Trước thềm đợt nộp hồ sơ IPO (phát hành cổ phiếu lần đầu ra công chúng) của OpenAI vào tuần tới, Greg đã đưa ra bình luận mới nhất trong chuỗi các nhận định cho thấy các phòng thí nghiệm mô hình (Model Labs) ngày càng tập trung phát triển tác nhân (Agent) như một sản phẩm.
Phát biểu này đánh dấu sự thay đổi lớn trong quan điểm so với lập trường được hầu hết những người làm việc tại Team Big Model, bao gồm cả cựu trưởng bộ phận OpenAI Labs của ông, từng giữ vững.
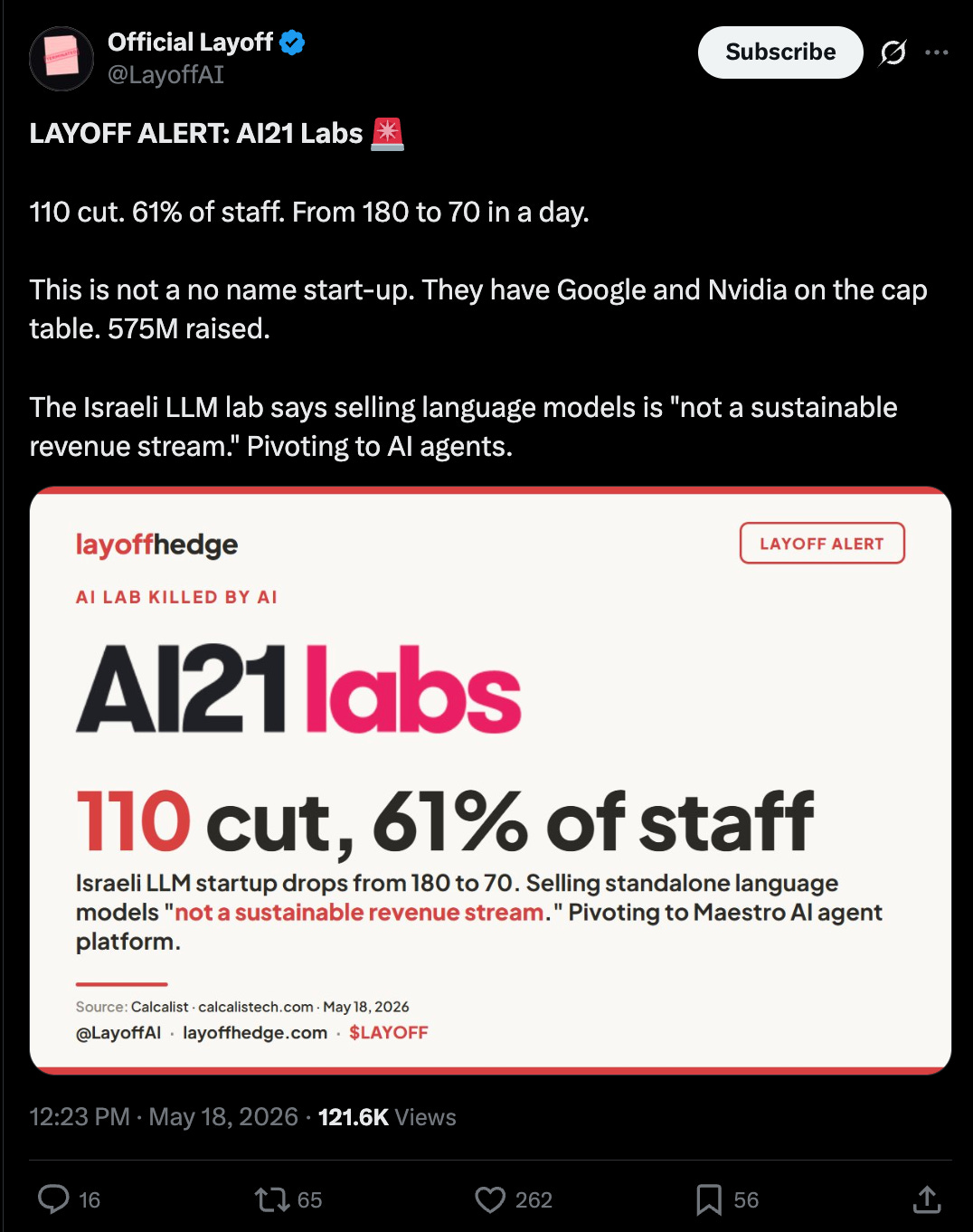
Điều này diễn ra cùng với việc đội ngũ phát triển mô hình của AI21 đã ngừng hoạt động và chuyển hướng sang phát triển tác nhân:
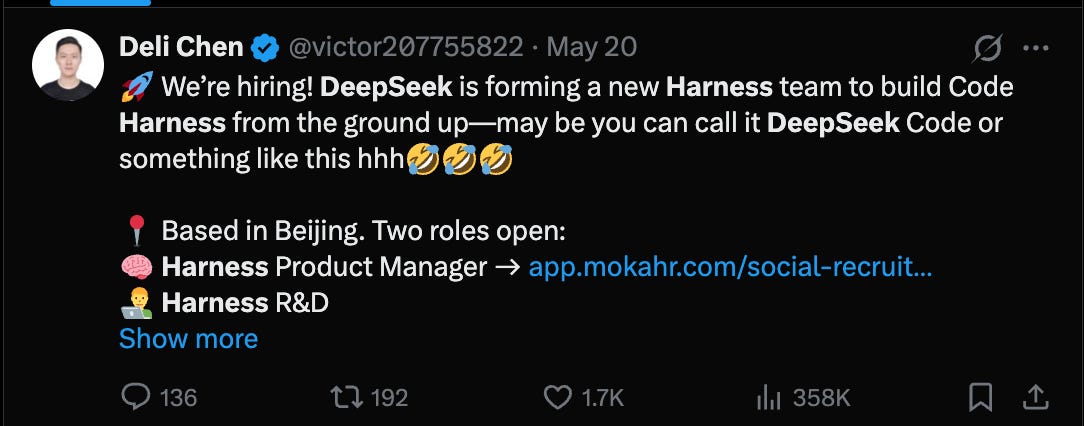
