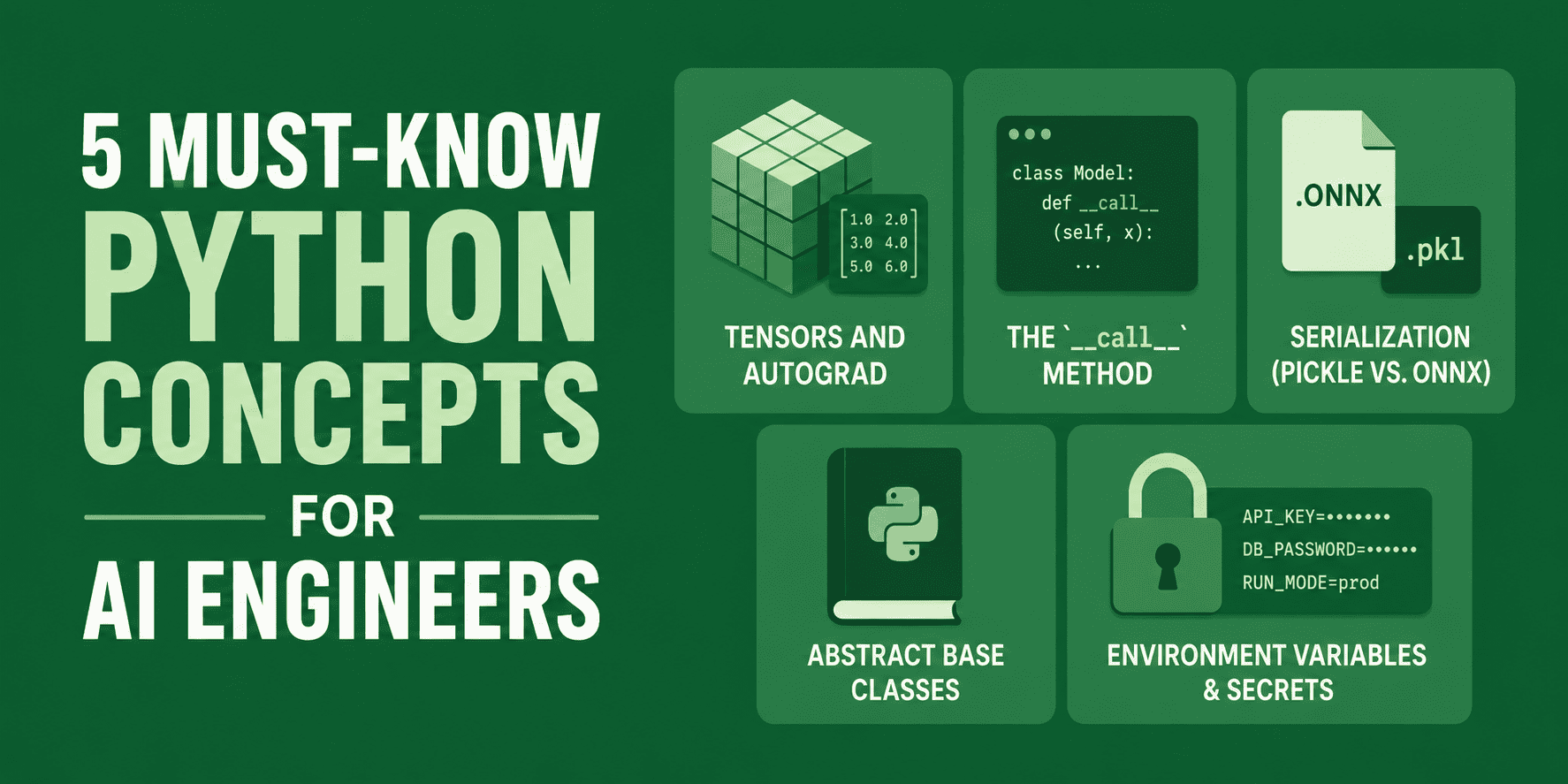
5 khái niệm Python kỹ sư AI cần nắm vững
Trong bài viết này, chúng ta sẽ tìm hiểu năm khái niệm Python quan trọng mà mọi kỹ sư AI cần nắm vững để xây dựng các hệ thống có khả năng mở rộng, bảo mật và mạnh mẽ.
