[AINews] NVIDIA Cosmos 3, Nemotron 3 Ultra và RTX Spark
Khách mời podcast hôm nay là người đứng đầu dự án NVIDIA Cosmos cách đây hơn một năm, thảo luận về việc huấn luyện các mô hình videogen và mô hình thế giới. Thật trùng hợp, Cosmos 3 đã ra mắt hôm nay, hợp nhất ngôn ngữ, hình ảnh, video, âm thanh và hành động trong kiến trúc Mixture-of-Transformers, kết hợp một bộ suy luận tự hồi quy với một bộ tạo khuếch tán trong các mô hình: Nano cơ bản (16B: tháp suy luận 8B + tháp tạo 8B) Super (64B: tháp suy luận 32B + tháp tạo 32B), và Các mô hình Super tinh chỉnh cho Text2Image và Image2Video, hiện là các mô hình tạo ảnh và tạo video mã nguồn mở SOTA mới, chỉ đứng sau Nano Banana 2 Tại Computex
Khách mời podcast hôm nay là trưởng nhóm NVIDIA Cosmos cách đây hơn một năm, thảo luận về việc đào tạo videogen và các mô hình thế giới. Thật phù hợp, Cosmos 3 đã ra mắt hôm nay, hợp nhất ngôn ngữ, hình ảnh, video, âm thanh và hành động trong kiến trúc Mixture-of-Transformers, kết hợp một bộ suy luận tự hồi quy với một bộ tạo khuếch tán trong:
các mô hình Nano cơ bản (16B: tháp suy luận 8B + tháp tạo 8B)
các mô hình Super (64B: tháp suy luận 32B + tháp tạo 32B), và
các mô hình Super tinh chỉnh cho Text2Image và Image2Video, hiện là các mô hình imagegen và videogen mã nguồn mở SOTA mới, chỉ đứng sau Nano Banana 2.
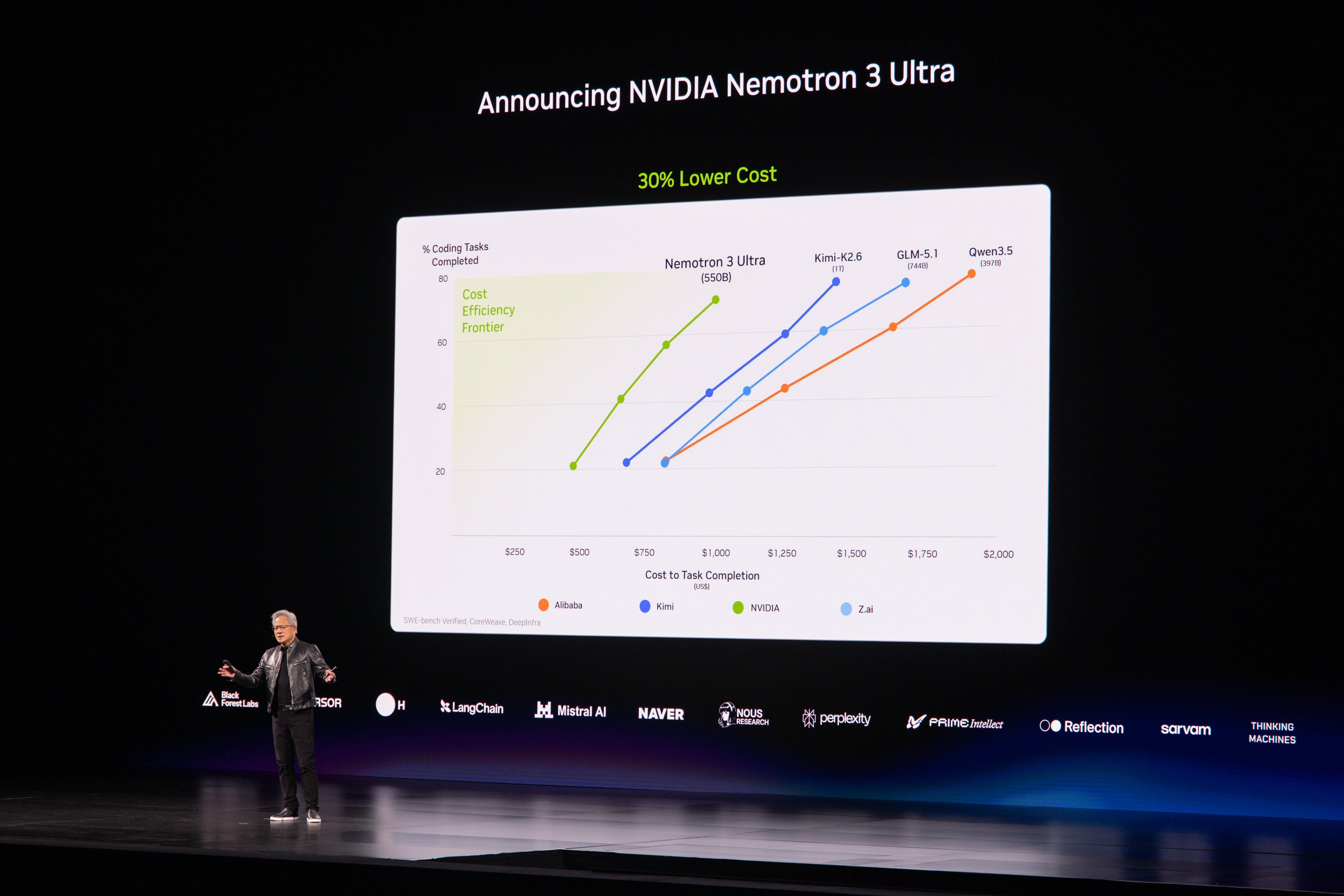
Tại Computex ở Đài Loan, Jensen cũng gây ấn tượng với Nemotron 3 Ultra, LLM mã nguồn mở 550B-A55B của họ, cực kỳ hiệu quả/nhanh chóng và là SoTA của Mỹ:
Cuối cùng, siêu chip máy tính cá nhân RTX Spark 1 petaflop đã được giới thiệu trước với Microsoft và OpenClaw cùng Hermes Agent là đối tác ra mắt (phân tích tốt tại đây).
