Đợt vé thứ hai tham dự các hội thảo AI Leadership và Engineering+Workshops của AI Engineer World's Fair đã bán hết vào tối qua. 500 vé cuối cùng hiện đang được mở bán – hãy nhanh tay sở hữu khi còn hàng! Giảm giá 20% cho 20 độc giả đầu tiên nhìn thấy thông báo này.
Hiếm khi chúng ta trực tiếp tham gia vào câu chuyện chính của ngày, và việc Apple công bố Siri tích hợp Gemini tại WWDC là một ứng cử viên tiềm năng, nhưng chúng ta đã từng bị lừa trước đây. Vì vậy, thay vào đó, chúng ta có FrontierCode, sản phẩm mới nhất trong chiến dịch War on Slop của chúng ta!
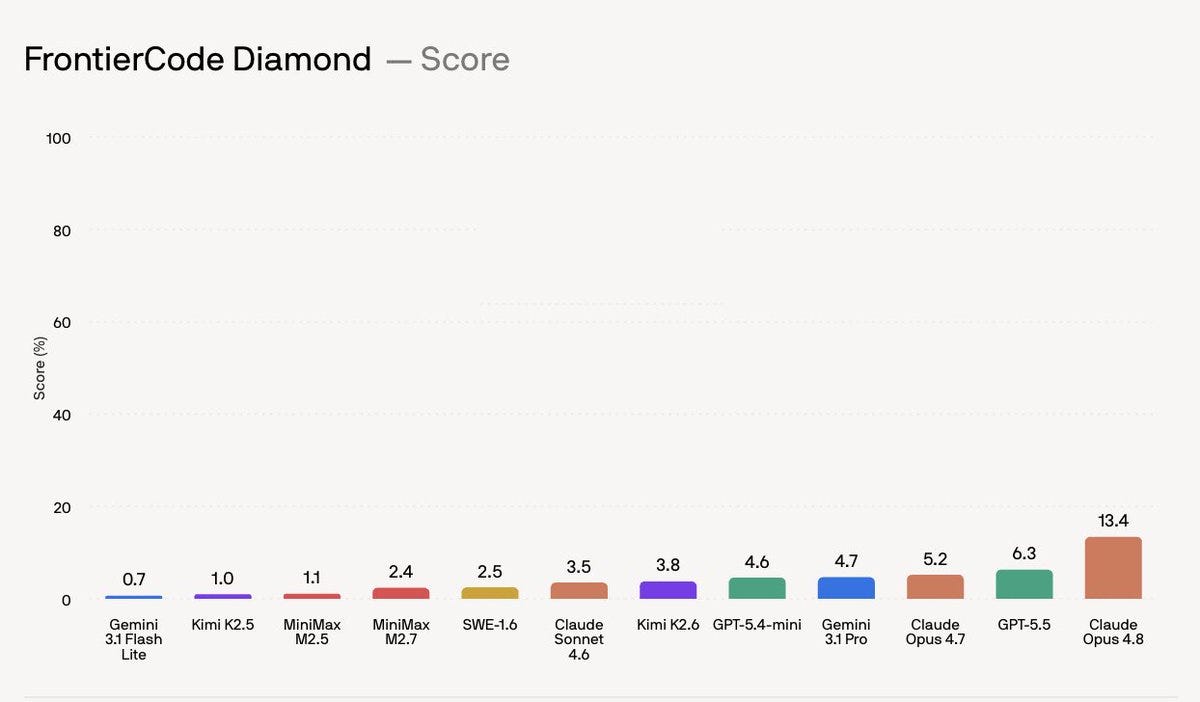
Nếu biểu đồ đó trông quen thuộc, đó là vì FrontierCode được lấy cảm hứng và đặt tên rõ ràng theo FrontierMath.
Đợt vé thứ hai cho các hội thảo AI Leadership và Engineering+Workshops của AI Engineer World’s Fair đã bán hết vào tối qua! 500 vé cuối cùng hiện đang được mở bán – hãy nhanh tay mua khi còn hàng! Giảm giá 20% cho 20 độc giả đầu tiên nhìn thấy thông báo này.
Hiếm khi chúng ta trực tiếp tham gia vào câu chuyện chính trong ngày, và việc Apple WWDC công bố Siri tích hợp Gemini là một ứng cử viên tiềm năng, nhưng chúng ta đã từng bị lừa trước đây. Vì vậy, thay vào đó, chúng ta có FrontierCode, sản phẩm mới nhất trong Chiến dịch chống lại sự cẩu thả của chúng ta!
