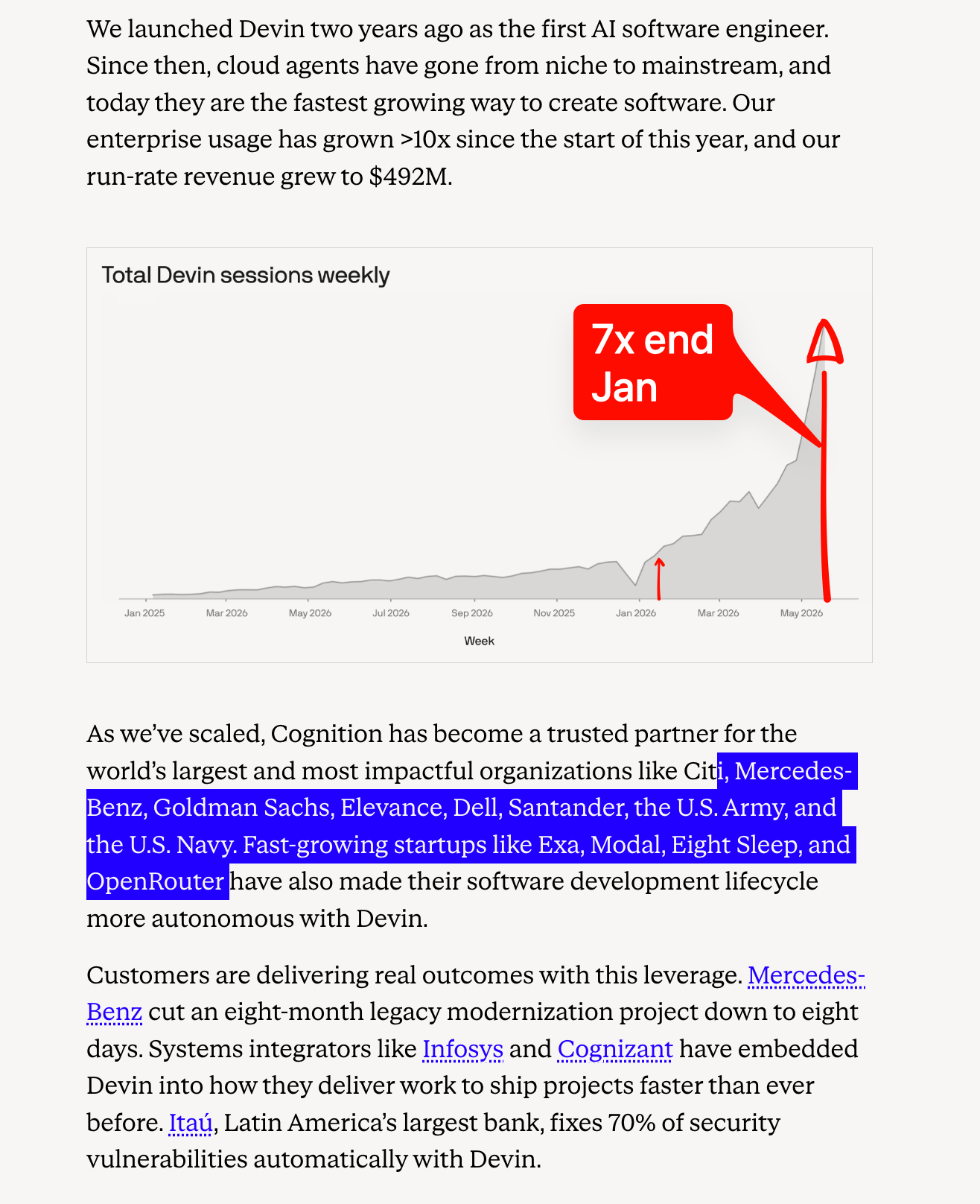
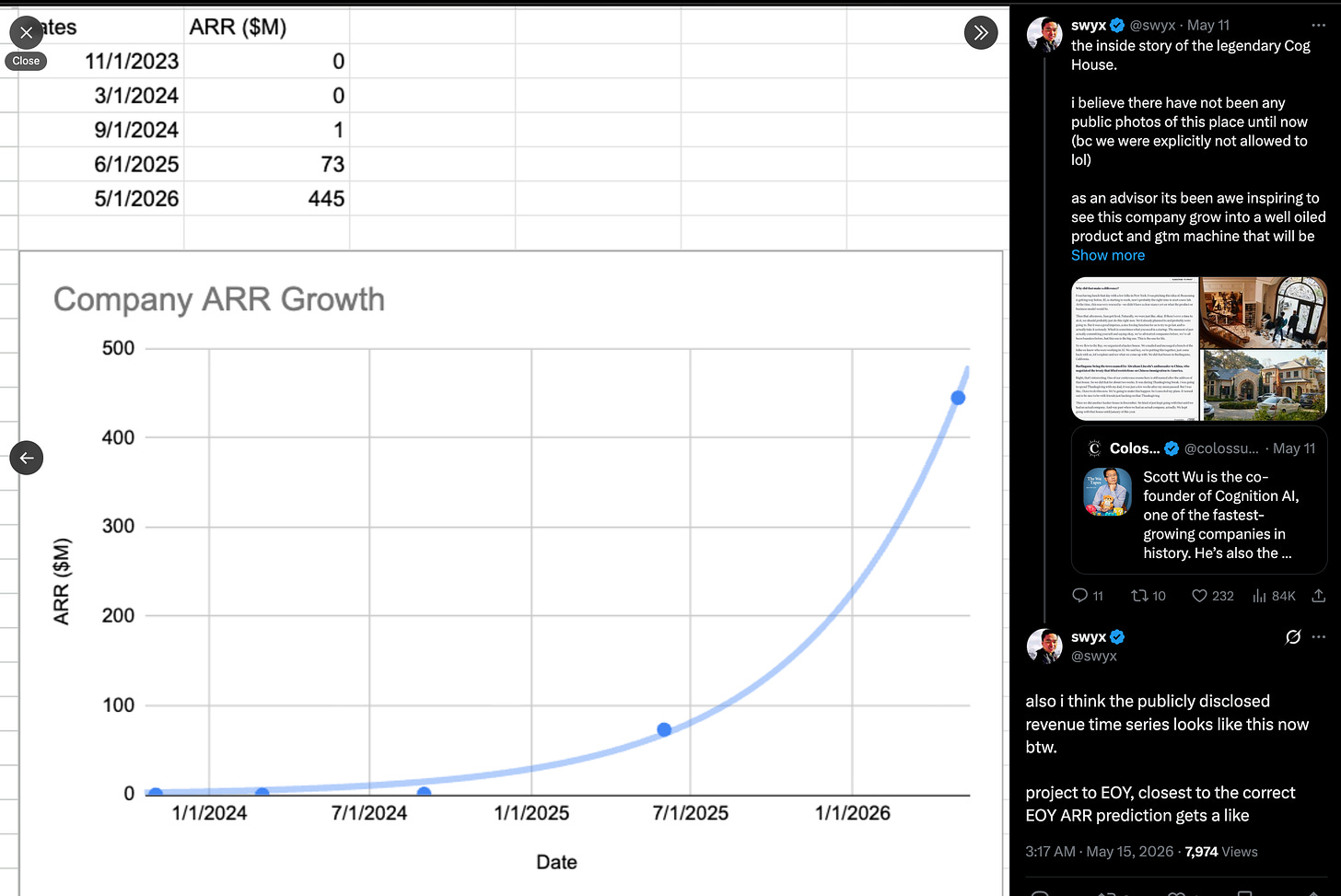
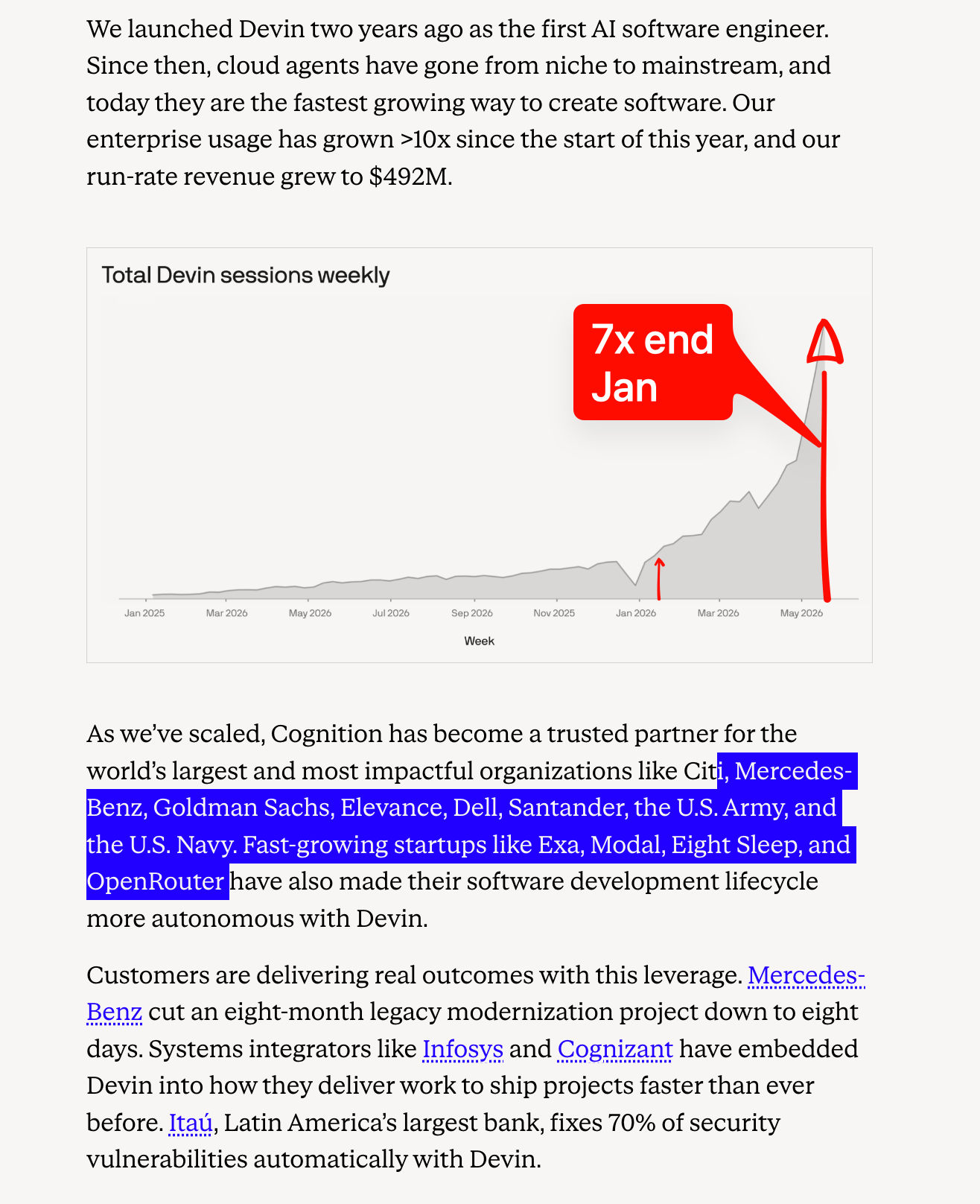
Chúng tôi đã viết về Cognition lần cuối vào tháng 9, khi công ty này huy động được 10 tỷ USD trong vòng Series C. Smol.ai cũng gia nhập Cognition vào thời điểm đó và AINews cuối cùng đã được chuyển đến Latent Space. Tám tháng sau, giá trị của Cognition đã tăng gấp 2,5 lần và chính thức trở thành phòng thí nghiệm AI độc lập lớn nhất còn lại, một luận điểm mà chúng tôi đã vạch ra vào năm ngoái. Với các công bố chính thức về Doanh thu định kỳ hàng năm (ARR) (hiện