Bài báo mới: Hướng tới khoa học về độ tin cậy của tác nhân AI
Bởi Stephan Rabanser, Sayash Kapoor, Arvind Narayanan Giả sử bạn nghe nói về một tác nhân AI mới để cải thiện năng suất - bằng cách mua hàng, viết mã, gửi email hoặc thay mặt bạn xử lý khách hàng. Bạn có nên tin tưởng nó? Người đại diện có thể thực hiện công việc đủ tin cậy không? Rốt cuộc, có rất nhiều câu chuyện kinh dị về các đặc vụ mắc sai lầm. Điều đáng ngạc nhiên là mặc dù người ta đã biết rõ về sự thiếu độ tin cậy của các tác nhân AI, nhưng hiện tại ngành công nghiệp AI vẫn chưa có công cụ tốt để đo lường độ tin cậy hoặc thậm chí là một định nghĩa tốt về độ tin cậy. Arvind và Sayash đã suy nghĩ từ lâu
Bởi Stephan Rabanser, Sayash Kapoor, Arvind Narayanan
Giả sử bạn nghe nói về một tác nhân AI mới để cải thiện năng suất - bằng cách mua hàng, viết mã, gửi email hoặc thay mặt bạn xử lý khách hàng. Bạn có nên tin tưởng nó? Người đại diện có thể thực hiện công việc đủ tin cậy không? Rốt cuộc, có rất nhiều câu chuyện kinh dị về các đặc vụ mắc sai lầm.
Điều đáng ngạc nhiên là mặc dù người ta đã biết rõ về sự thiếu độ tin cậy của các tác nhân AI, nhưng hiện tại ngành công nghiệp AI vẫn chưa có công cụ tốt để đo lường độ tin cậy hoặc thậm chí là một định nghĩa tốt về độ tin cậy.
Arvind và Sayash đã suy nghĩ về điều này từ lâu. Mùa thu năm ngoái, chúng tôi có sự tham gia của nhà nghiên cứu sau tiến sĩ Stephan Rabanser, người có bằng tiến sĩ đã xem xét câu hỏi về độ tin cậy trong các hệ thống AI truyền thống, đơn giản hơn. Chúng tôi đã tuyển dụng một số nhà nghiên cứu độc lập khác và đã công bố thứ mà chúng tôi hy vọng là thước đo toàn diện về độ tin cậy. Bài viết dự thảo của chúng tôi có tên Hướng tới khoa học về độ tin cậy của tác nhân AI.
Chúng tôi mượn những hiểu biết sâu sắc từ nhiều lĩnh vực khác, chẳng hạn như an toàn hạt nhân và hàng không. Chúng tôi có thể phân tích độ tin cậy thành 12 khía cạnh khác nhau. Đánh giá 14 mô hình theo hai tiêu chuẩn bổ sung, chúng tôi nhận thấy rằng gần hai năm phát triển năng lực nhanh chóng chỉ mang lại mức độ tin cậy khiêm tốn. Xem bảng điều khiển tương tác của chúng tôi ở đây.
Mặc dù những phát hiện của chúng tôi chỉ mang tính thăm dò ở giai đoạn này, nhưng chúng tôi hy vọng chúng có thể giúp giải thích sự bối rối của nhiều người trong ngành về lý do tại sao tác động kinh tế của các tác nhân AI lại diễn ra dần dần, mặc dù chúng đang phá vỡ các tiêu chuẩn về năng lực.1 Để giúp cộng đồng theo dõi độ tin cậy một cách có hệ thống, chúng tôi dự định ra mắt “chỉ số độ tin cậy” của tác nhân AI. Chúng tôi hy vọng điều này sẽ kích thích các nhà nghiên cứu và ngành đầu tư nỗ lực cải thiện độ tin cậy.