Tin tức AI từ ngày 30/5/2026 đến 1/6/2026. Chúng tôi đã kiểm tra 12 subreddit, 544 tài khoản Twitter và không có Discord nào khác. Trang web của AINews cho phép bạn tìm kiếm tất cả các số báo trước. Xin nhắc lại, AINews hiện là một phần của Latent Space. Bạn có thể chọn nhận/không nhận email theo tần suất!
Tổng hợp AI Twitter
NVIDIA Cosmos 3, Nemotron 3 Ultra và thúc đẩy AI vật lý mở
Tuần lễ mã nguồn mở của NVIDIA: NVIDIA đã thống trị cuộc trò chuyện về mô hình mở với Cosmos 3, một họ mô hình thế giới đa phương thức mở cho AI vật lý, cùng với thông báo về Nemotron 3 Ultra, một mô hình mã nguồn mở 550B mà một số người dùng gọi là mô hình mở mạnh nhất của Hoa Kỳ cho đến nay. Cosmos 3 được coi là một bản phát hành đầy đủ – trọng số, mã, tập dữ liệu và công thức tinh chỉnh – với việc NVIDIA cũng ra mắt Liên minh Cosmos cùng với các đối tác bao gồm Runway để xây dựng một hệ sinh thái mở cho các mô hình thế giới @NVIDIAAI bối cảnh hệ sinh thái, @runwayml thông báo liên minh, @kimmonismus chủ đề Cosmos, @ClementDelangue về dấu ấn HF của NVIDIA.
Tại sao Cosmos 3 lại quan trọng về mặt kỹ thuật: Ngoài những lời lẽ về robot, các chi tiết cụ thể hơn là Cosmos 3 hợp nhất ngôn ngữ, hình ảnh, video, âm thanh và hành động trong một thiết kế Mixture-of-Transformers duy nhất, kết hợp một bộ suy luận tự hồi quy với một bộ tạo khuếch tán. Artificial Analysis cho biết Cosmos 3 đã đạt vị trí số 1 trong số các mô hình mã nguồn mở trên cả bảng xếp hạng Text-to-Image và Image-to-Video của họ, lưu ý rằng bộ tạo sử dụng các lời nhắc JSON có cấu trúc và có thể được điều khiển bởi một bộ điều khiển nâng cấp lời nhắc bên ngoài hoặc nhánh suy luận của chính nó. Riêng biệt, sự thúc đẩy phần cứng + phần mềm của NVIDIA đã mở rộng sang việc áp dụng khung OpenMDW và tích hợp hệ sinh thái đối tác trên các nền tảng như fal @ArtificialAnlys, @fal.
Phản ứng về Nemotron 3 Ultra: Phản ứng của cộng đồng đối với Nemotron 3 Ultra mạnh mẽ bất thường đối với một bản phát hành mở mới. Người dùng đã nhấn mạnh cả khả năng và đặc điểm phục vụ, bao gồm các tuyên bố rằng nó đã đứng đầu một số đánh giá mở và có thể phục vụ ở tốc độ hơn 300 tok/s trong một số thiết lập – nhanh hơn nhiều so với các mô hình lớn thuộc lớp DeepSeek/Kimi @scaling01, @ctnzr, @caspar_br. Cũng có một số thảo luận kỹ thuật rằng Nemotron dường như ít thưa thớt hơn so với các đối thủ như Kimi K2 / DeepSeek V4 – khoảng ~10% hoạt động so với ~3% – điều này có thể ảnh hưởng đến cả kinh tế và hành vi @eliebakouch.
