Các bài nghiên cứu về LLM: Danh sách năm 2026 (tháng 1 đến tháng 5)
Ahead of AI· Sebastian Raschka, PhD· 6/6/2026models
Các bài báo nghiên cứu về LLM: Danh sách năm 2026 (tháng 1 đến tháng 5)
Như một số bạn đã biết, tôi có thói quen lâu năm là lập danh sách các bài báo nghiên cứu mà tôi muốn đọc, xem lại hoặc trích dẫn trong các bài viết và dự án trong tương lai.
Năm ngoái, tôi đã chia sẻ hai danh sách bài báo được sắp xếp khoa học, một danh sách bao gồm từ tháng 1 đến tháng 6 và một danh sách khác bao gồm từ tháng 7 đến tháng 12.
Một số độc giả đã cho tôi biết rằng những danh sách này rất hữu ích, vì vậy, với tinh thần tương tự, tôi đã chuẩn bị một danh sách mới cho nửa đầu năm 2026. Danh sách này bao gồm các bài báo tôi đã đánh dấu từ tháng 1 đến tháng 5 năm 2026.
Xin đừng coi đây là một danh sách đầy đủ tất cả những gì đã được xuất bản.
Các bài báo nghiên cứu về LLM: Danh sách năm 2026 (tháng 1 đến tháng 5)
Như một số người đã biết, tôi có thói quen lâu năm là lập một danh sách các bài báo nghiên cứu mà tôi muốn đọc, xem lại hoặc trích dẫn trong các bài viết và dự án trong tương lai.
Năm ngoái, tôi đã chia sẻ hai danh sách bài báo được sắp xếp, một danh sách bao gồm từ tháng 1 đến tháng 6 và một danh sách khác bao gồm từ tháng 7 đến tháng 12.
Một số độc giả đã nói với tôi rằng những danh sách này rất hữu ích, vì vậy, với tinh thần tương tự, tôi đã chuẩn bị một danh sách mới cho nửa đầu năm 2026. Danh sách này bao gồm các bài báo tôi đã đánh dấu từ tháng 1 đến tháng 5 năm 2026.
Xin đừng coi đây là một danh sách đầy đủ về mọi thứ được xuất bản trong năm nay. Có quá nhiều bài báo được xuất bản mỗi ngày nên điều này hoàn toàn không khả thi. Thay vào đó, đây là một danh sách tham khảo được tuyển chọn dựa trên các bài báo tôi thấy thú vị hoặc phù hợp với công việc của mình. Tôi đã xem xét kỹ lưỡng các tiêu đề, tóm tắt và cách trình bày chủ đề khi sắp xếp danh sách, nhưng tôi phải thừa nhận rằng tôi cũng chỉ đọc chi tiết một phần nhỏ các bài báo.
Tại sao lại lập những danh sách này ngay từ đầu? Khi tôi làm việc trên một bài báo, một phần sách, một ví dụ mã hoặc một bài giảng, tôi thường nhớ rằng mình đã thấy một bài báo liên quan ở đâu đó, nhưng việc tìm lại nó có thể gây khó chịu một cách đáng ngạc nhiên. Một danh sách Markdown được phân loại giải quyết vấn đề đó cho tôi, và tôi hy vọng nó cũng hữu ích cho bạn. (Ngay cả trong thời đại tìm kiếm trên web dựa trên LLM, việc có một danh sách ngữ cảnh cụ thể vẫn khá hữu ích.)
Năm nay, danh sách này một lần nữa tập trung nhiều vào các mô hình suy luận, học tăng cường (reinforcement learning) và suy luận hiệu quả (efficient inference), bởi vì tôi có xu hướng đánh dấu các bài báo liên quan đến những gì tôi đang thực hiện. Tuy nhiên, so với các danh sách năm 2025, tôi cũng đã đánh dấu nhiều bài báo hơn về các hệ thống tác nhân (agent harnesses), sử dụng công cụ (tool use), ngữ cảnh dài (long context), các mô hình ngôn ngữ khuếch tán (diffusion language models) và cơ sở hạ tầng phục vụ thực tế (practical serving infrastructure), bởi vì đó là những gì tôi đang tham gia nhiều và là hướng phát triển của lĩnh vực này.
Các danh mục cho danh sách bài báo nghiên cứu này như sau. (Mẹo chuyên nghiệp: Trong phiên bản web của bài viết này, bạn có thể sử dụng mục lục ở bên trái để chuyển trực tiếp đến các phần phù hợp nhất với bạn.)