Mục lục
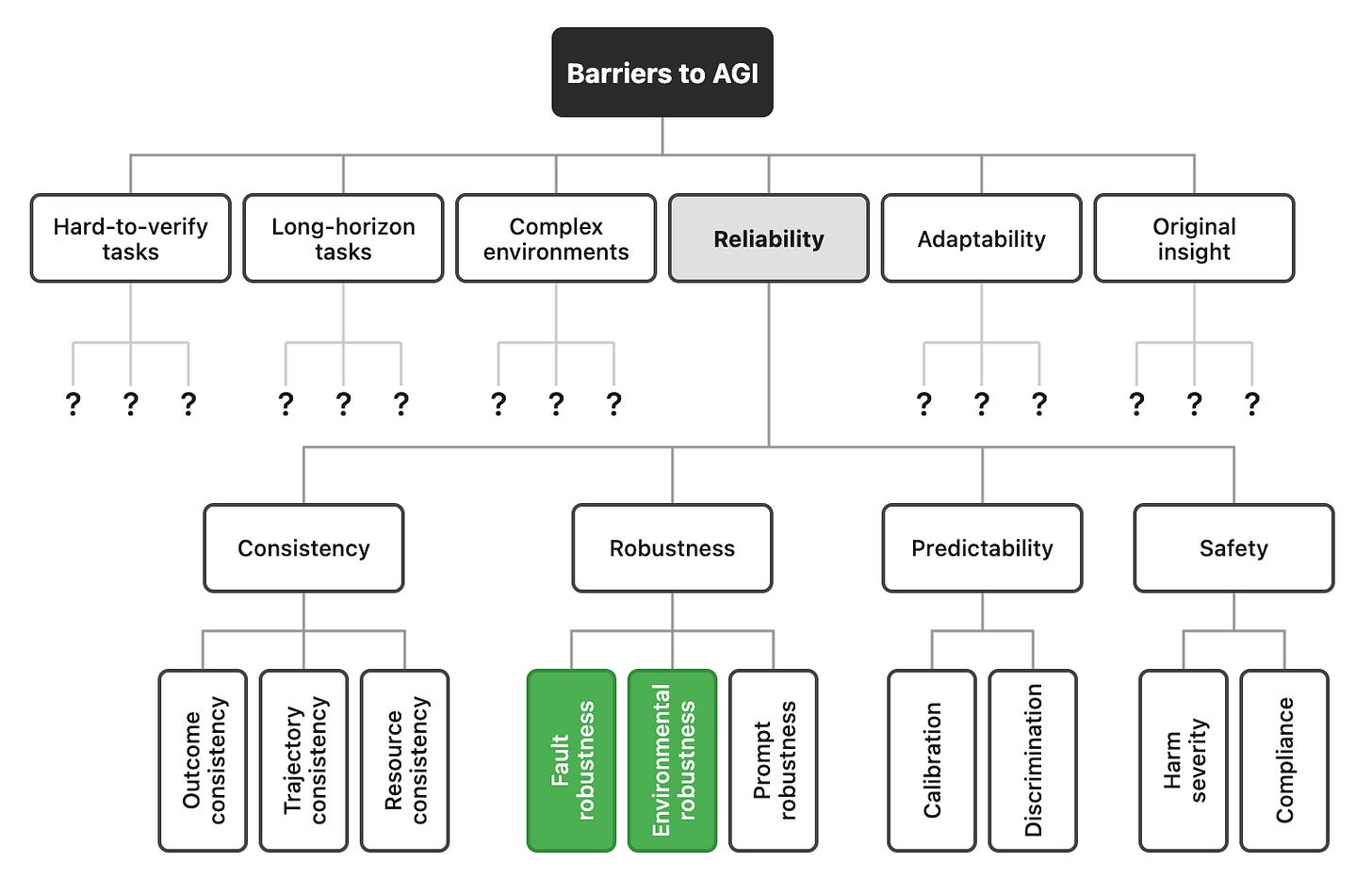
Độ chính xác thôi chưa đủ: bốn khía cạnh của độ tin cậy
Khả năng tăng lên nhanh chóng nhưng sự cải thiện về độ tin cậy còn khiêm tốn
Tại sao chúng ta có thể sai
Người triển khai nên làm gì khác đi?
Các nhà nghiên cứu và nhà phát triển nên làm gì khác nhau?
Những phát hiện của chúng tôi có ý nghĩa gì đối với sự tiến bộ của AI?
Đọc thêm
Độ chính xác thôi chưa đủ: bốn khía cạnh của độ tin cậy
Khi chúng ta coi đồng nghiệp là đáng tin cậy, chúng ta không chỉ có nghĩa là họ luôn làm mọi việc đúng đắn. Ý của chúng tôi là một cái gì đó phong phú hơn:
Họ luôn đúng, hôm nay không đúng và ngày mai sai về cùng một điều (Tính nhất quán)
Chúng không bị vỡ khi điều kiện không hoàn hảo (Mạnh mẽ)
Họ cho bạn biết khi họ không chắc chắn thay vì tự tin đoán (Hiệu chỉnh)
Khi họ làm hỏng việc, lỗi lầm của họ có nhiều khả năng sửa chữa được hơn là thảm họa (An toàn)
Thật không may, các tác nhân AI được đánh giá dựa trên một con số duy nhất, tỷ lệ thành công trung bình của nhiệm vụ. Con số đó đã tăng lên nhanh chóng đối với nhiều nhiệm vụ trong hai năm qua, đó là lý do tại sao có rất nhiều hứng thú về việc triển khai các đại lý.