MiniMax M3, Qwen3.7-Plus và JetBrains Mellum2 mở rộng lĩnh vực mô hình tác nhân mở
Việc ra mắt MiniMax M3 là sự kiện phát hành mô hình lớn nhất trong ngày: M3 được giới thiệu là một mô hình tác nhân/mã hóa đa phương thức có trọng số mở với ngữ cảnh 1M, khả năng đa phương thức gốc và các điểm chuẩn tác nhân cạnh tranh. Các số liệu nổi bật được lặp lại trên các đối tác ra mắt là 59,0% SWE-Bench Pro, 66,0% Terminal Bench 2.1 và 74,2% MCP Atlas @MiniMax_AI, @PBDTokenRouter, @kimmonismus. Nhiều nhà cung cấp cơ sở hạ tầng đã hỗ trợ ngay lập tức – Novita, Vercel AI Gateway, Cloudflare AI Gateway, OpenClaude, Flowith và các nhà cung cấp khác – cho thấy sự chấp nhận hệ sinh thái nhanh chóng bất thường @MiniMax_AI trên Novita, @rauchg, @gitlawb.
Các điểm chuẩn so với kinh nghiệm thực tế có sự khác biệt: M3 nhận được lời khen ngợi về khả năng tạo giao diện người dùng (frontend), các tác vụ trực quan/trò chơi và hiệu suất giá thành, với các bản demo song song cho thấy đầu ra giao diện người dùng/trò chơi một lần mạnh mẽ và vị trí điểm chuẩn đáng chú ý cho các đánh giá tác nhân Next.js @notjazii, @lostinlatencyX, @rauchg. Tuy nhiên, một số nhà đánh giá cũng báo cáo mức tiêu thụ token cao, các vòng lặp tự kiểm tra dài dòng và đôi khi có sự sai lệch yêu cầu đối với các tác vụ dài, khiến M3 trông giống một mô hình "chất lượng trước, hiệu quả sau" hơn @ZhihuFrontier review, @teortaxesTex skepticism.
Qwen3.7-Plus: Alibaba đã ra mắt Qwen3.7-Plus dưới dạng một tác nhân lai tương tác đa phương thức, thống nhất hoạt động GUI (giao diện người dùng đồ họa) và CLI (giao diện dòng lệnh), suy luận trực quan, mã hóa và QA (hỏi đáp) được tăng cường tìm kiếm. Nó có sẵn thông qua API của Alibaba Cloud Model Studio và nhanh chóng được thêm vào các công cụ như Cline @Alibaba_Qwen launch, @cline. Việc ra mắt này củng cố xu hướng rằng các phòng thí nghiệm châu Á "mở" không còn chỉ phát hành "mô hình trò chuyện" mà là các hệ thống đa phương thức có khả năng tác nhân đầy đủ.
JetBrains Mellum2: JetBrains đã phát hành Mellum2, một mô hình MoE (Mixture of Experts) 12B với 2,5B tham số hoạt động, được đào tạo trên khoảng 11T token và được hậu đào tạo bằng RLVR (Reinforcement Learning from Visual Rewards), cung cấp các điểm kiểm tra cơ sở / SFT (Supervised Fine-Tuning) / RL (Reinforcement Learning) và một báo cáo kỹ thuật @nv_pavlichenko, @jetbrains. Ngách dự định đặc biệt thú vị: suy luận độ trễ cực thấp cho định tuyến, RAG (Retrieval-Augmented Generation), các tác nhân phụ và sử dụng IDE (môi trường phát triển tích hợp), và nó đã được đưa vào vLLM ngay lập tức @vllm_project. Đây có vẻ là một động thái nghiêm túc về "mô hình mở nhỏ, nhanh cho quy trình làm việc của nhà phát triển" hơn là một bản phát hành tiên phong chạy theo điểm chuẩn.
Các tác nhân, hộp cát, bộ nhớ và tìm kiếm đang trở thành bề mặt sản phẩm thực sự
Ngăn xếp đang chuyển từ các cuộc gọi mô hình sang thời gian chạy tác nhân: Một số lần ra mắt đã hội tụ ý tưởng rằng đòn bẩy kỹ thuật chính hiện nằm ở bộ điều khiển hơn là mô hình. "Search as Code" của Perplexity là ví dụ rõ ràng nhất: thay vì các cuộc gọi công cụ tìm kiếm lặp đi lặp lại, mô hình viết Python dựa trên SDK tìm kiếm, cho phép các đường ống xếp hạng tùy chỉnh, map-reduce trên các chỉ mục, phân lô, tổng hợp và chi phí token thấp hơn. Perplexity báo cáo một ju
Nguồn tin: Latent Space. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.