dự kiến đạt hơn 1 tỷ USD ARR vào cuối năm), có thể thấy rõ sự tăng trưởng, trông khá giống với các biểu đồ "WTF Happened in 2025" (đây không phải là sự trùng hợp ngẫu nhiên):
Trong lĩnh vực kinh doanh SaaS dành cho doanh nghiệp, ARR là một chỉ số trễ về mức độ sử dụng, tương tự như các logo của một số công ty khó tính nhất/mới nhất.
Chúng tôi đã viết về Cognition lần cuối vào tháng 9 trong đợt gọi vốn Series C trị giá 10 tỷ USD, khi Smol.ai cũng gia nhập Cognition và AINews cuối cùng đã được chuyển đến Latent Space. 8 tháng sau, giá trị của công ty đã tăng gấp 2,5 lần và chính thức trở thành phòng thí nghiệm AI độc lập lớn nhất còn lại, một luận điểm mà chúng tôi đã vạch ra vào năm ngoái. Với các công bố ARR chính thức (hiện dự kiến đạt hơn 1 tỷ USD ARR vào cuối năm), bạn có thể theo dõi sự tăng trưởng, trông giống một cách kỳ lạ với các biểu đồ "WTF Happened in 2025" (đây không phải là sự trùng hợp):
Trong lĩnh vực kinh doanh SaaS dành cho doanh nghiệp, ARR là một chỉ số trễ về mức độ sử dụng, cũng như các logo của một số khách hàng khó tính/kỹ tính nhất trong hệ sinh thái doanh nghiệp và khởi nghiệp (bao gồm Exa và Modal, được giới thiệu vào tuần trước).