Các lĩnh vực kỹ thuật quan trọng về an toàn (hàng không, hạt nhân, ô tô) đã nhận ra từ nhiều thập kỷ trước rằng độ tin cậy không giống như hiệu suất trung bình. Các lĩnh vực này hội tụ độc lập trên bốn khía cạnh trên: tính nhất quán, độ bền, khả năng dự đoán và an toàn (tần suất và mức độ nghiêm trọng của lỗi).
Ví dụ, hệ thống bảo vệ lò phản ứng hạt nhân phải đáp ứng giống hệt nhau mỗi khi có điều kiện yêu cầu ngừng hoạt động. Thử nghiệm an toàn ô tô đánh giá phản ứng đối với lỗi cảm biến và thời tiết bất lợi. Đánh giá rủi ro hạt nhân mô hình hóa hàng ngàn phương thức hư hỏng và định lượng xác suất của chúng. Hàng không đặt mục tiêu một lỗi thảm khốc trên một tỷ giờ bay
Khả năng tăng lên nhanh chóng nhưng sự cải thiện về độ tin cậy còn khiêm tốn
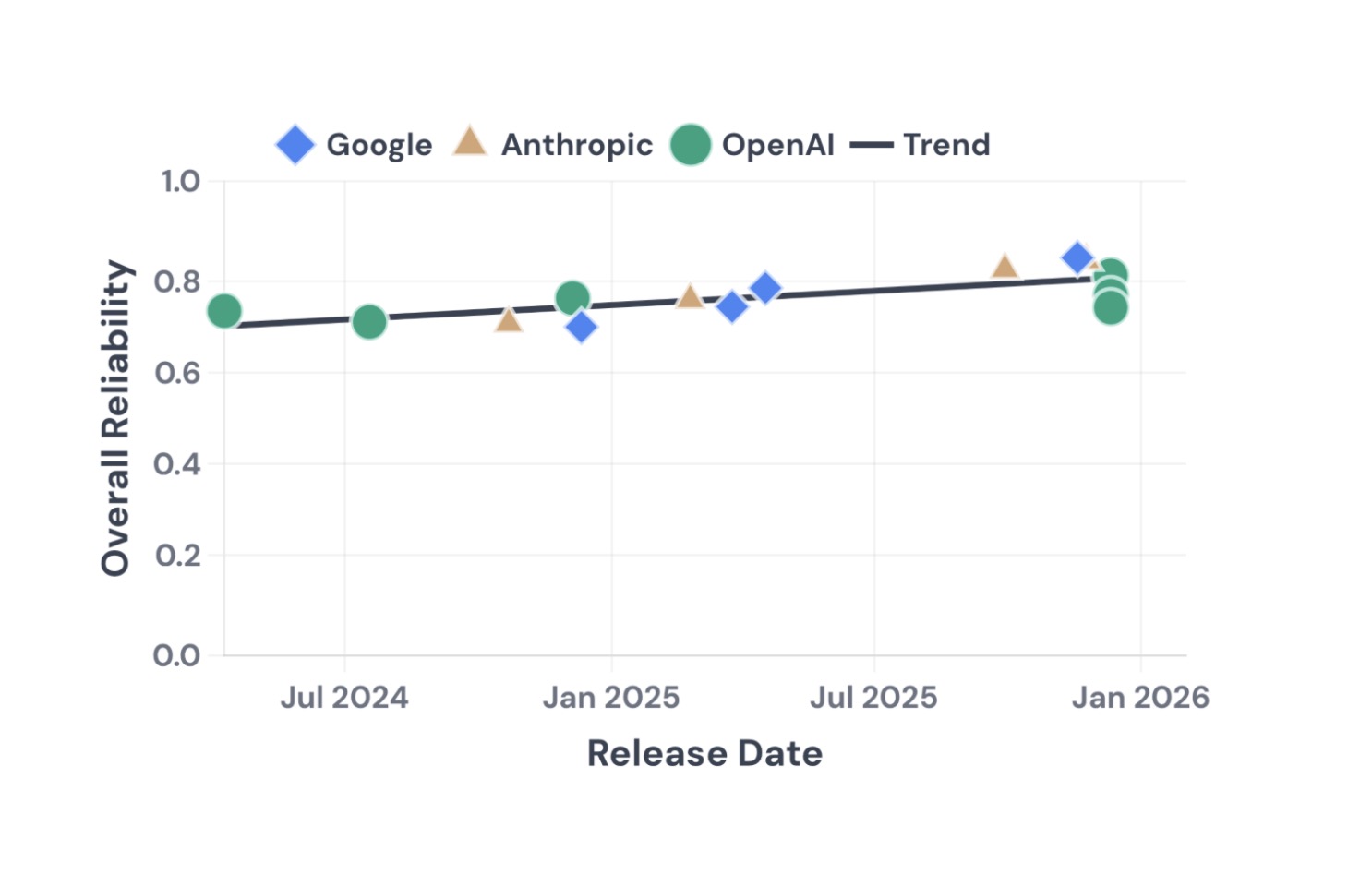
Chúng tôi đã tinh chỉnh và phân tách bốn thứ nguyên cấp cao này thành 12 số liệu. Sau đó, chúng tôi đã thử nghiệm các tác nhân dựa trên 14 mô hình từ OpenAI, Google và Anthropic, kéo dài 18 tháng phát hành. Chúng tôi đã xem xét hai điểm chuẩn bổ sung: điểm chuẩn trợ lý chung (GAIA) và điểm chuẩn mô phỏng dịch vụ khách hàng (TauBench). Chúng tôi thực hiện mỗi nhiệm vụ năm lần với các hướng dẫn được diễn giải. Chúng tôi đã đưa các lỗi vào các công cụ và môi trường để đo lường độ bền của những lỗi đó, đồng thời khơi dậy sự tự tin của các tác nhân khi đã giải quyết được nhiệm vụ đo lường hiệu chuẩn. Tổng cộng, chúng tôi đã thực hiện 500 lần chạy điểm chuẩn tổng thể.
Chúng tôi thấy rằng độ tin cậy chỉ được cải thiện khiêm tốn trong 18 tháng, trong khi độ chính xác được cải thiện đáng kể. Cả ba nhà cung cấp chính đều tập hợp lại với nhau, vì vậy đây dường như là một hạn chế trong toàn ngành (mặc dù có một số trường hợp mô hình của Anthropic hoạt động tốt hơn mô hình của OpenAI và Google).