Nếu biểu đồ đó trông quen thuộc, đó là vì FrontierCode được lấy cảm hứng và đặt tên rõ ràng theo FrontierMath – tập trung cấp độ khó nhất của nó vào các vấn đề cực kỳ khó cho các mô hình tiên tiến cách đây 2 năm:
Bối cảnh của FrontierCode xoay quanh công việc trước đây chúng ta đã thực hiện liên quan đến SWEBench-Verified.
Rõ ràng là ngay cả khi chuyển sang SWEBench Pro, vẫn chưa có sự diễn giải đầy đủ về những gì đã xảy ra vào năm 2025. Như đã thảo luận với nhóm OpenAI trong podcast đó, cần phải có nhiều công việc hơn nữa về các tiêu chí đánh giá chất lượng và khả năng bảo trì mã, và đó chính xác là những gì nhóm nghiên cứu Cog đã xây dựng trong bản phát hành FrontierCode đầu tiên này.
Riêng biệt, METR đã phát hiện ra rằng nhiều PR vượt qua SWE-bench sẽ không được hợp nhất vào Main và vấn đề về các quỹ đạo dương tính giả (không hẳn là "phần thưởng gian lận", nhưng tương tự về mặt tinh thần về độ không tin cậy của điểm chuẩn hơn là mô hình) đã được đo lường và giải quyết trực tiếp trong báo cáo FrontierCode.
Với cái nhìn sâu sắc, cấp độ vấn đề thứ ba của FrontierCode cho thấy sự tăng tốc lớn vào tháng 12/2025 đã đột ngột giúp kỹ thuật tác nhân và mã hóa cảm tính có thể nâng lên một cấp độ trừu tượng, đến các /mục tiêu và vòng lặp và siêu lời nhắc mà chúng ta đang thảo luận ngày nay.
thêm ngữ cảnh tại đây
Tin tức AI từ ngày 5/6/2026 đến 8/6/2026. Chúng tôi đã kiểm tra 12 subreddit, 544 tài khoản Twitter và không có thêm Discord nào. Trang web của AINews cho phép bạn tìm kiếm tất cả các số báo trước đây. Xin nhắc lại, AINews hiện là một phần của Latent Space. Bạn có thể chọn nhận/không nhận email theo tần suất!
Tóm tắt Twitter AI
Các tác nhân mã hóa, vòng lặp và sự chuyển đổi từ "Vượt qua các bài kiểm tra" sang phần mềm có thể hợp nhất
FrontierCode nâng cao tiêu chuẩn đánh giá mã hóa: Cognition đã giới thiệu FrontierCode, một điểm chuẩn mới nhắm mục tiêu rõ ràng vào việc liệu mã có thực sự có thể hợp nhất hay không, chứ không chỉ đơn thuần là vượt qua các bài kiểm tra đơn vị. Các nhiệm vụ được xây dựng với những người duy trì mã nguồn mở, mỗi nhiệm vụ mất hơn 40 giờ và được đánh giá theo các khía cạnh như an toàn hồi quy, độ sạch, phạm vi, độ chính xác của kiểm thử và khả năng bảo trì. Kết quả nổi bật là mô hình tốt nhất, Opus 4.8, chỉ đạt khoảng 13% trên tập hợp con khó nhất – thấp hơn nhiều so với mức 50%+ phổ biến trên các đánh giá kiểu SWE-Bench, cho thấy việc mã hóa ít "được giải quyết" hơn nhiều so với những gì các điểm chuẩn phổ biến ngụ ý (thông báo của Cognition, tóm tắt của Scott Wu, phân tích của swyx, các câu hỏi của theo về phương sai/khả năng tái tạo, phản hồi của Cognition).
"Vòng lặp" đang trở thành phép ẩn dụ kiểm soát tác nhân (agent-control metaphor) chủ đạo, nhưng đi kèm với những cảnh báo: Chủ đề thực tiễn nổi bật nhất trong ngày là các tác nhân mã hóa (coding agents) nên được cung cấp mục tiêu rõ ràng, tiêu chí xác minh và cấu trúc lặp lại thay vì các lời nhắc một lần. Các ví dụ phổ biến bao gồm "đừng sử dụng vòng lặp, hãy thiết kế máy trạng thái" của dzhng, đánh giá hồi cứu của Claude Code về chế độ tự động, các quy trình và xác minh, chuỗi bài của bcherny, các mẹo của OpenAI Codex về lời nhắc ưu tiên kết quả và mặc định "Approve-for-me", cùng với "rubrics" của LangChain OSS. Tuy nhiên, một số chuyên gia đã phản đối sự cường điệu hóa vòng lặp một cách ngây thơ: Omar Sar0 và Graham Neubig nhấn mạnh rằng các điểm kiểm tra của con người vẫn rất cần thiết bên ngoài các lĩnh vực dễ xác minh, trong khi Hamel Husain đã nói đùa về việc hoàn toàn loại bỏ từ này.