Chúng tôi sẽ công bố thêm thông tin trên podcast Cognition vào ngày mai.
Tin tức AI từ ngày 26/5/2026 đến ngày 27/5/2026. Chúng tôi đã kiểm tra 12 subreddit, 544 tài khoản Twitter và không có thêm Discord nào. Trang web của AINews cho phép bạn tìm kiếm tất cả các số báo trước đây. Xin nhắc lại, AINews hiện là một phần của Latent Space. Bạn có thể chọn nhận/không nhận email thường xuyên!
Tổng hợp tin tức AI trên Twitter
Hiệu quả suy luận, kiến trúc phục vụ và đường cong chi phí
Tối ưu hóa suy luận ngày càng mang tính kiến trúc, không chỉ ở cấp độ kernel: EAGLE 3.1 cải thiện độ bền giải mã suy đoán bằng cách ổn định phản hồi trạng thái ẩn và giảm trôi sự chú ý ở các bước giải mã sâu hơn, với sự nhấn mạnh rõ ràng vào độ dài chấp nhận ngữ cảnh dài và độ tin cậy phục vụ trong thế giới thực; nhóm cũng nhấn mạnh sự hợp tác với vLLM và TorchSpec. Ở lớp kernel/hệ thống, Perplexity đã công bố mã nguồn mở một bộ mã hóa Unigram được xây dựng lại giúp giảm mức sử dụng CPU 5-6 lần và đạt 63 µs ở 514 token mà không cần cấp phát heap, trong khi Qwen3.5 trên TokenSpeed được cho là đạt 580 token/giây cho các tác vụ tác nhân thông qua tối ưu hóa chung giữa Alibaba, LightSeek, NVIDIA, Mooncake và những người đóng góp FlashAttention-4. Các thư viện hỗ trợ cũng được cải thiện: MaxSim v2 bổ sung backprop và báo cáo nhanh hơn 10,33 lần trên H200 và 11,94 lần trên A100 so với PyTorch thông thường.
Việc giảm giá đang được biện minh bằng những thay đổi cấu trúc KV-cache và sự chú ý: Một số bài đăng cùng hướng đến một chủ đề: việc giảm giá API gần đây từ các phòng thí nghiệm Trung Quốc có vẻ bền vững vì chúng phản ánh chi phí phục vụ thấp hơn trên mỗi token, không phải là trợ cấp tạm thời. @kimmonismus đã tóm tắt cách DeepSeek V4-Pro sử dụng sự chú ý lai với Compressed Sparse Attention và Heavily Compressed Attention để đưa KV cache 1M-token xuống khoảng 10% so với V3.2 và FLOPs suy luận một token xuống 27%, trong khi vẫn định tuyến 49 tỷ tham số hoạt động trong tổng số 1,6 nghìn tỷ. MiMo của Xiaomi cũng giảm lưu lượng truy cập bộ nhớ cache bằng cách sử dụng SWA cộng với quản lý bộ nhớ cache phân cấp. Điều này đã được @_LuoFuli xác nhận trực tiếp, người đã nói rằng việc giảm giá sâu nhất của MiMo đối với bộ nhớ cache đầu vào đến từ dung lượng token được lưu trong bộ nhớ cache gấp 5 lần, chi phí lưu trữ thấp hơn khoảng 80% và tỷ lệ thưa thớt kiến trúc 1:7 Full:SWA. Bài học rộng hơn: kinh tế suy luận ngữ cảnh dài hiện đang được thúc đẩy bởi thiết kế sự chú ý + phân cấp bộ nhớ cache + định tuyến, không chỉ phần cứng rẻ hơn.