Cụ thể hơn, chúng tôi đã đo lường các tiêu chí sau:
Tính nhất quán: Các tác nhân có thể giải quyết một nhiệm vụ thường thất bại khi thử lặp lại trong các điều kiện giống nhau. Nhiều mô hình gặp khó khăn trong việc đưa ra câu trả lời nhất quán, với điểm số nhất quán về kết quả dao động từ 30% đến 75% trên mọi phương diện.
Tính mạnh mẽ: Hầu hết các mô hình đều xử lý các lỗi kỹ thuật thực sự (sự cố máy chủ, hết thời gian chờ API) một cách khéo léo. Nhưng nếu chúng ta diễn đạt lại các hướng dẫn với cùng ý nghĩa ngữ nghĩa thì hiệu suất sẽ giảm đáng kể.
Khả năng dự đoán: Đại lý không giỏi trong việc biết khi nào họ sai. Đây là khía cạnh yếu nhất trên bảng. Khi các đại lý báo cáo sự tin cậy, nó thường mang ít tín hiệu. Trên một điểm chuẩn, hầu hết các mô hình không thể phân biệt dự đoán chính xác của chúng với dự đoán sai tốt hơn là ngẫu nhiên.
An toàn: Các mô hình gần đây có khả năng tránh vi phạm ràng buộc tốt hơn đáng kể, mặc dù các lỗi tài chính, chẳng hạn như tính phí không chính xác, vẫn là một dạng lỗi phổ biến. Chúng tôi sử dụng sự an toàn trong phạm vi hẹp có nghĩa là tổn hại có giới hạn khi xảy ra lỗi, chứ không phải những mối quan tâm rộng hơn như sự liên kết. Chúng tôi vẫn đang nghiên cứu lại cách đo lường mức độ an toàn nên chúng tôi báo cáo vấn đề này riêng biệt với điểm tin cậy tổng hợp.
Tác động của việc mở rộng quy mô: Các mô hình lớn hơn không đáng tin cậy hơn một cách thống nhất. Việc mở rộng quy mô sẽ cải thiện một số khía cạnh (hiệu chuẩn, độ bền) nhưng có thể ảnh hưởng đến tính nhất quán. Các mô hình lớn hơn với các tiết mục hành vi phong phú hơn đôi khi cho thấy nhiều sự biến đổi giữa các lần chạy.
Tại sao chúng tôi c
Nguồn tin: AI Snake Oil — Tác giả: Sayash Kapoor. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.