Thậm chí, DeepSeek danh tiếng cũng lần đầu tiên thành lập một "đội ngũ Harness":
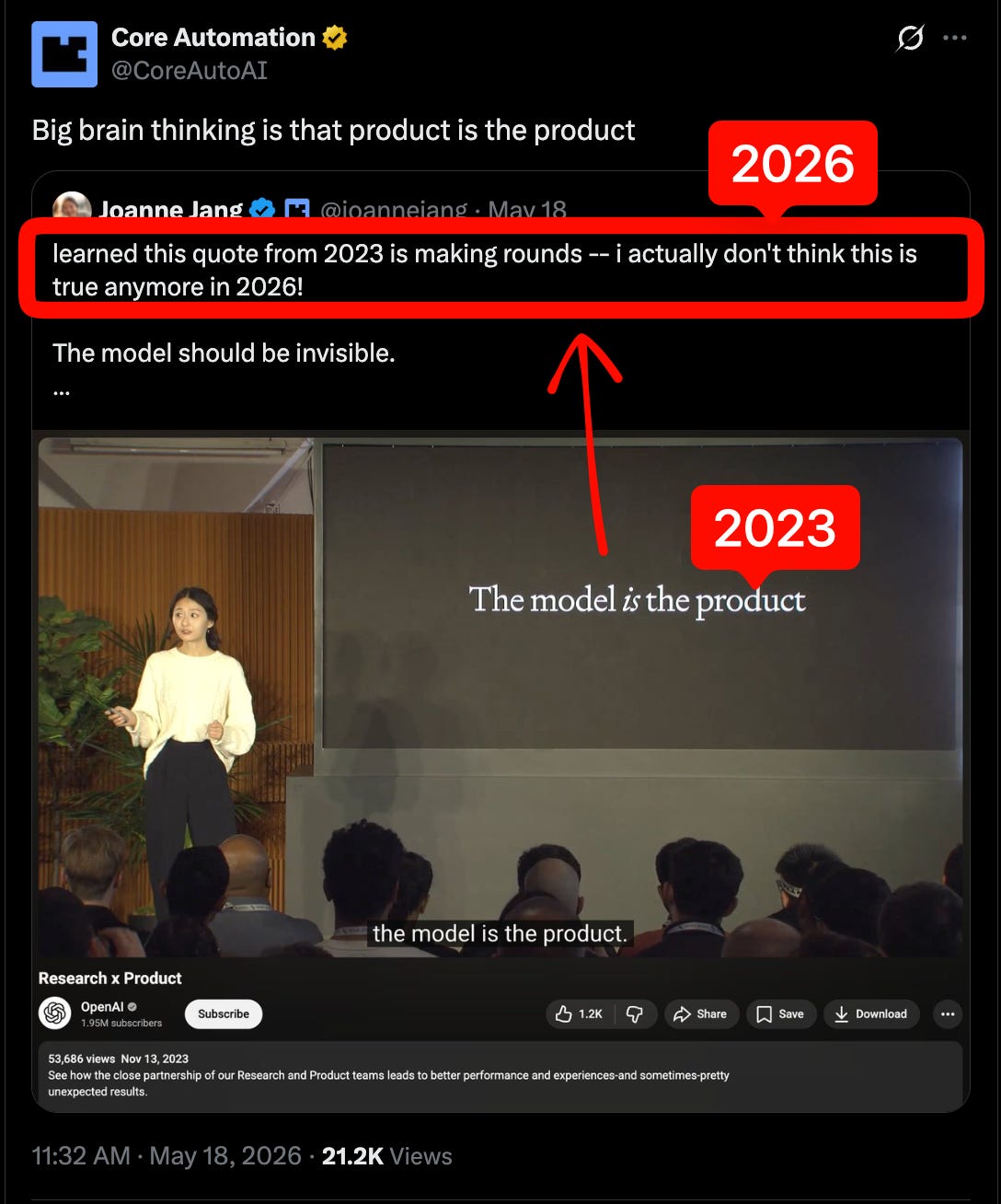
Những người ủng hộ quan điểm "Hệ thống hơn Mô hình" (Systems over Models) sẽ coi đây là một minh chứng cho lập luận của họ.
Trước thềm OpenAI có khả năng nộp hồ sơ IPO vào tuần tới, Greg đưa ra nhận định mới nhất trong một loạt bình luận cho thấy các phòng thí nghiệm mô hình (Model Labs) ngày càng xây dựng các tác nhân (Agents) như một sản phẩm:
Trích dẫn này là một sự đảo ngược lớn so với quan điểm được hầu hết những người làm việc tại Team Big Model, bao gồm cả người đứng đầu OpenAI Labs trước đây của ông, đồng loạt ủng hộ:
Điều này đi kèm với việc đội ngũ mô hình của AI21 đóng cửa, hiện đang chuyển hướng sang các tác nhân:
và ngay cả DeepSeek danh tiếng giờ đây cũng lần đầu tiên thành lập một “đội ngũ Harness”:
Những người ủng hộ “Hệ thống hơn Mô hình” (Systems over Models) sẽ coi đây là một điểm xác nhận cho những gì họ đã nói từ trước đến nay… ngoại trừ một sắc thái là các mô hình được huấn luyện cùng với các harness (công cụ điều khiển) thực sự mở ra cánh cửa để hạn chế quyền truy cập vào các mô hình hơn nữa — nếu bạn có thể huấn luyện sau một mô hình để chỉ hoạt động hiệu quả với tác nhân mã nguồn đóng của bạn, thì bạn sẽ thu hút phần lớn người dùng đến với tác nhân của mình, gây bất lợi cho sự cạnh tranh của mô hình/API của bạn.