Tác nhân, Khai thác, Bộ nhớ và Học liên tục
Ngăn xếp đang chuyển từ "chất lượng mô hình" sang "sự phù hợp giữa mô hình-khai thác-bộ nhớ": Một nhóm đáng kể các tweet tập trung vào kỹ thuật tác nhân thực tế. LangChain đã phát hành Deep Agents v0.6 với Delta Channels, giảm dung lượng lưu trữ điểm kiểm tra cho một phiên mã hóa 200 lượt từ 5,3 GB xuống 129 MB, đồng thời ra mắt tính năng sử dụng máy tính trong Fleet, cùng với Context Hub cho ngữ cảnh/kỹ năng tác nhân được phiên bản hóa. LangSmith Engine được định hình là tự động hóa vòng lặp đánh giá → chẩn đoán → sửa lỗi, với nhiều chuyên gia nhấn mạnh giá trị của nó trong việc biến phản hồi theo dõi thành các công cụ đánh giá trực tuyến/ngoại tuyến có thể tái sử dụng. Song song đó, @Vtrivedy10 đã đưa ra công thức rõ ràng nhất trong ngày: sự phù hợp giữa nhiệm vụ và khai thác quan trọng như chất lượng mô hình, và các hệ thống chuyên biệt vượt trội hơn các khai thác chung bằng cách thu hẹp công cụ, lời nhắc và ngữ cảnh cho nhiệm vụ.
Học liên tục đang nổi lên trở lại như một danh mục sản phẩm, không chỉ là một chủ đề nghiên cứu: Thông báo lớn nhất ở đây là sự ra mắt của Trajectory: một nền tảng để sử dụng tín hiệu sử dụng sản phẩm và dấu vết tác nhân để liên tục huấn luyện sau các mô hình tác nhân lớn, với 15 triệu USD tài trợ và các đối tác thiết kế bao gồm Clay, Harvey, Decagon, Mercor và Rogo. Baseten cho biết họ hỗ trợ các triển khai này bằng lượng tử hóa FP8/NVFP4 và cơ sở hạ tầng H100 tự động mở rộng quy mô, bao gồm một triển khai qua đêm được trích dẫn của một mô hình 397 tỷ tham số. Xu hướng tương tự xuất hiện trong các công cụ mã nguồn mở: một tác nhân tập trung vào bộ nhớ mã nguồn mở được xây dựng trên LangChain/LangGraph đã được nhiều nhà phát triển ca ngợi vì sự tách biệt rõ ràng giữa truy xuất/lưu trữ/lý luận/học tập, và công cụ huấn luyện tối thiểu của RLM cho thấy các nhóm nhỏ hiện có thể điều chỉnh RL các tác nhân ngữ cảnh dài trong một ngày trên 8×A100. Điểm chung là "học sau triển khai" đang chuyển từ khát vọng thành cơ sở hạ tầng.
Điểm chuẩn, Quy luật mở rộng quy mô và Phương pháp huấn luyện
Các điểm chuẩn mới ngày càng tập trung vào các quy trình làm việc dài hạn, phức tạp, trong thế giới thực: DeepSWE được nhấn mạnh là một điểm chuẩn SWE/tác nhân với 113 nhiệm vụ trên 91 kho lưu trữ trong 5 ngôn ngữ, sử dụng một công cụ khai thác chỉ dùng bash tối giản và các lời nhắc ngắn hơn nhưng yêu cầu mã nhiều hơn 5,5 lần và chạm vào trung bình 7 tệp so với SWE-Bench Pro. Trong các hoạt động doanh nghiệp, Artificial Analysis và IBM đã ra mắt ITBench-AA, một điểm chuẩn SRE về phản ứng sự cố Kubernetes, nơi tất cả các mô hình tiên tiến đều đạt dưới 50%; Claude Opus 4.7 dẫn đầu ở mức 47%, GPT-5.5 theo sau ở mức 46% và GLM-5.1 Reasoning dẫn đầu các trọng số mở ở mức 40%. Một góc độ đáng tin cậy hữu ích khác đến từ AgingBench, định nghĩa sự suy giảm của tác nhân được triển khai là một vấn đề tuổi thọ do nén, nhiễu và cập nhật bộ nhớ.
Nghiên cứu hiệu quả huấn luyện vẫn hoạt động tích cực trên cả lý thuyết và hệ thống: DiffusionBlocks của Sakana AI là một trong những bản phát hành thú vị nhất về mặt kỹ thuật: nó diễn giải lại các bước chuyển tiếp dưới dạng các bước khử nhiễu giống như khuếch tán để các mạng sâu có thể được huấn luyện từng khối một, giảm đáng kể bộ nhớ trong khi vẫn đạt được hiệu suất đầu cuối trên ViTs, DiTs, masked.
Nguồn tin: Latent Space. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.