5 Khái niệm Python cần biết đối với Kỹ sư AI - KDnuggets
Blog
Bài viết hàng đầu
Giới thiệu
Chủ đề
AI
Lời khuyên nghề nghiệp
Thị giác máy tính
Kỹ thuật dữ liệu
Khoa học dữ liệu
Mô hình ngôn ngữ
Học máy
MLOps
NLP
Lập trình
Python
SQL
Tập dữ liệu
Sự kiện
Tài nguyên
Tài liệu tham khảo nhanh
Đề xuất
Tóm tắt công nghệ
Quảng cáo
Tham gia Bản tin
5 Khái niệm Python cần biết đối với Kỹ sư AI
Trong bài viết này, chúng ta sẽ khám phá năm khái niệm Python quan trọng mà mọi kỹ sư AI cần biết để xây dựng các hệ thống có khả năng mở rộng, an toàn và mạnh mẽ.
Bởi Matthew Mayo, Biên tập viên quản lý của KDnuggets vào ngày 8/6/2026 trong Python
# Giới thiệu
Vai trò của kỹ sư AI hiện đã tách biệt rõ ràng khỏi khoa học dữ liệu truyền thống. Nếu bạn quan tâm đến chức danh công việc này, việc chỉ biết cách huấn luyện một mô hình là không đủ; bạn phải biết cách các framework học sâu hoạt động bên trong, cách thiết kế các pipeline mô-đun và mạnh mẽ, cũng như cách tuần tự hóa và triển khai mô hình một cách an toàn ở quy mô lớn. Và bạn biết không? Python đóng vai trò trung tâm trong kỹ thuật AI giống như vai trò lịch sử của nó – và hiện tại! – trong khoa học dữ liệu.
Để xây dựng các ứng dụng AI cấp độ sản xuất và kiến trúc học sâu, bạn cần nắm vững các khái niệm Python cơ bản mà các phương pháp tiếp cận hiện đại dựa vào. Trong bài viết này, chúng ta sẽ khám phá năm khái niệm Python quan trọng, từ cơ chế đồ thị tính toán của PyTorch đến cấu hình môi trường an toàn, mà mọi kỹ sư AI cần biết để xây dựng các hệ thống có khả năng mở rộng, an toàn và mạnh mẽ.
# 1. Tensors và Autograd
Học sâu về cơ bản là tối ưu hóa trọng số thông qua thuật toán gradient descent, đòi hỏi phải tính toán các đạo hàm riêng, hay gradient, trên các đồ thị tính toán phức tạp. Mặc dù bạn có thể tự viết các phương trình backpropagation cho một mạng đơn giản, nhưng việc làm như vậy cho các kiến trúc với hàng triệu tham số là không khả thi về mặt toán học và tính toán.
Các framework học sâu hiện đại như PyTorch và TensorFlow tự động hóa điều này thông qua autograd, hay đạo hàm tự động. Khi một tensor được khởi tạo với requires_grad=True, PyTorch sẽ tự động theo dõi tất cả các phép toán được thực hiện trên nó để xây dựng một đồ thị tuần hoàn có hướng (DAG) của các phép tính. Gọi .backward() trên một hàm mất mát vô hướng sẽ duyệt DAG này theo chiều ngược lại, tự động áp dụng quy tắc chuỗi để tính toán gradient.