Nhưng đó là một chủ đề của một cuộc thảo luận lớn hơn nhiều…
Tin tức AI ngày 4/5/2026-5/5/2026. Chúng tôi đã kiểm tra 12 subreddit, 544 tài khoản Twitter và không có thêm Discord nào. Trang web của AINews cho phép bạn tìm kiếm tất cả các số báo trước đây. Xin nhắc lại, AINews hiện là một phần của Latent Space. Bạn có thể chọn nhận/không nhận email thường xuyên!
Tổng kết Twitter về AI
Sản phẩm tác nhân, Harness và sự chuyển dịch vượt ra ngoài “Chỉ là mô hình”
Bề mặt sản phẩm đang dịch chuyển lên cấp cao hơn: Một chủ đề lặp đi lặp lại là chất lượng mô hình đơn thuần không còn là lợi thế cạnh tranh; sản phẩm chiến thắng ngày càng là mô hình + harness + quy trình làm việc + giao diện người dùng + bộ nhớ + kinh tế. @gdb đã nói thẳng thừng: “mô hình đơn thuần không còn là sản phẩm,” trong khi @dzhng lập luận rằng các sản phẩm hàng đầu cần sự cộng sinh giữa mô hình <> harness <> sản phẩm. Mô hình tương tự cũng xuất hiện trong thực tế: @signulll đã định hình AI môi trường và AI tác nhân là ranh giới mới của giao diện máy tính, và @teortaxesTex lưu ý rằng nghiên cứu về harness vẫn có nguy cơ hội tụ vào “tái tạo Claude Code” thay vì khám phá các giao diện rộng hơn.
Sự khác biệt về sản phẩm tác nhân mã hóa đang trở nên rõ ràng: OpenAI đã phát hành một bản cập nhật Codex đáng kể khác thông qua “codex thursday no. 6” với appshots, cải tiến /goal, sử dụng máy tính từ xa khi bị khóa, chế độ chú thích, chia sẻ plugin và phân tích. @gdb đã riêng biệt nhấn mạnh Appshots, trong khi người dùng báo cáo những thay đổi đáng kể trong quy trình làm việc: @gdb nói rằng thật khó để nhớ việc mã hóa trước Codex, và @reach_vb nói rằng họ đã không mở IDE trong hơn một tháng. Nhưng những điểm chưa hoàn thiện của sản phẩm vẫn còn: @theo đã ca ngợi tính năng từ xa của T3 Code là vượt trội so với các lựa chọn thay thế, sau đó đối lập nó với các quy trình làm việc từ xa bị lỗi trong Codex trong một bài đăng tiếp theo. Về phía Claude, @ClaudeDevs đã mở rộng chế độ tự động cho gói Pro và thêm hỗ trợ Sonnet 4.6; @_mohansolo cũng phải làm rõ và vá lỗi hỗ trợ IDE trong Antigravity 2.0 sau phản ứng tiêu cực của người dùng.
Hiệu suất mô hình, đường cong chi phí và cạnh tranh biên giới
Động thái định giá của DeepSeek là tín hiệu thị trường lớn nhất: @deepseek_ai đã giảm giá vĩnh viễn 75% cho DeepSeek-V4-Pro, gây ra phản ứng mạnh mẽ vì nó thay đổi đáng kể đường biên chi phí/hiệu suất. @ArtificialAnlys đã định lượng giá của bên thứ nhất ở mức 0,435 USD/M đầu vào, 0,87 USD/M đầu ra, 0,0036 USD/M đầu vào được lưu vào bộ nhớ cache, ước tính tổng hợp khoảng 0,18 USD/M và đặt V4 Pro vào đường biên Pareto về trí thông minh so với chi phí vận hành. Họ ước tính việc chạy Chỉ số thông minh của họ trên V4 Pro tốn kém ít hơn khoảng 3 lần so với Gemini 3.1 Pro Preview, ít hơn khoảng 12 lần so với GPT-5.5 và ít hơn khoảng 19 lần so với Claude Opus 4.7. Phản ứng của cộng đồng tập trung vào việc DeepSeek thúc đẩy "trí thông minh quá rẻ để đo lường", như @scaling01 đã nói. @Yuchenj_UW và @kimmonismus đều nhấn mạnh mức độ cắt giảm.
