web (gần giống với “trò chuyện với các tệp đã tải lên”).
Vì, theo quan điểm của tôi, các phiên bản vani của LLM ngày nay có những khả năng rất giống nhau (ví dụ: các phiên bản vani của GPT-5.4, Opus 4.6 và GLM-5 hoặc hơn), dây nịt thường có thể là yếu tố phân biệt giúp một LLM hoạt động tốt hơn phiên bản khác.
Thị
Nguồn tin: Ahead of AI — Tác giả: Sebastian Raschka, PhD. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.