Công thái học của tác nhân đang được cải thiện xung quanh việc xác minh và điều phối: Những thay đổi về sản phẩm trên toàn bộ hệ thống phản ánh sự chuyển dịch này. ClaudeDevs đã thêm các bảng điều khiển khả năng quan sát (observability dashboards) cho các nhà phát triển trình kết nối MCP, bao gồm các chế độ xem về mức độ chấp nhận, độ trễ và lỗi. MagicPath đã ra mắt gói Builder cho các quy trình làm việc của tác nhân bên ngoài và chỉnh sửa canvas đa người dùng. LangSmith Sandboxes và câu chuyện về khả năng mở rộng sandbox của Modal cùng hướng tới xu hướng cơ sở hạ tầng tương tự: các tác nhân cần môi trường cô lập, có thể kiểm tra và chạy dài hạn.
Các mô hình sử dụng thực tế đang dần ổn định: Lời khuyên mạnh mẽ nhất của các nhà vận hành tập trung vào các kết quả có thể đo lường được, quyền tự chủ có giới hạn và vệ sinh luồng (thread hygiene). Angaisb_ cảnh báo về việc các luồng Codex quá dài làm giảm hiệu suất, trong khi reach_vb báo cáo thành công với việc tích lũy ngữ cảnh một luồng. Sự không phù hợp đó tự nó là một tín hiệu hữu ích: hiệu suất tác nhân hiện tại vẫn bị ảnh hưởng mạnh mẽ bởi hành vi của hệ thống và các lựa chọn quy trình làm việc, chứ không chỉ chất lượng mô hình cơ bản.
Phát hành mô hình, suy luận cục bộ và nâng cấp hệ thống phục vụ
Kimi đã phát hành cả một tác nhân mã hóa mạnh hơn và một sản phẩm tác nhân máy tính để bàn: Moonshot đã phát hành một bản cập nhật lớn cho Kimi Code, tác nhân mã hóa mã nguồn mở của mình, bổ sung cài đặt CLI một dòng, kéo và thả video làm ngữ cảnh mã hóa, hỗ trợ ACP, plugin và tích hợp IDE (thông báo). Công ty cũng ra mắt Kimi Work, một sản phẩm tác nhân máy tính để bàn với tối đa 300 tác nhân phụ cục bộ, sử dụng trình duyệt thông qua tiện ích mở rộng, truy cập công cụ tập trung vào tài chính và bộ nhớ liên tục (ra mắt sản phẩm, khả dụng trên máy tính để bàn).
Google đã đẩy mạnh việc triển khai cục bộ hiệu quả: Gemma đã nhận được một số nâng cấp đáng chú ý. Các điểm kiểm tra QAT Gemma 4 mới được cho là duy trì hiệu suất trong khi sử dụng bộ nhớ ít hơn khoảng 4 lần, với Gemma 4 E2B phù hợp với khoảng 1GB bằng cách sử dụng định dạng lượng tử hóa di động (@_philschmid). Riêng biệt, Gemma 4 MTP đã được hợp nhất vào llama.cpp, cho phép giải mã nhanh hơn khi kết hợp với các điểm kiểm tra QAT (nhóm Gemma). llama.cpp cũng đã thêm hỗ trợ đầu vào video, mở rộng các trường hợp sử dụng đa phương thức cục bộ.
Cạnh tranh mã nguồn mở/trọng lượng mở vẫn gay gắt: Artificial Analysis đã báo cáo MiniMax-M3 đạt 55 trên Chỉ số Thông minh của mình, điều này sẽ khiến nó trở thành mô hình trọng lượng mở hàng đầu khi các trọng lượng được phát hành. M3 bổ sung khả năng đa phương thức gốc và cửa sổ ngữ cảnh 1M token, với các con số GPQA/MMMU-Pro mạnh mẽ nhưng có sự từ chối đáng chú ý đối với các lỗi ảo giác.
Nguồn tin: Latent Space. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.