Kiến trúc và Thiết kế Mô hình
Huấn luyện và Mở rộng Hiệu quả
Hiệu quả Suy luận và Bộ nhớ đệm KV
Chú ý Thưa thớt và Ngữ cảnh Dài
Suy luận và Tính toán Thời gian Kiểm tra
Học tăng cường và RLVR
Hệ thống tác nhân và Sử dụng công cụ
Tác nhân mã hóa và Kỹ thuật phần mềm
Mô hình ngôn ngữ khuếch tán
Đánh giá mô hình và Điểm chuẩn
1. Kiến trúc và Thiết kế Mô hình
Phần đầu tiên này tập hợp các bài báo về kiến trúc mô hình, báo cáo kỹ thuật phát hành mô hình và các bài báo giúp giải thích lý do tại sao các LLM hiện tại lại có hình dạng như vậy.
Một điều tôi thấy thú vị về năm 2026 cho đến nay là công việc kiến trúc vượt ra ngoài việc làm cho các bộ biến đổi (transformers) lớn hơn. Có rất nhiều công việc xung quanh
các kiến trúc lai (ví dụ: Nemotron 3 và Arcee Trinity),
các lớp không gian trạng thái (Nemotron 3 và Mamba-3),
phân bổ dung lượng MoE (Scaling Embeddings Outperforms Scaling Experts và Step 3.5 Flash),
hành vi kích hoạt (The Spike, the Sparse and the Sink),
và hình học biểu diễn (Symmetry in Language Statistics Shapes the Geometry of Model Representations).
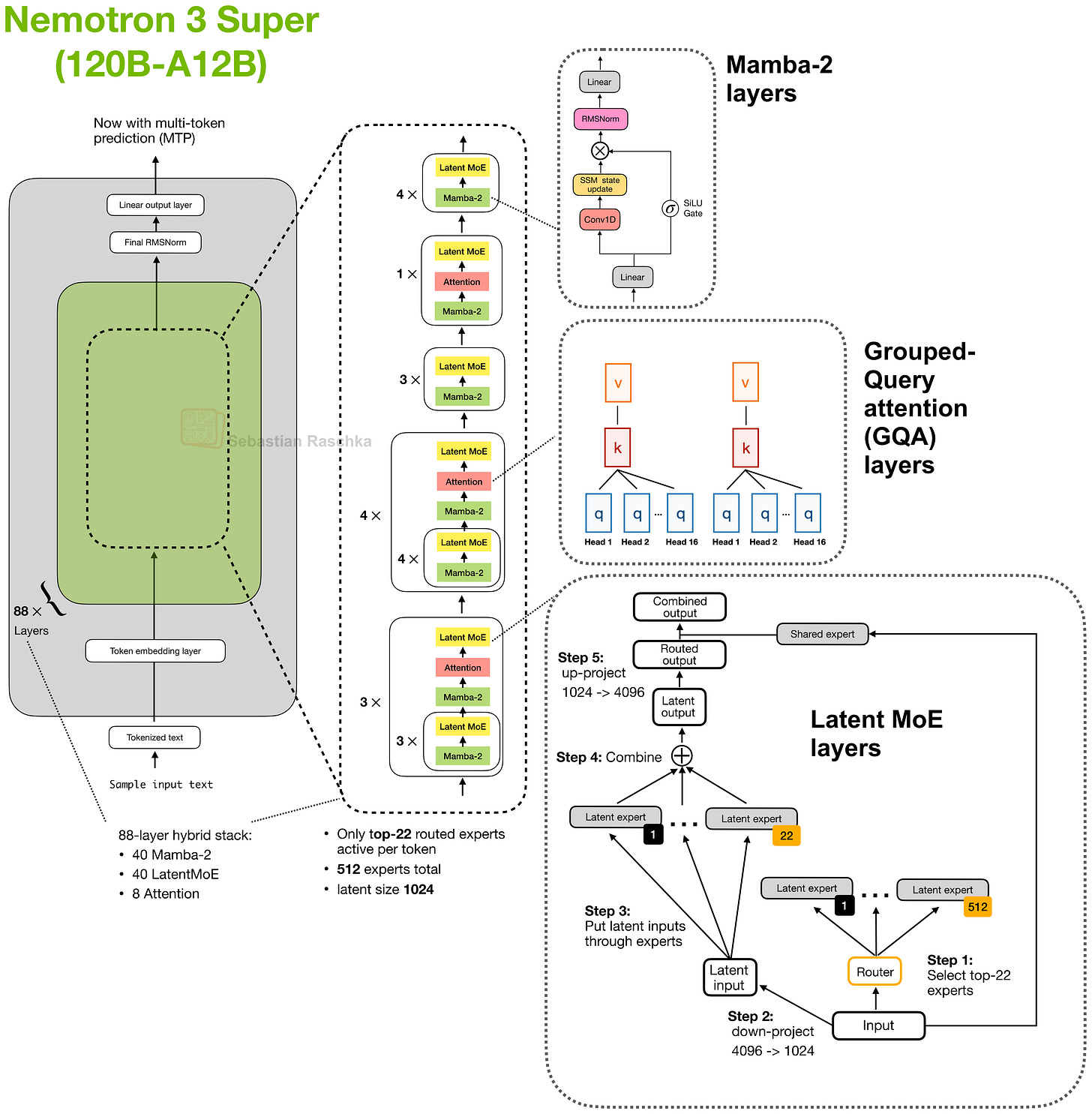
Tất cả các tài liệu này đều khá thú vị, đó là lý do tôi đã đánh dấu chúng ngay từ đầu. Nhưng nếu phải chọn một tài liệu bắt buộc phải đọc, tôi có lẽ sẽ chọn Nemotron 3 Super, vì bài viết cực kỳ chi tiết và mô tả các kỹ thuật được sử dụng trong một mô hình đã được đưa vào sản xuất. Hơn nữa, đây là một trong những mô hình tốt nhất trong phân khúc kích thước của nó.