// Cách thủ công
Giả sử chúng ta muốn tính toán gradient của một hàm mất mát đơn giản $L = (wx + b - y)^2$ đối với trọng số $w$ và độ lệch $b$. Việc tính toán thủ công này dài dòng, cứng nhắc và dễ mắc lỗi đạo hàm phân tích:
# Đầu vào và mục tiêu
x, y = 2.0, 5.0
# Trọng số và độ lệch ban đầu
w, b = 0.5, 0.1
# 1. Truyền xuôi (Forward pass)
pred = w * x + b
loss = (pred - y) ** 2
# 2. Backpropagation thủ công (tính toán đạo hàm riêng một cách phân tích)
# dLoss/dpred = 2 * (pred - y)
# dpred/dw = x
# dpred/db = 1
dloss_dpred = 2 * (pred - y)
dw = dloss_dpred * x
db = dloss_dpred * 1
print(f"Gradient thủ công -> dw: {dw:.4f}, db: {db:.4f}")
// Cách Pythonic
Đây là tiêu chuẩn sản xuất. Bằng cách khai báo các tensor với requires_grad=True, chúng ta cho phép PyTorch xây dựng đồ thị tính toán và tự động tính toán các đạo hàm toán học chính xác:
import torch
# Đầu vào và mục tiêu
x = torch.tensor(2.0)
y = torch.tensor(5.0)
# PyTorch theo dõi các phép toán trên các trọng số này để tính toán đạo hàm
w = torch.tensor(0.5, requires_grad=True)
b = torch.tensor(0.1, requires_grad=True)
# 1. Truyền xuôi (Forward pass)
pred = w * x + b
loss = (pred - y) ** 2
# 2. Lan truyền ngược tự động (Automated backpropagation)
loss.backward()
# Truy cập các gradient đã tính toán trực tiếp từ các thuộc tính của tensor
print(f"Autograd Gradients -> dw: {w.grad.item():.4f}, db: {b.grad.item():.4f}")
Output:
Manual Gradients -> dw: -15.6000, db: -7.8000
Autograd Gradients -> dw: -15.6000, db: -7.8000
Autograd tự động theo dõi mọi nút toán học (như phép cộng hoặc phép lũy thừa) dưới dạng một đối tượng C++. Việc tạo đồ thị động này cho phép PyTorch dễ dàng xử lý các tính năng kiến trúc phức tạp như vòng lặp động, thực thi có điều kiện và mạng đệ quy, trừu tượng hóa sự phức tạp toán học của quá trình lan truyền ngược (backpropagation).
# 2. Phương thức __call__
Nếu kiểm tra kiến trúc mô hình PyTorch, có thể nhận thấy rằng các lớp và mô hình không bao giờ được gọi bằng cách gọi rõ ràng một phương thức .forward() hoặc .compute(). Thay vào đó, các thể hiện của mô hình và lớp được xử lý như các hàm Python tiêu chuẩn và được gọi trực tiếp, ví dụ: model(inputs).
Cú pháp rõ ràng này được thực hiện nhờ phương thức dunder __call__ của Python. Việc triển khai __call__ bên trong một lớp cho phép các thể hiện của nó hoạt động như các hàm có thể gọi được. Điều quan trọng là nn.Module cơ sở của PyTorch triển khai __call__ để thực thi thiết lập cấp hệ thống (chẳng hạn như đăng ký và thực thi các hook trước và sau truyền xuôi) trước khi thực thi logic forward() do người dùng định nghĩa.
// Cách làm rườm rà
Việc tạo các cấu hình lớp tùy chỉnh mà khách hàng phải gọi rõ ràng các tên phương thức cụ thể sẽ hạn chế khả năng kết hợp và phá vỡ tính tương thích với các quy trình học sâu tiêu chuẩn.
class CustomLinearLayer:
def __init__(self, weight: float, bias: float):
self.weight = weight
self.bias = bias
def compute_forward_pass(self, x: float) -> float:
# Phương thức thực thi cứng nhắc, được đặt tên rõ ràng
return x * self.weight + self.bias
# Khởi tạo và thực thi
layer = CustomLinearLayer(weight=0.5, bias=0.1)
output = layer.compute_forward_pass(2.0)
print(f"Output: {output}")
// Cách làm theo chuẩn Python
Bằng cách triển khai phương thức __call__, chúng ta cho phép các thể hiện lớp của mình được gọi trực tiếp. Chúng ta cũng có thể mô phỏng cách các framework như PyTorch thực thi các hook quy trình phụ trợ một cách liền mạch.
class PythonicLinearLayer:
def __init__(self, weight: float, bias: float):
self.weight = weight
self.bias = b



Nguồn tin: KDnuggets — Tác giả: Matthew Mayo. Bản dịch tiếng Việt do AI thực hiện, có thể có sai sót.