[AINews] Codex Rises, Claude Meters sử dụng theo chương trình
Đó là câu chuyện về hai thành phố trong 3 tuần qua kể từ khi GPT 5.5 ra mắt; trong khi giới tài chính yêu thích sự tăng trưởng và giám đốc tài chính của Anthropic trước đợt IPO vào tháng 10, thì đã có sự gia tăng đáng chú ý về thái độ ủng hộ Codex giữa các Kỹ sư AI, có thể là sự kết hợp giữa GPT 5.5 là một mô hình thực sự tốt (trong một số trường hợp là cấp Mythos), ra mắt Codex cho mọi thứ khác và điều thứ ba là yếu tố kích hoạt cho op-ed ngày nay: các giới hạn hào phóng hơn. Thông điệp về việc thay đổi giá của Claude nhìn chung được thực hiện khá tốt, nó đơn giản không phải là cách sử dụng giải pháp thay thế.
Đó là câu chuyện về hai thành phố trong 3 tuần qua kể từ khi GPT 5.5 ra mắt; trong khi giới tài chính yêu thích sự tăng trưởng và giám đốc tài chính của Anthropic trước đợt IPO vào tháng 10, thì đã có sự gia tăng đáng chú ý về thái độ ủng hộ Codex giữa các Kỹ sư AI, có thể là sự kết hợp giữa GPT 5.5 là một mô hình thực sự tốt (trong một số trường hợp là cấp Mythos), ra mắt Codex cho mọi thứ khác và điều thứ ba là yếu tố kích hoạt cho op-ed ngày nay: các giới hạn hào phóng hơn.
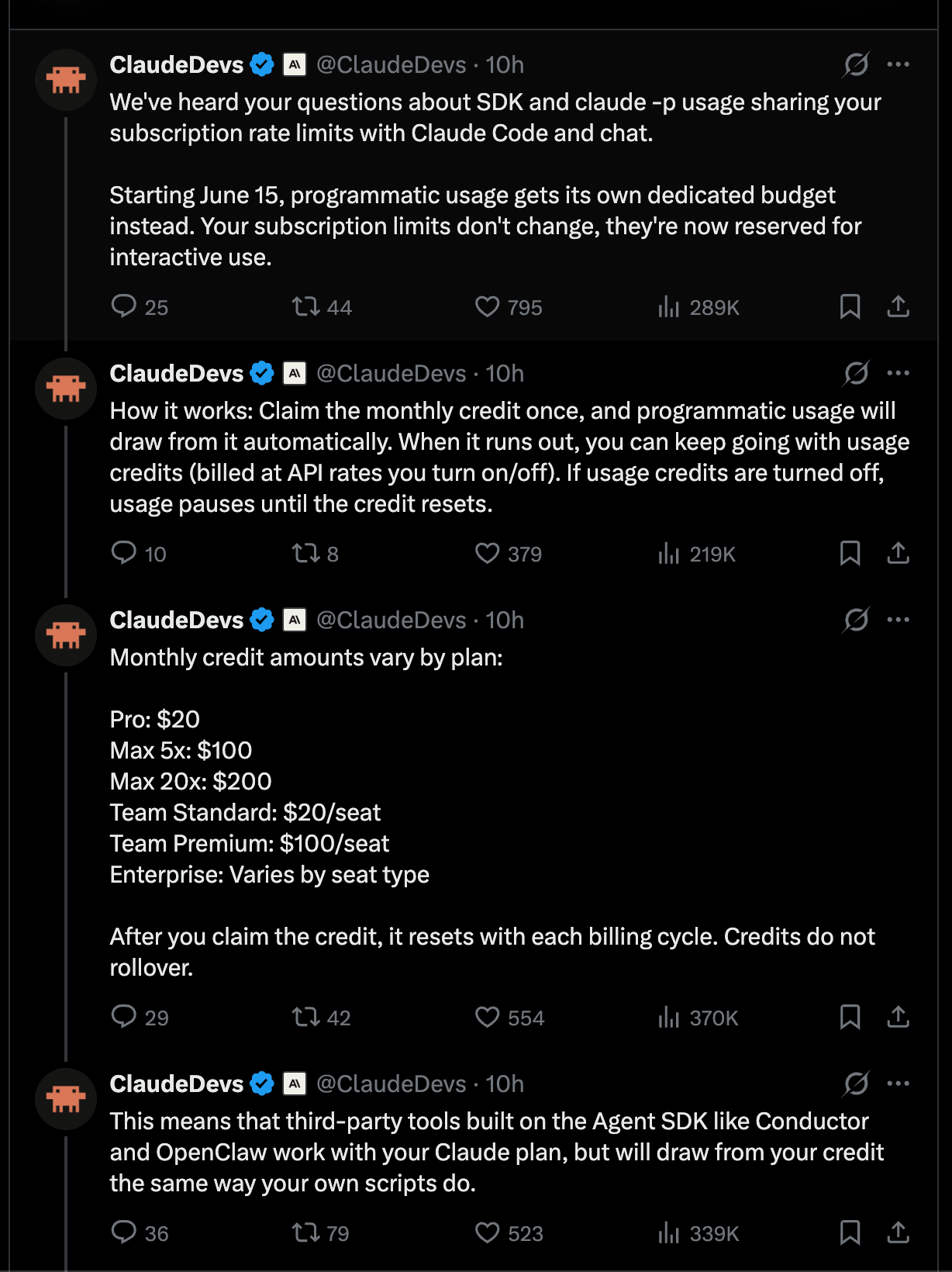
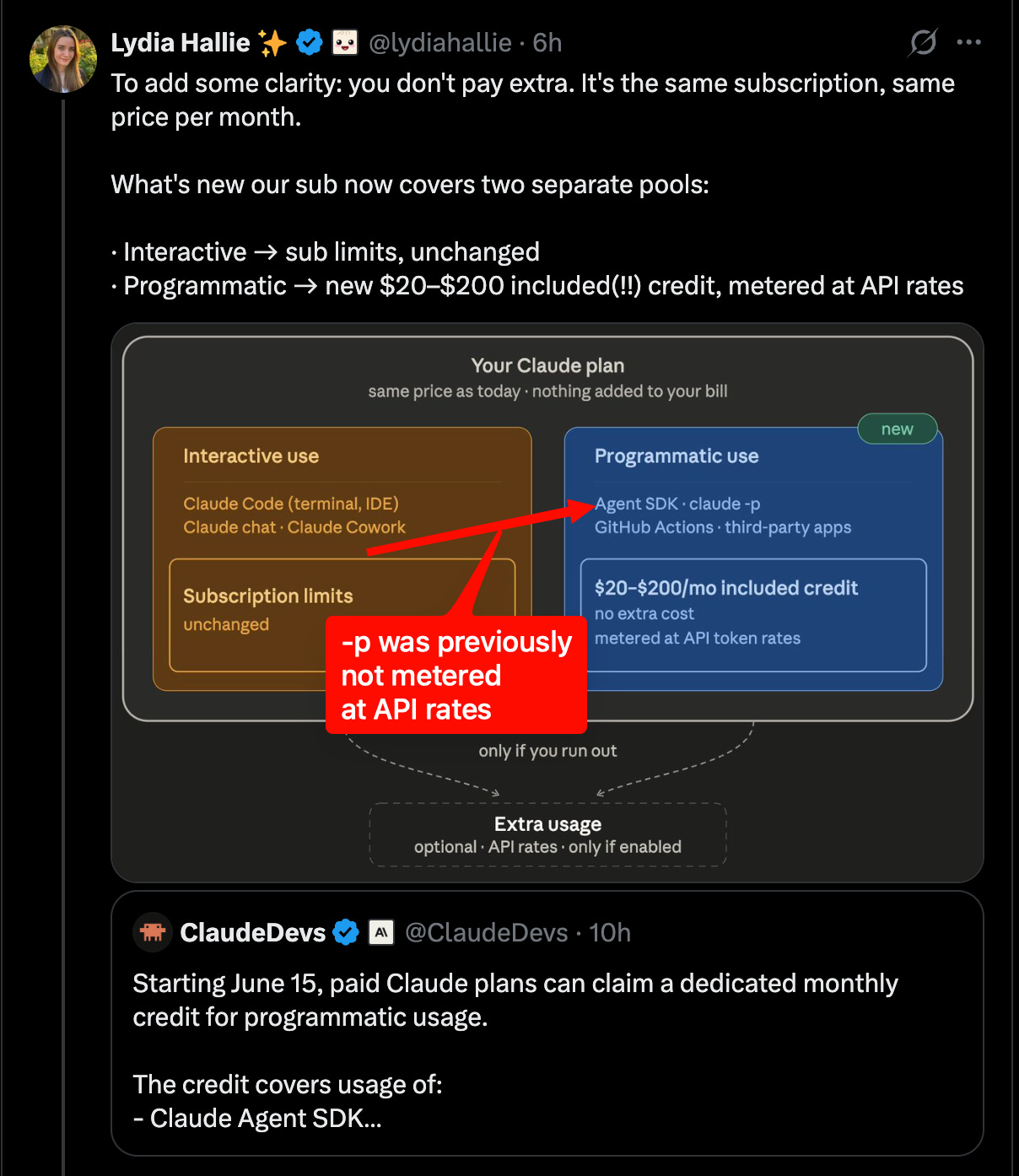