Gemini Flash đã được cải thiện, nhưng phản hồi sử dụng còn trái chiều: @OfficialLoganK báo cáo Gemini 3.5 Flash đã đạt được tiến bộ lớn so với 3.1 Pro trên GDPval, tuyên bố Flash hiện đang "cạnh tranh ở biên giới", và @Designarena đã xếp nó thứ 16 tổng thể trên Design Arena, một bước nhảy 16 vị trí so với Gemini 3 Flash Preview. Nhưng một số nhà phát triển đã phản đối về tính hữu dụng so với lợi ích điểm chuẩn: @Alezander907 chỉ thấy cải thiện nhẹ của tác nhân trình duyệt với chi phí cao hơn, @giffmana lập luận rằng đây không phải là "tiến bộ của Flash" nếu thương hiệu vẫn ngụ ý giá rẻ, và @jeremyphoward nói rằng mô hình này dường như được tối ưu hóa để tối đa hóa các đánh giá hơn là hợp tác với con người. Điều đó phù hợp với sự hoài nghi đánh giá rộng rãi hơn từ @HamelHusain, người lập luận rằng các công cụ hiện tại đánh giá thấp phán đoán định tính, HITL.
Các mô hình biên giới Qwen và Trung Quốc tiếp tục nén cuộc đua: Các đoạn giới thiệu chính thức của @Alibaba_Qwen và một bài đánh giá dài của bên thứ ba từ @ZhihuFrontier đã mô tả Qwen3.7-Max là một bước tiến đáng kể, đặc biệt trong việc tuân thủ hướng dẫn, độ tin cậy ngữ cảnh và sự ổn định, trong khi vẫn gặp phải tình trạng dài dòng và sử dụng token cao. Ở những nơi khác, @scaling01 tuyên bố các lần chạy ALE-Bench gần đây cho thấy các mô hình Trung Quốc như Kimi-K2.6, DeepSeek-V4, GLM-5.1 vượt trội hơn một số bản phát hành phương Tây trong cài đặt đó. @ArtificialAnlys cũng báo cáo Cursor Composer 2.5 rẻ hơn 3–18 lần so với Opus 4.7 và rẻ hơn 5–32 lần so với GPT-5.5 trên các điểm chuẩn Coding Agent, với mức sử dụng token thấp hơn đáng kể.
Giao thức, Cơ sở hạ tầng và Công cụ thời gian chạy tác nhân
Bản phát hành ứng cử viên mới của MCP là một sự đơn giản hóa giao thức đáng kể: @dsp_ đã công bố bản phát hành ứng cử viên MCP 2026-07-28, với thay đổi quan trọng là giao thức hiện không trạng thái: không bắt tay, không ID phiên và bất kỳ yêu cầu nào cũng có thể truy cập bất kỳ phiên bản máy chủ nào. RC cũng giới thiệu các tiện ích mở rộng hạng nhất như MCP Apps và Tasks, cùng với việc tăng cường xác thực và chính sách ngừng hoạt động rõ ràng hơn. Đối với các nhóm cơ sở hạ tầng, tính không trạng thái là một sự thay đổi hoạt động lớn: dễ dàng mở rộng quy mô hơn, cân bằng tải đơn giản hơn, ít lo ngại về phiên dính hơn.
Hộp cát và thực thi được quản lý đang trở thành các nguyên thủy hạng nhất: @_philschmid đã trình diễn Gemini Managed Agents + Interactions API để cung cấp cho một tác nhân một hộp cát Linux được lưu trữ an toàn với bộ nhớ và thực thi mã. @CoreWeave đã ra mắt CoreWeave Sandboxes trong bản xem trước công khai cho RL, tác nhân đến
Nguồn tin: Latent Space. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.