Một trong những khía cạnh thú vị của Nemotron 3 là thiết kế kiến trúc lai của nó, nghĩa là nó xen kẽ giữa các lớp chú ý thông thường và các lớp Mamba-2 (mô hình không gian trạng thái) để hiệu quả hơn ở các ngữ cảnh dài. Vào năm 2026, hiệu quả ngữ cảnh dài là yếu tố then chốt khi ngày càng nhiều LLM được tích hợp vào các hệ thống tác nhân (OpenClaw, v.v.), đòi hỏi phải làm việc với các ngữ cảnh ngày càng dài hơn.
Mặc dù vậy, 120B-A12B có thể hơi quá lớn để suy luận cục bộ trên phần cứng tiêu dùng thông thường, nhưng cũng có phiên bản Nemotron 3 Nano (4B).
Hình 1: Kiến trúc của Nemotron-3 Super, là một kiến trúc lai sử dụng các lớp Mamba-2.
Lưu ý rằng 2 ngày trước, Nvidia cũng đã phát hành một phiên bản nâng cấp của mô hình này, Nemotron 3 Ultra (550B-A55B), phiên bản này mở rộng kích thước nhúng và chiếu nhưng vẫn sử dụng các khối xây dựng tương tự. Nếu quan tâm đến hình ảnh, tôi đã đăng về nó trên Substack Notes tại đây.
Xu hướng kiến trúc lai với các lớp chú ý xen kẽ và các lớp thay thế là một sự phát triển tương đối phổ biến trong năm nay. Dòng LLM mã nguồn mở có lẽ phổ biến nhất sử dụng thiết kế lai tương tự có lẽ là Qwen3.6, sử dụng các lớp Gated DeltaNet thay vì các lớp Mamba-2 cho các phần không chú ý. Để biết thêm thông tin, hãy xem bài viết của tôi về Hybrid Attention (https://sebastianraschka.com/llm-architecture-gallery/hybrid-attention/), tổng hợp thông tin từ một số bài viết substack trước đây của tôi về chủ đề này.
Ngoài ra, trong danh sách tài liệu dưới đây, bạn có thể nhận thấy rằng hiện đã có Mamba-3 và Gated DeltaNet-2 (tức là các phiên bản mới hơn của Mamba-2 và GatedDeltaNet), và sẽ rất thú vị khi thấy chúng trong các LLM mã nguồn mở sắp tới (ví dụ: Nemotron-4 và Qwen4?).
Bên cạnh việc mô tả thiết kế kiến trúc lai, tài liệu Nemotron-3 còn chứa rất nhiều phân tích thú vị khác, ví dụ, về dự đoán đa mã thông báo cho giải mã suy đoán, huấn luyện trước NVFP4 so với BF16, dữ liệu tổng hợp kiểu MMLU và các công thức lượng tử hóa sau huấn luyện, nhưng việc trình bày chi tiết những điều này sẽ nằm ngoài phạm vi của tổng quan này.
Ngày 1/1, Deep Delta Learning, https://arxiv.org/abs/2601.00417
Ngày 6/1, Báo cáo kỹ thuật MiMo-V2-Flash, https://arxiv.org/abs/2601.02780
Ngày 13/1, Ministral 3, https://arxiv.org/abs/2601.08584
Ngày 29/1, Mở rộng nhúng vượt trội so với mở rộng chuyên gia trong các mô hình ngôn ngữ, https://arxiv.org/abs/2601.21204
Ngày 30/1, LatentLens: Tiết lộ các mã thông báo hình ảnh có thể giải thích cao trong LLM, https://arxiv.org/abs/2602.00462
Ngày 4/2, ERNIE 5.0 Techni
Nguồn tin: Ahead of AI — Tác giả: Sebastian Raschka, PhD. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.