Thông điệp về việc thay đổi giá của Claude nhìn chung được thực hiện khá tốt, đơn giản đó không phải là điều mà việc sử dụng các bộ khai thác thay thế muốn nghe: mỗi đăng ký Claude hiện nhận được khoản tín dụng hàng tháng là mã thông báo API bằng với số tiền của gói đăng ký Claude. Vì vậy, bạn trả 200 đô la, bạn nhận được CẢ HAI đăng ký Claude với các giới hạn riêng để sử dụng Claude trên các khai thác thuộc sở hữu của Anthropic như Claude.ai và Claude Code (“cách sử dụng tương tác”), VÀ khoản tín dụng API trị giá 200 đô la để sử dụng Claude ở mọi nơi khác bao gồm claude-p, OpenClaw và những thứ khác (“cách sử dụng theo chương trình”).
Nếu mọi việc diễn ra theo cách này ngay từ đầu thì nó sẽ được coi là một thương vụ rất tốt:
Tuy nhiên, do lợi thế về trợ giá/giá cả trong lịch sử (ước tính giảm từ 70-90% so với giá API), mọi người đang xem nó như một loại “thảm kéo” - tuy nhiên, thật tuyệt khi có một chính sách chính thức thay vì nhắm mục tiêu có chọn lọc của OpenClaw, OpenCode và trạng thái không chắc chắn của các loại khai thác ít phổ biến hơn.
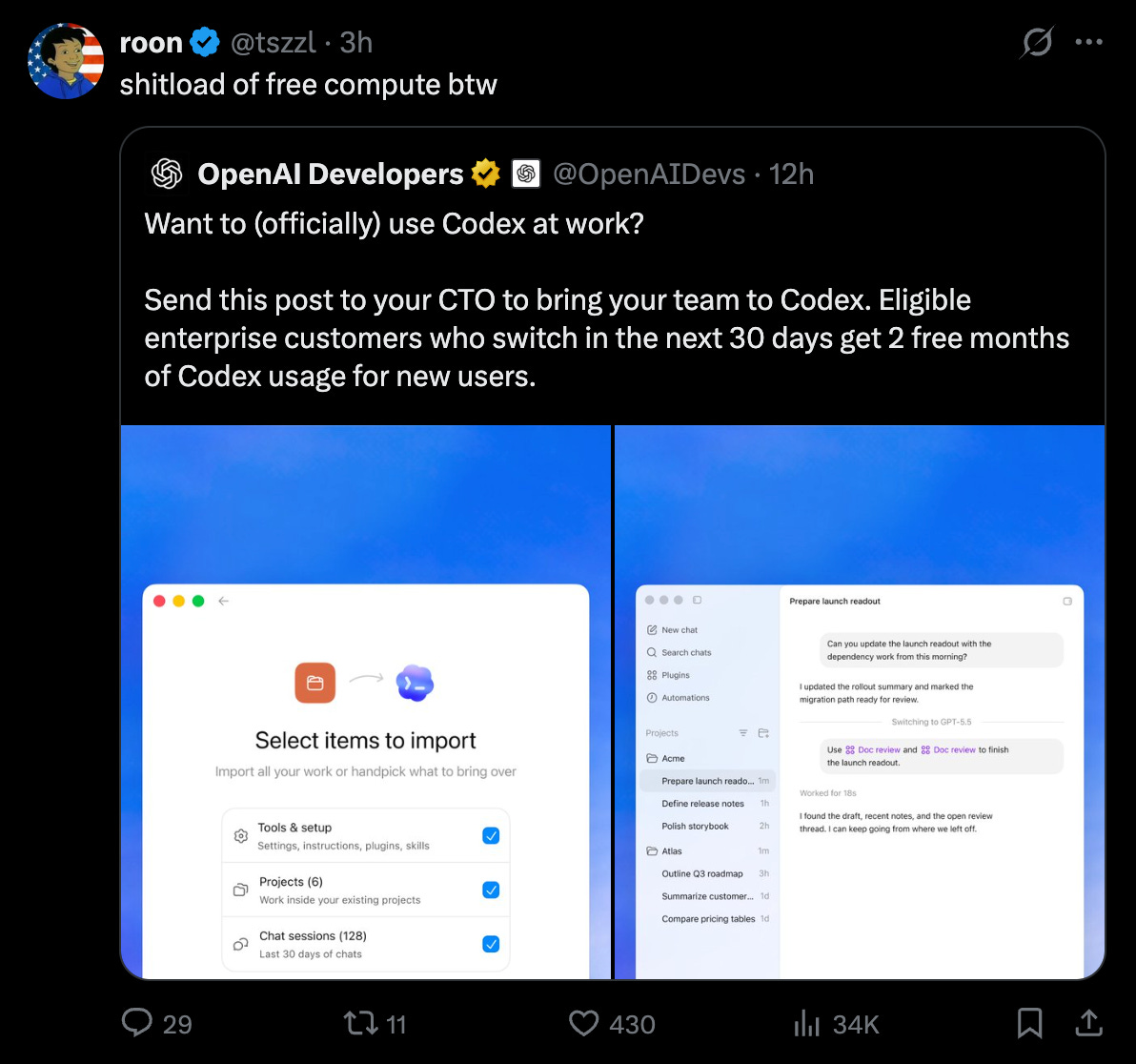
Việc những tiêu đề này xuất hiện cùng ngày khi OpenAI triển khai chương trình khuyến mãi chuyển đổi doanh nghiệp của họ là một sự trùng hợp đáng kinh ngạc:
Vào cuối ngày, chúng tôi sẽ thận trọng không nên đọc quá nhiều về biến động - cả hai phòng thí nghiệm đều đang hoạt động rất tốt và đây là một kế hoạch tổng thể về những thay đổi về giá cả thông thường do những người phát minh ra tương lai của mã hóa đồng thời tìm ra mức giá tối ưu khi họ làm rung chuyển một ngành công nghiệp đã tồn tại hàng thập kỷ. Anthropic ban đầu tự do hơn, nhưng giờ đây, Claude Code đã có thương hiệu bền vững và có tầm ảnh hưởng như một đại lý khai thác, Anthropic đang đưa ra mức giá có lợi nhất cho các công cụ của riêng mình và đo lường mọi thứ khác, trong khi Codex với tư cách là kẻ thách thức đang tự do hơn với mọi thứ.
Có lẽ phần cứng là định mệnh, có lẽ đây là một phần của chu kỳ xen kẽ dài hơn 6 tháng của “điểm phân nhiệm vụ”:
Bản tin AI ngày 12/5/2026-13/5/2026. Chúng tôi đã kiểm tra 12 subreddits, 544 Twitter và không có Discord nào nữa. Trang web của AINews cho phép bạn tìm kiếm tất cả các số báo trước đây. Xin nhắc lại, AINews hiện là một phần của Không gian tiềm ẩn. Bạn có thể chọn tham gia/không tham gia tần suất email!
Tóm tắt Twitter của AI
Cơ sở hạ tầng đại lý, khai thác và nền tảng dành cho nhà phát triển
Cline, LangChain, Notion và Cursor đều tiến sâu hơn vào lãnh thổ nền tảng đại lý: Cline đã mở mã nguồn cho Cline SDK được xây dựng lại và làm mới CLI với TUI, nhóm đại lý, công việc đã lên lịch và trình kết nối, định vị khai thác của nó như một chất nền có thể tái sử dụng cho các tác nhân mã hóa tùy chỉnh. LangChain đã vận chuyển một lượng lớn cơ sở hạ tầng vòng đời đại lý tại Interrupt: LangSmith Engine, SmithDB, Sandboxes, Managed Deep Agent, LLM Gateway, Context Hub và Deep Agents 0.6. Phần đáng chú ý nhất về mặt kỹ thuật là SmithDB, một cơ sở dữ liệu có khả năng quan sát được xây dựng có mục đích dành cho các dấu vết lồng nhau, chạy dài với tải trọng lớn, được cho là mang lại khả năng truy cập nhanh hơn 12–15× đối với khối lượng công việc chính; nhóm cho biết nó được xây dựng trên Apache DataFusion và Vortex. Song song, API tác nhân bên ngoài của Notion cho phép các tác nhân bên thứ ba như Claude, Codex, Cursor, Decagon, Warp và Devin hoạt động trực tiếp bên trong Notion dưới dạng lớp ngữ cảnh được chia sẻ, có thể xem lại thay vì một silo khác. Con trỏ đã mở rộng các tác nhân đám mây với môi trường phát triển được cấu hình đầy đủ bao gồm các kho lưu trữ nhân bản, phần phụ thuộc, lịch sử phiên bản, khôi phục, đầu ra có phạm vi và các bí mật riêng biệt.
Tác nhân UX ngày càng thiên về trạng thái hoạt động lâu dài, phát trực tuyến và điều phối hơn là trò chuyện: Một số lần ra mắt đã hội tụ theo cùng một hướng thiết kế. Duet Agent đề xuất khai thác máy trạng thái cho các công việc kéo dài hàng tuần hoặc hàng tháng, với sự phối hợp giữa tác nhân chính/tác nhân phụ và bộ nhớ thay thế việc nén. Các bản cập nhật OSS của LangChain đã bổ sung các phép chiếu được gõ trực tuyến, lưu trữ điểm kiểm tra, trình thông dịch mã, hồ sơ khai thác và điều chỉnh theo mô hình cụ thể, tất cả đều nhằm mục đích tạo ra các luồng sự kiện đại lý phong phú hơn so với các mã thông báo đơn giản. Tabracadabra đã chuyển từ tính năng tự động hoàn thành sang trợ lý nhận biết ngữ cảnh trong bất kỳ hộp văn bản nào, trong khi VS Code giới thiệu cửa sổ Đại lý và khả năng đánh giá nhiệm vụ nhiều dự án tốt hơn. Thông điệp mang tính kiến trúc trong các bản phát hành này là các tác nhân sản xuất ngày càng cần khả năng thực thi bền bỉ, trạng thái trung gian có thể kiểm tra và các bề mặt giao diện người dùng gốc của công cụ thay vì các vòng lặp nhắc/phản hồi không trạng thái.
Đào tạo mô hình, kiến trúc và hiệu quả dữ liệu
Hiệu quả đào tạo trước và thử nghiệm kiến trúc là nội dung nghiên cứu mạnh mẽ nhất: Đào tạo chồng chất mã thông báo của Nous Research sửa đổi giai đoạn đầu của quá trình đào tạo trước để mô hình đọc/dự đoán các túi mã thông báo liền kề trước khi hoàn nguyên về dự đoán mã thông báo tiếp theo tiêu chuẩn; họ báo cáo tốc độ tăng tốc đồng hồ treo tường 2–3× ở các FLOP phù hợp mà không có thay đổi về kiến trúc thời gian suy luận, được xác thực từ mật độ dày đặc 270M đến 3B và 10B-A1B MoE. Jonas Geiping và cộng sự. lập luận rằng hoạt động đào tạo dựa trên tin nhắn/trò chuyện hiện tại hạn chế quá mức các tác nhân trong một luồng duy nhất và phát hành một bài báo LLM đa luồng tuyên bố độ trễ thấp hơn, phân tách các mối quan tâm rõ ràng hơn và sử dụng công cụ/lý luận song song dễ đọc hơn; giấy và mã được liên kết ở đây. δ-mem đã đề xuất một bộ nhớ liên kết trực tuyến bên ngoài được gắn vào một xương sống tập trung hoàn toàn cố định, với trạng thái 8×8 được báo cáo là cải thiện điểm trung bình lên 1,10× và đánh bại các đường cơ sở không phải-δ-mem lên 1,15×, với mức tăng lớn hơn trên các điểm chuẩn nặng về bộ nhớ.
Quá trình đào tạo/nén và quản lý dữ liệu cũng mang lại kết quả đáng chú ý: Star Elastic của NVIDIA tuyên bố rằng một lần chạy sau đào tạo có thể tạo ra một nhóm kích thước mô hình lý luận, với chi phí thấp hơn 360 lần so với đào tạo trước một gia đình
Nguồn tin: Latent Space. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.